
Latence Ampere GA102 / RDNA2 Navi 21 otestovány

V kontextu procesorů i grafických karet se v posledních letech čím dál častěji hovoří o cache. Ač jsou důvody v obou případech odlišné, cache jako taková má na výkon čím dál podstatnější vliv…
Ve světě procesorů vidíme důsledky vlivu cache na výkon čím dál častěji. Zvlášť výrazná mediální pozornost byla věnována nástupu architektury Zen+, která oproti Zen (1) snižovala především latence cache, což mělo v průměru asi 3% vliv na IPC; ve hrách však výrazně vyšší. Znovu jsme se u cache zastavili v kontextu architektury Zen 3, která sloučila L3 cache na úrovni čipletu a dále APU Cezanne, které snižovalo latence cache oproti předchozí generaci. Zatímco v kontextu procesorů a jejich cache byla ve všech případech řeč o latenci, v kontextu grafických čipů je situace jiná.
Přestože stejně jako u procesorů existuje v grafických jádrech nějaká L1 cache a L2 cache a situace se tedy může jevit podobná, jsou důvody přítomnosti těchto cache odlišné než u procesorů. Zatímco procesory jsou citlivé zejména na latence, tedy prodlevy mezi vyžádáním a doručením dat, grafické čipy umějí latence tzv. skrývat (což je dáno delší pipeline a dlouholetým vývojem grafických architektur tímto směrem) a důvodem přítomnosti cache nejsou primárně latence, ale datová propustnost (která zase tak netrápí procesory). V hrubých rysech podobné řešení tedy u GPU přišlo z trochu jiných důvodů než u CPU.
Přestože se tedy o latencích v rámci grafických čipů příliš nemluví, rozhodla se redakce webu Chips and Cheese tento aspekt otestovat a v první řadě se zaměřila na srovnání jádra Nvidia Ampere GA102 v podobě GeForce RTX 3090 a AMD Navi 21 v podobě Radeonu RX 6800 XT. Lze tedy říct, že (bohužel) proti sobě nestojí top modely obou řad, ale domnívám se, že to na celkovou situaci nebude mít nijak zásadní dopad:
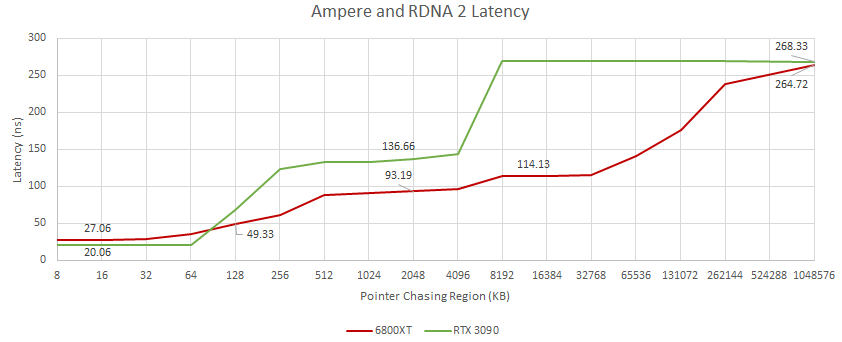
V grafu vidíme latence (osa y, tedy čím nižší, tím lepší) a jejich závislost na přesouvaných datových objemech (osa x). V případě zelené křivky (GeForce) jsou dobře vidět důsledky kapacity jednotlivých úrovní cache. Kapacita 64 KB L1 cache na SM se odráží ve zlomu u hodnoty 64 a kapacita 6 MB pro celou L2 cache se odráží mezi hodnotami 4096 a 8192 (konkrétně hodnota 6144 nebyla testována).
O to překvapivější je průběh u Radeonu, který má 128KB L1 cache a 4MB L2 cache, ale z grafu to nějak není poznat, namísto očekávatelných zlomů jsou zde hladké přechody. Od hodnoty 96 (KB) vykazuje Radeon nižší latence, od hodnoty cca 6144 (KB) velmi výrazně (zde už může jít o vliv Infinity Cache).
Redakce dále otestovala několik architektur Nvidie…

…a několik architektur AMD…
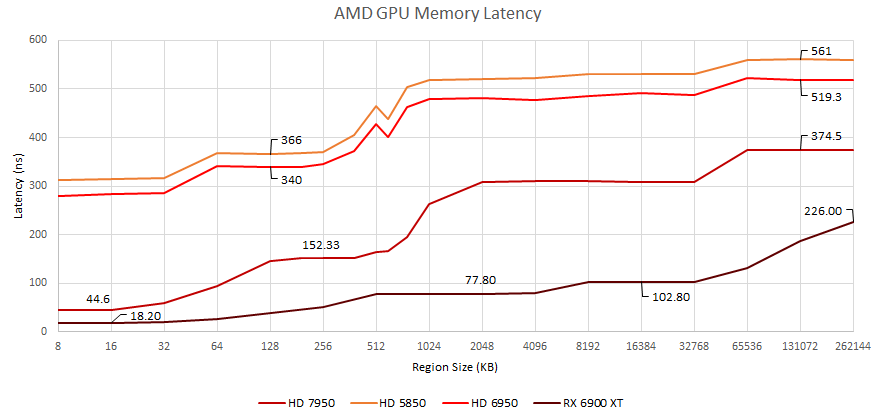
Bohužel některé architektury, které mohly přinesly podstatné změny, v těchto grafech chybějí, takže interpretace původu naměřených rozdílů může být trochu ošemetná. U Nvidie přinesl u nízkých datových objemů výraznou změnu Turing, u AMD by více napověděly (z hlediska změn ve struktuře cache) klíčové architektury jako Vega a RDNA, které však v grafu chybí. Ten však zachycuje velké změny s nástupem GCN (Radeon HD 7000), které zároveň dobře ilustrují v úvodu vysvětlený fakt, že latence GPU a grafický výkon GPU nemusejí nijak úzce souviset.
Zdroje:























