
Vega - rozbor architektonického preview, první fotografie a videa

Pojďme se podívat na shrnutí všeho, co odhalilo včerejší preview architektury Vega - nové technologie, fotografie čipu, odhad jeho rozměru a oficiální videa od AMD…
AMD pojala preview architektury Vega formou ukončení NDA na technologickou prezentaci a fotografie, což sama doplnila zveřejněním několika videí, které událost komentují a vysvětlují, než aby konkretizovaly nebo doplňovaly technologické detaily. Tentokrát ale nezačneme u architektury, na tu se zaměříme za chvilku, nejprve se podíváme na samotné GPU:

Vega 10
AMD sice hovoří o architektuře Vega a výslovně nespecifikovala, že GPU, které ukázala novinářům, ponese označení Vega 10, ale s ohledem na pravidla názvosloví, která zveřejnila při vydání Polaris, by první Vega - což je snad ta odhalená - měla být označena desítkou. Na snímku v úvodu i zde vidíte právě toto GPU v rukou šéfa Radeon Technology Group, kterým je Raja Koduri.

Na první pohled je zřejmé, že jde v souladu s očekáváním o větší jádro osazené dvěma čipy tzv. HBM2 pamětí. Jako první se nabízí otázka, kolik měří, případně jaké je ve srovnání s Fiji. Teoreticky by mělo být menší, protože Raja Koduri před časem prohlásil, že tak velké GPU jako Fiji v plánu není. Rovněž první srovnání fotografií Fiji a Vega 10 naznačují, že novinka bude menší. Otázka je o kolik. Fotografie pořízené zešikma značně komplikují srovnání a vnášejí do něj poměrně velkou chybu. Porovnáváním různých snímků Vegy 10 s Fiji vychází, že Vega 10 je skutečně menší, nicméně rozpětí vychází od 500 do 590 mm², což nám mnoho neříká. Zkusil jsem proto srovnání jádra oproti HBM2 čipu (který je větší než původní HBM). Pokud proporce HBM2 čipů uváděné Hynixem odpovídají těm, které jsou osazené na GPU Vega (tzn. 11,87 × 7,75 milimetru), pak v rámci omezené přesnosti dané nízkým rozlišením fotek vychází, že Vega 10 dosahuje zhruba 520-525 mm².
Jádro je nejen výrazně menší než AMD Fiji, ale také mnohem menší Nvidia Pascal GP100 (610 mm²). Vlastně je menší než několik high-endových GPU Nvidie, ovšem na poměry AMD jde i přesto o relativně velký počin. Porovnejte si to ostatně sami:
| GPU | karta | rozměry | sběrnice |
|---|---|---|---|
| GP100 | Tesla P100 | 610 mm² | HBM |
| GM200 | GeForce GTX Titan X GeForce GTX 980 Ti | 601 mm² | 384bit |
| Fiji | Radeon Fury X | 596 mm² | HBM |
| GT200 | GeForce GTX 280 | 576 mm² | 512bit |
| GK110 | GeForce GTX Titan GeForce GTX 780 Ti | 551/561 mm² | 384bit |
| GF100 GF110 | GeForce GTX 480 GeForce GTX 580 | 529 mm² | 384bit |
| Vega 10 | Radeon RX 5xx (?) | ~520-525 mm² | HBM |
| G80 | GeForce 8800 GTX | 484 mm² | 384bit |
| GP102 | Nvidia Titan X GeForce GTX 1080 Ti (?) | 471 mm² | 384bit |
| GT200b | GeForce GTX 285 | 470 mm² | 512bit |
| Hawaii Grenada | Radeon R9 290X Radeon R9 390X | 438 mm² | 512bit |
| R600 | Radeon HD 2900 XT | 420 mm² | 512bit |
| GM204 | GeForce GTX 980 | 398 mm² | 256bit |
| Cayman | Radeon HD 6970 | 389 mm² | 256bit |
| Tahiti | Radeon HD 7970 Radeon R9 280X | 365 mm² | 384bit |
| Tonga Antigua | Radeon R9 285 Radeon R9 380X | 359/366 mm² | 384bit |
| GF114 | GeForce GTX 560 Ti | 360 mm² | 256bit |
| R580 | Radeon X1900 XTX | 342 mm² | 256bit |
| Cypress | Radeon HD 5870 | 336 mm² | 256bit |
| G92 | GeForce 8800 GT GeForce 9800 GTX | 334 mm² | 256bit |
| G70 | GeForce 7800 GTX | 334 mm² | 256bit |
| GP104 | GeForce GTX 1080 | 314 mm² | 256bit |
| GK104 | GeForce GTX 680 | 294 mm² | 256bit |
| R520 | Radeon X1800 XT | 288 mm² | 256bit |
| NV40 | GeForce 6800 Ultra | 287 mm² | 256bit |
| RV790 | Radeon HD 4890 | 282 mm² | 256bit |
| R420 | Radeon X800 XT | 281 mm² | 256bit |
| G92b | GeForce GTS 250 | 264 mm² | 256bit |
| RV770 | Radeon HD 4870 | 256 mm² | 256bit |
| R430 | Radeon X800 XL | 240 mm² | 256bit |
| Polaris 10 | Radeon RX 480 | 232 mm² | 256bit |
| RV570 | Radeon X1950 PRO | 230 mm² | 256bit |
| GM206 | GeForce GTX 960 | 227 mm² | 128bit |
| G94 | GeForce 9600 GT | 225 mm² | 256bit |
| R300 | Radeon 9700 PRO | 218 mm² | 256bit |
| GK106 | GeForce GTX 660 | 214 mm² | 192bit |
| NV42 | GeForce 6800 GS | 213 mm² | 256bit |
| Pitcairn Curacao | Radeon HD 7870 Radeon R9 270X | 212 mm² | 256bit |
| GP106 | GeForce GTX 1060 | 200 mm² | 192bit |
| NV30 | GeForce FX 5800 Ultra | 200 mm² | 128bit |
| G71 | GeForce 7900 GTX | 196 mm² | 256bit |
| RV670 | Radeon HD 3870 | 192 mm² | 256bit |
Vega 10 se zdá být o něco (~50 mm²) větší než Nvidia GP102, naopak o dost (~90 mm²) menší než Nvidia GP100 a rovnou si můžeme říct, že toto srovnání není jen akademické - novinka totiž bude konkurovat oběma z nich. Alespoň v tom smyslu, že bude určena jak pro high-endový herní trh (×GP102), tak pro výpočetní sféru (×GP100).
Architektura
AMD byla poměrně skoupá na informace k architektuře, respektive na předání jakýchkoli doplňujících či vysvětlujících informací k těm, které jsou již zahrnuté v oficiální prezentaci.

Začněme u výpočetních bloků. S jistotou můžeme říct, že architektura krom standardní přesnosti FP32 (single-precision) podporuje nativně FP16 (half-precision) a to při dvojnásobné rychlosti oproti FP32 a dále podporuje nativně Int8 a to při čtyřnásobné rychlosti oproti FP32. Bylo potvrzeno, že podporuje i FP64 (double-precision) s tím, že rychlost je konfigurovatelná. Můžeme předpokládat, že profesionální varianta Vega nabídne poloviční výkon oproti FP32 (pozn.: model s podporou FP64:FP32 v poměru 1:2 bude podle některých zdrojů vydán v roce 2018) a desktopová varianta bude softwarově omezena. Jde tedy o první (známou) grafickou architekturu, která nativně a s vysokou rychlostí podporuje všechny čtyři formáty.
| AMD Vega 10 | Nvidia Tesla P100 | Nvidia Titan X | Nvidia GeForce GTX 1080 | |
|---|---|---|---|---|
| jádro | Vega 10 | GP100 | GP102 | GP104 |
| plocha | ~525 mm² | 610 mm² | 471 mm² | 314 mm² |
| takt | ~1500 MHz | 1328 / 1480 MHz | 1417 / 1531 | 1607 / 1733 MHz |
| FP64 | 1:2 / 1:16 (?) | 1:2 | 1:32 | 1:32 |
| TFLOPS | ~6,1 | ~5,3 | ~0,34 | ~0,28 |
| FP32 | 1:1 | 1:1 | 1:1 | 1:1 |
| TFLOPS | ~12,3 | ~10,6 | ~11,0 | ~8,9 |
| FP16 | 2:1 | 2:1 | 1:64 | 1:64 |
| TFLOPS | ~24,6 | ~21,2 | ~0,18 | ~0,14 |
| Int8 | 4:1 | - | 4:1 | neuvedeno |
| TFLOPS | ~49,2 | - | ~43,9 | ? |
Z herního hlediska je nicméně podstatný výkon v FP32. Výkon v Int8 je rozhodující pro neurální sítě, výkon v FP16 pro specifické výpočetní nasazení. API pro 3D grafiku zatím s využitím FP16 nepočítají, takže žádný výkonnostní bonus pro hráče podpora tohoto formátu v krátkodobém časovém horizontu nepřinese.

Přejděme ke geometrii a uspořádání čipu. AMD naznačila, že architektura Vega umožňuje vyšší škálování než dosavadní generace GCN, nicméně s GPU Vega 10 zůstane konfigurace na čtyřech geometrických procesorech jako nabízí Hawaii, Fiji nebo Polaris. Podobně jako mezi těmito čipy docházelo ke zvyšování geometrického výkonu i přes zachování čtyř jednotek pro její zpracování, tak i tentokrát dojde k posunu, ale významnějšímu než u předešlých generací. Geometrický výkon bude zdvojnásoben a čip, oproti předešlým, které dokázaly pracovat nanejvýš s 4 trojúhelníky zároveň, bude schopný najednou pracovat až s 11 trojúhelníky.
Tajemné schéma z imgur.com
Pokud jste sledovali vydání architektury Polaris, budete si možná ještě pamatovat implementaci technologie nazvané Primitive Discard Accelerator. Tento obvod byl určený pro detekci polygonů, které nebudou rasterizovány, případně vzorkovány při anti-aliasingu a ty odstraňoval v počáteční fázi zpracování. Tím významně vzrostl výkon karty v náročných geometrických scénách. Vega přinese tzv. Primitive Shader, který rovněž bude odstraňovat skryté polygony, jejichž zpracování by pouze snižovalo výkon. Přes podobný účel bude patrně jeho implementace odlišná. Patrně půjde o jednotku, která zároveň bude zpracovávat úlohy Vertex Shaderu a Geometry Shader. AMD nebyla konkrétnější, takže lze jen předpokládat, že implementace v této fázi bude efektivnější.
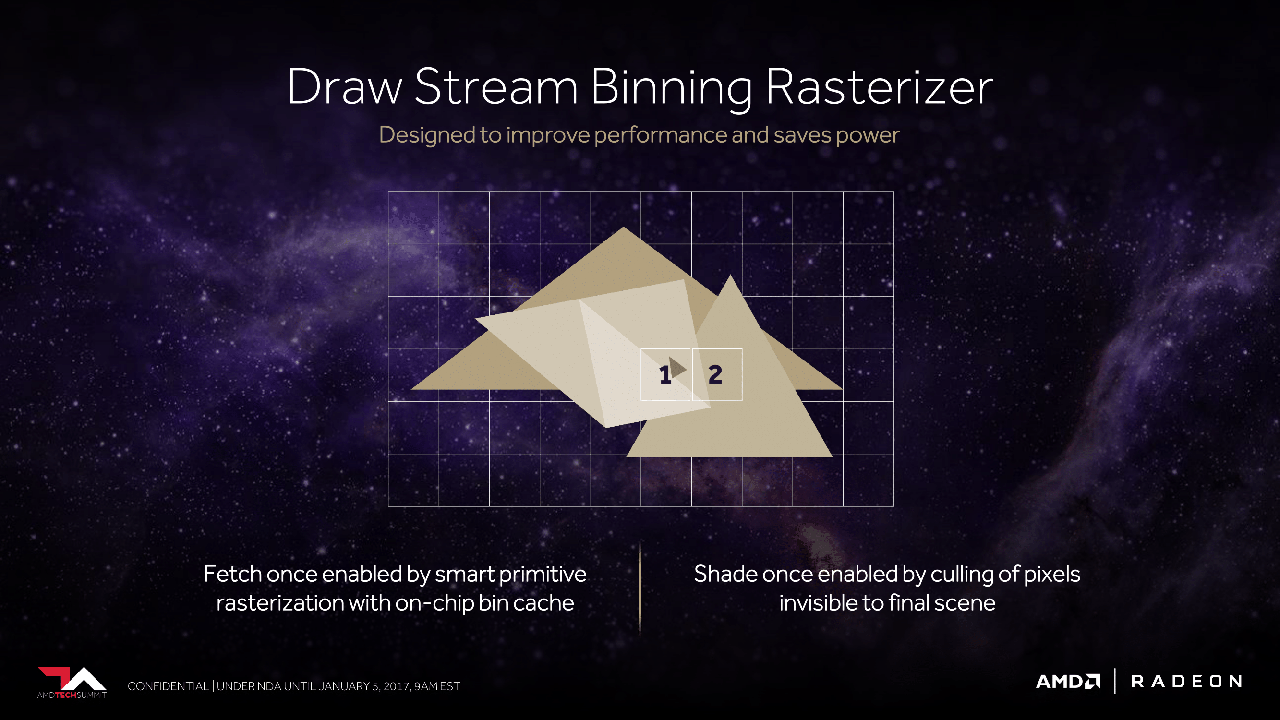
Významnou změnu podstoupil rasterizér. To je téma, které se - oproti rychlé podpoře formátů Int8 a FP16 v unifikovaném jádře - týká právě hráčů. AMD nazývá nový koncept Draw Stream Binning Rasterizer a jeho princip spočívá v rasterizaci po malých úsecích obrazu, které je možné zpracovat s využitím cache na úrovni čipu, čímž dojde k omezení nároků na paměťovou sběrnici a ke snížení energetických nároků. Jde v podstatě o odpověď na tile-based rasterizér Nvidie (Maxwell, Pascal), ale vzhledem k tomu, že ani o jedné technologii nebyly zveřejněny detailní informace, není přímé srovnání možné. Lze předpokládat, že drtivá část nárůstu herní efektivity architektury Vega oproti Polaris bude pocházet právě z této technologie.
Od rasterizace se dostáváme k ROP jednotkám. Přestože vlastně nevíme, zda budou nějak funkčně upraveny, se způsob jejich využití zásadně mění. Zatímco ROP dosavadní architektury GCN měla vlastní cache, Vega napojí ROP na sjednocenou L2 cache. ROP se v podstatě stanou klienty této cache. Přestože je tato změna pravděpodobně v prvním řadě důsledkem úprav rasterizace, geometrie a celkově přepracovaného konceptu cache, může mít příznivé dopady na výkon (především v případě využití techniky deferred shading, ale také pro asynchronní shadery) a do jisté míry snížit potřebu nízkoúrovňových optimalizací softwaru pro dosažení optimálního výkonu.

Již jsme nakousli cache: Začněme od první úrovně: Bude existovat L1 cache pro výpočty, pro geometrii a pro pixelové operace. Tyto tři se budou scházet u společné (výše zmíněné) L2 cache. Na L2 bude napojena obdoba současného hubu, který sdružuje klienty o nízkých nárocích na datovou propustnost (obrazové výstupy, PCIe sběrnici a podobně). Na druhé straně bude L2 napojena na tzv. high-bandwidth cache controller (HBCC), který naopak spojí všechny klienty s vysokými nároky na datovou propustnost. Mimo samotnou L2 cache půjde o sběrnici určenou k propojení s externími klienty (podle starších informací by měla dosahovat až 512 GB/s přenosové rychlosti) a dále HBCC připojí, co je ve schématu označeno jako high-bandwidth cache (HBC), která nebude tvořena ničím jiným, než paměťmi HBM.
Zatímco v případě grafických karet pro desktop bude HBC fungovat jako standardní grafická paměť, v případě výpočetních systémů půjde skutečně jen o cache a hlavním úložištěm budou velkokapacitní NV paměti. Už v případě GPU Fiji AMD k HBM paměti přistupovala trochu odlišně než k DDR a využívala ji podobně jako cache, do které byla permanentně načítána / mazána aktuálně potřebná / nepotřebná data ze systémové paměti. Zatímco v případě DDR pamětí s omezenou propustnosti je tento přístup problematický (z celkové propustnosti je stále ukusována část odpovídající datovým přenosům po PCIe), v případě výrazně rychlejších HBM nehraje snížení propustnosti o část blokovanou přenosy po PCIe významnou roli.

Unifikovaná L2 cache nebude jediná hardwarová změna, která jde naproti vývojářům herních enginů a her. Další práci jim ušetří automatické řízení zdrojů. Nebudou muset sami rozhodovat, případně vlastním softwarem řídit, jaké zdroje a data uloží do grafické a jaké do systémové paměti. Automaticky se postará grafické jádro. Toto je na poli herních GPU zcela nová a dá se říct revoluční technologie, která nemá u dosavadních grafických karet obdoby. Podobná funkce se zatím objevila pouze u výpočetního GPU Nvidia P100 v rámci CUDA. Ve světě 3D grafiky jde ale o novum.
AMD nijak nekonkretizovala datum uvedení Radeonů postavených na nové architektuře. Oficiálním termínem proto zůstává dosavadní údaj: H2 2017, první polovina letošního roku. Jak je zvykem, první polovinou je vždy míněna druhá čtvrtina. Můj osobní tip by byl druhá polovina května plus mínus měsíc. Předpokládám, že do (poloviny?) dubna bude letošní rok patřit procesorům Ryzen.
Nakonec se můžete podívat na videa od AMD:
Zdroje:
fotografie GPU: Anandtech, TechReport, WCCFTech, 4Gamer























