AMD uvedla Instinct MI100, první GPU architektury CDNA se 185 TFLOPS FP16

Po dvou letech od doby, kdy jsme poprvé slyšeli o GPU Arcturus, vydává AMD první výpočetní GPU postavené na architektuře CDNA: Instinct MI100…
CDNA je architektura, která vznikla dalším vývojem GCN / Vega, která byla již ve své době velmi výhodná co do poměru výpočetní výkon na tranzistor a takt. Ačkoli architekturu CDNA ohlásila AMD teprve letos v březnu, o samotném GPU Arcturus jsme slýchali od podzimu 2018. Teprve v roce 2019 ale začalo být jasné, že nepůjde o nástupce tehdejších Radeonů ve smyslu herního produktu, ale ve smyslu výpočetního řešení. To je nyní uvedeno jako AMD Instinct MI100 (jak bylo avizováno, „Radeon“ z názvů výpočetních produktů odpadá).

AMD na Instinct MI100 vypichuje především to, že jde o vůbec první GPU s výpočetním výkonem ve standardním formátu FP64 přesahujícím 10 TFLOPS. Jádro je ale zajímavější spíše v jiných ohledech. Podívejme se na něj:

Velký kus 7nm waferu (AMD to v tiskovce neuvádí, ale podle některých zdrojů jde o 750 milimetrů čtverečních, což by bylo vůbec největší GPU, které kdy AMD/ATi vyrobila) lemují čtyři HBM2 čipy, každý s kapacitou 8 GB a efektivní přenosovou frekvencí 2,4 GHz, tzn. celkovou šířkou pásma 1229 GB/s. ECC je podporováno na úrovni pamětí i na úrovni celého jádra.
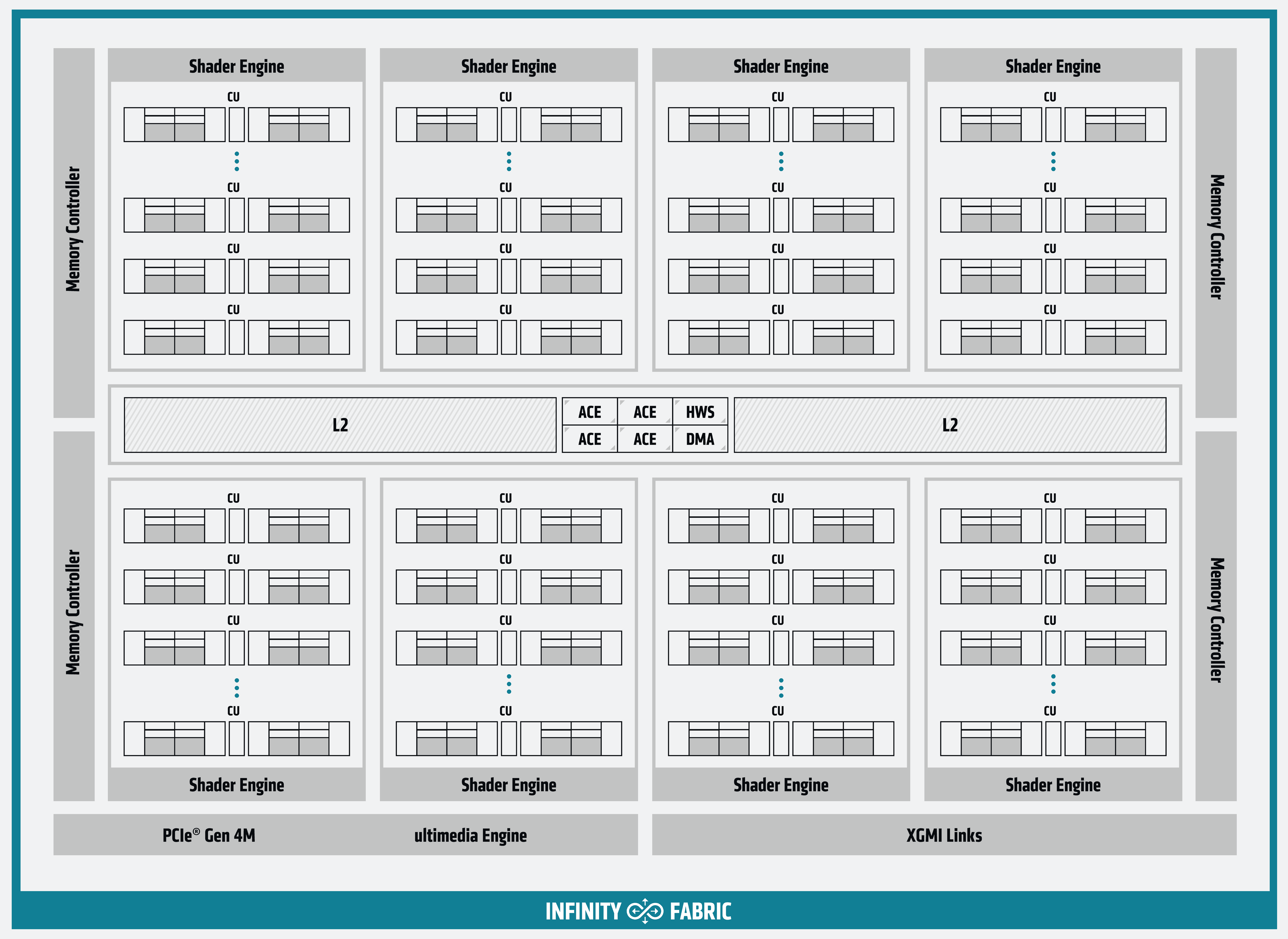
Jádro se fyzicky skládá z osmi bloků Shader Engine(s), přičemž každý je vybaven 16 bloky CU, z nichž každý obsahuje 64 stream-procesorů. To máme 8192 stream-procesorů celkem, z čehož je v případě Instinct MI100 aktivních 7680 z nich.
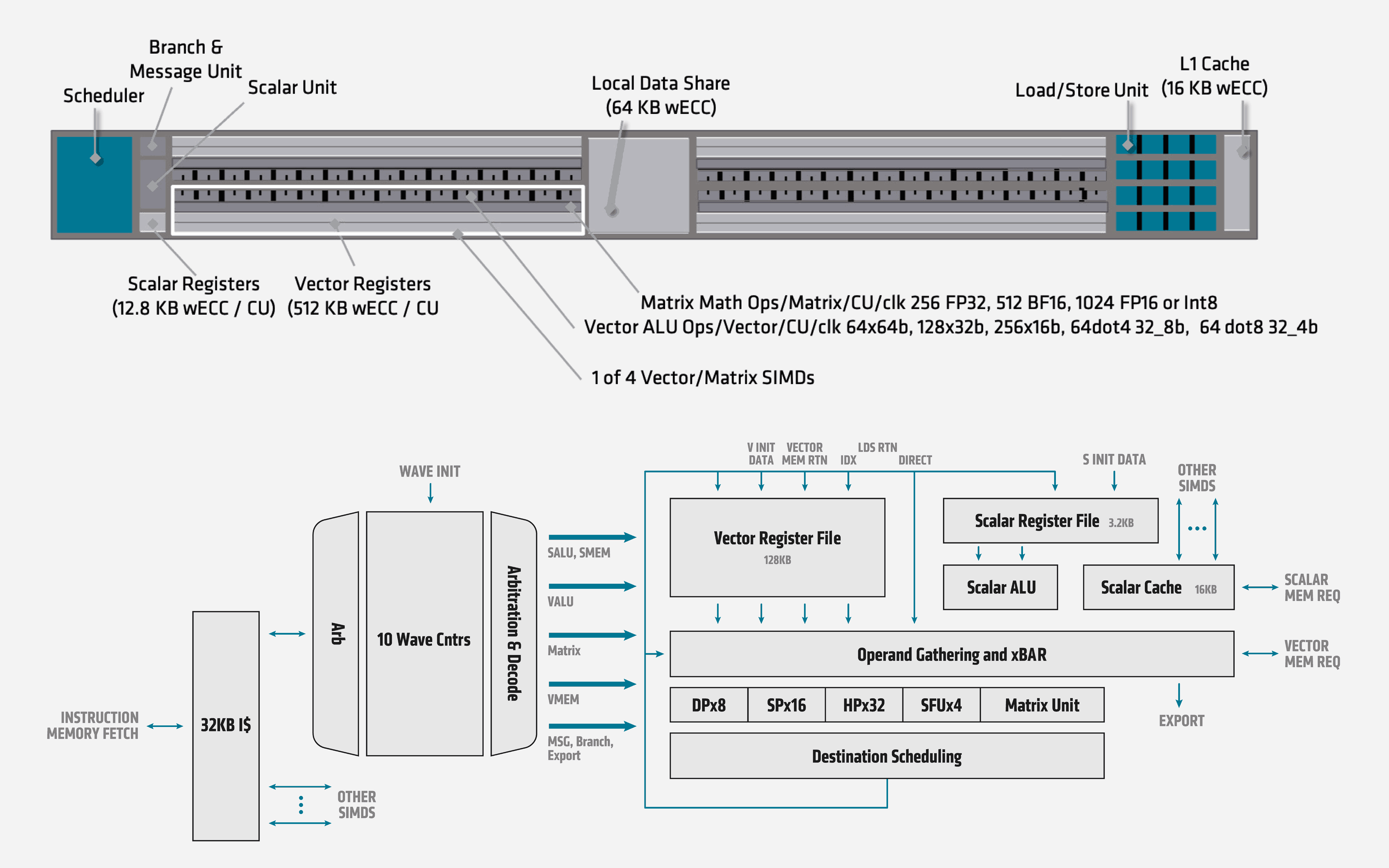
Na rozdíl od Nvidie, která pro různé formáty (přesnost) implementuje různé výpočetní jednotky, zůstává AMD u tradičního přístupu kdy vše FP64 počínaje a Int8 či Int4 konče běží na stejném křemíku. V případě CDNA však došlo k hardwarovému rozšíření CU o podporu maticových operací (názvoslovím Googlu a Nvidie: Tensor Ops). Pokud hodnoty zmíněné ve dvou předchozích slajdech roznásobíme s frekvencí, získáváme údaje o výpočetním výkonu:
| AMD Radeon Instinct MI60 | AMD Instinct MI100 | Nvidia Tesla V100 | Nvidia A100 | |
|---|---|---|---|---|
| GPU | Vega 20 | Arcturus | GV100 | GA100 |
| architektura | GCN4 | CDNA | Volta | Ampere |
| formát | PCIe | PCIe | SXM2 | SXM4 / PCIe |
| CU/SM | 60 | 120 | 80 | 108 |
| FP32 jader | 3840 | 7680 | 5120 | 6912 |
| FP64 jader | - | - | 2560 | 3456 |
| INT32 jader | - | - | 5120 | 6912 |
| Tensor Cores | - | ? | 640 | 432 |
| takt | 1800 MHz | 1502 MHz | 1530 MHz | 1410 MHz |
| ↓↓↓ T(FL)OPS ↓↓↓ | ||||
| FP16 | 29,5 | 184,6 | 31,4 | 78 |
| BF16 | 92,3 | 39 | ||
| FP32 | 14,7 | 23,5 46,1 | 15,7 | 19,5 |
| FP64 | 7,4 | 11,5 | 7,8 | 9,7 |
| INT4 | 118 | 184,6 | ? | ? |
| INT8 | 59,0 | 184,6 | ? | ? |
| INT16 | 29,5 | ? | ? | ? |
| INT32 | ? | ? | 15,7 | 19,5 |
| FP16 tensor | 184,6 | 125 | 312/624* | |
| BF16 tensor | 92,3 | 312/624* | ||
| FP32 tensor | 46,1 | 19,5 | ||
| TF32 tensor | ? | 156/312* | ||
| FP64 tensor | 19,5 | |||
| INT8 tensor | 184,6 | 624/1248* | ||
| INT4 tensor | ? | 1248/2496* | ||
| ↑↑↑ T(FL)OPS ↑↑↑ | ||||
| TMU | 240 | 480? | 320 | 432 |
| sběrnice | 4096bit | 4096bit | 4096bit | 5120bit |
| kapacita paměti | 32 GB | 32 GB | 32 GB / 16 GB | 40 GB |
| HBM2 | 2,0 GHz | 2,4 GHz | 1,755 GHz | 2,43 GHz |
| pam. propustn. | 1024 GB/s | 1229 GB/s | 900 GB/s | 1555 GB/s |
| TDP | 300 W | 300 W | 300 W | 400 / 250 W |
| Transistorů | 13,2 mld. | 50,0 mld.? | 21,1 mld. | 54,2 mld. |
| plocha GPU | 331 mm² | 750 mm²? | 815 mm² | 826 mm² |
| proces (TSMC) | 7 nm | 7 nm | 12 nm FFN | 7 nm N7 |
| datum | 2018 | 2020 | 2017 | 2020 |
* pouze při využití sparsity / Sparse Tensor Cores
údaje, které AMD neuvádí, ale v některé zdroje ano, jsou označeny otazníkem (např. dle TechPoweUp obsahuje GPU Arcturus texturovací jednotky i ROP, ale počet ROP je omezen na 64 - což je pro 8192 stream-procesorů velmi nízká hodnota - u Navi 21 je na 5120 stream-procesorů přítomno 128 ROP; je tedy zřejmé, že vyvážení návrhu se silně kloní k výpočtům, ovšem grafiku by jádro mělo být schopno zvládat také - otázka jsou ovladače)
Tabulka srovnává Instinct MI100 s předchůdcem (MI60) a konkurenčními produkty Nvidia V100 (Volta) a A100 (Ampere). AMD MI100 dosahuje vyššího výkonu než Nvidia A100 v FP16, FP32 i FP64. Zatímco v FP64 je AMD o 19 % napřed, v případě FP16 a FP32 je téměř 2,4× rychlejší. V maticových operacích je AMD IM100 sice rychlejší než Nvidia V100 a podporuje i více formátů, ale nedosahuje výkonu Nvidia A100. To není překvapivé. Nvidia se s výpočetním Amperem zaměřila na podporu širšího spektra formátů a zvýšení výkon v maticových operacích, ale základní výpočetní výkon byl zvýšen ve srovnání s obvyklými mezigeneračními nárůsty poměrně málo: V FP32 a FP64 jen o 24 % (což při 2,56× vyšším rozpočtu tranzistorů není mnoho).
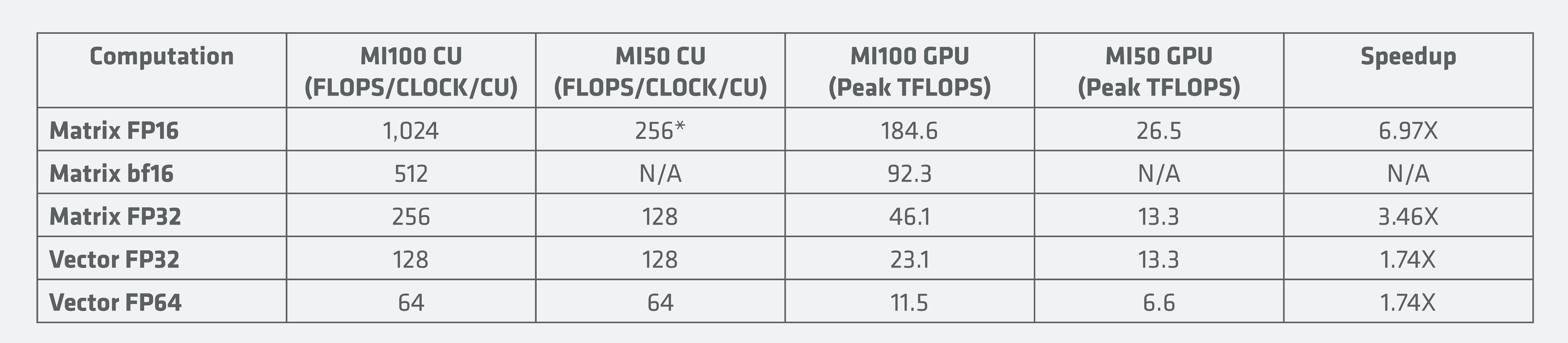

AMD Instinct MI100 se proto hodí tam, kde je potřeba vysoký FP64/FP32/FP16 výkon, případně kombinace klasických a maticových výpočtů. V případě čistě maticových výpočtů je Nvidia A100 ve výhodě. To AMD dále kompenzuje cenou, která by (podle udávaného ~2× lepšího poměru cena / výkon v FP64 výpočtech) měla dosahovat zhruba 60 % ceny Nvidia A100.

AMD má již odbyt na Arcturus jistý, použití „budoucí generace“ akcelerátorů Instinct bylo loni a v prvním pololetí letošního roku ohlášeno jak v rámci druhého nejvýkonnějšího ohlášeného superpočítače Frontier (1,5 EFLOPS, 2021), tak vůbec nejvýkonnějšího ohlášeného superpočítače El Capitan (2 EFLOPS, 2022). Ve druhém z případů by teoreticky mohlo jít i o nějakou inovovanou či 5 nm verzi akcelerátoru; do roku 2022 zbývá ještě dost času.
Datasheet i webové stránky AMD uvádějí v rámci podporovaných operačních systémů (pouze) Linux 64bit (viz např. slajd výše).

Karty jsou určené pro serverové skříně, kde budou pasivně chlazeny průvanem v racku. Karty lze pomocí propojek Infinity Fabric řetězit po čtyřech a v rámci desky osazovat po dvou těchto čtveřicích. Na „pajšl“ se můžete laskavě podívat v níže připojeném videu.
Zdroje: