
AMD Steamroller - architektura třetí reinkarnace Bulldozeru s vyšším IPC podrobněji

Poslední týden byl velmi bohatý na novinky papírového charakteru. Intel jakoby se s AMD předháněl, kdo namaluje hezčí procesor - po Knights Corner, Jaguaru a Atomu Valleyview tu máme Steamroller…
Kapitoly článků
1. Instrukční dekodér, výpočetní jednotky, branching a register file
Steamroller (parní válec), jak AMD potvrdila už v loňských roadmapách, bude třetí generace modulární procesorové architektury, na jejímž začátku stál Bulldozer. I když někteří uživatelé vyjadřují zklamání nad tím, že je Steamroller vylepšeným Bulldozerem, jde v podstatě jen o slovíčkaření - není podstatné, zda se na Steamroller budeme dívat jako na třetí generaci Bulldozeru, nebo jako na třetí generaci modulární architektury, jejíž první generací byl Bulldozer. Je vedlejší, jak si odvodíme původ, podstatné jsou cíle produktu a zda se jich podaří dosáhnout.
Cíle novinky chystané na rok 2013 jsou tři:
- lepší zásobování jader (instrukcemi a daty)
- zvýšení jednojádrového výkonu
- zlepšení poměru výkon / watt
Instrukční dekodér
V souvislosti s Bulldozerem bylo nejednou kritizováno úzké hrdlo v podobě instrukčních dekodérů, které v porovnání s architekturou Intel Core dosahovaly (v typické konfiguraci) jen poloviční šířky.
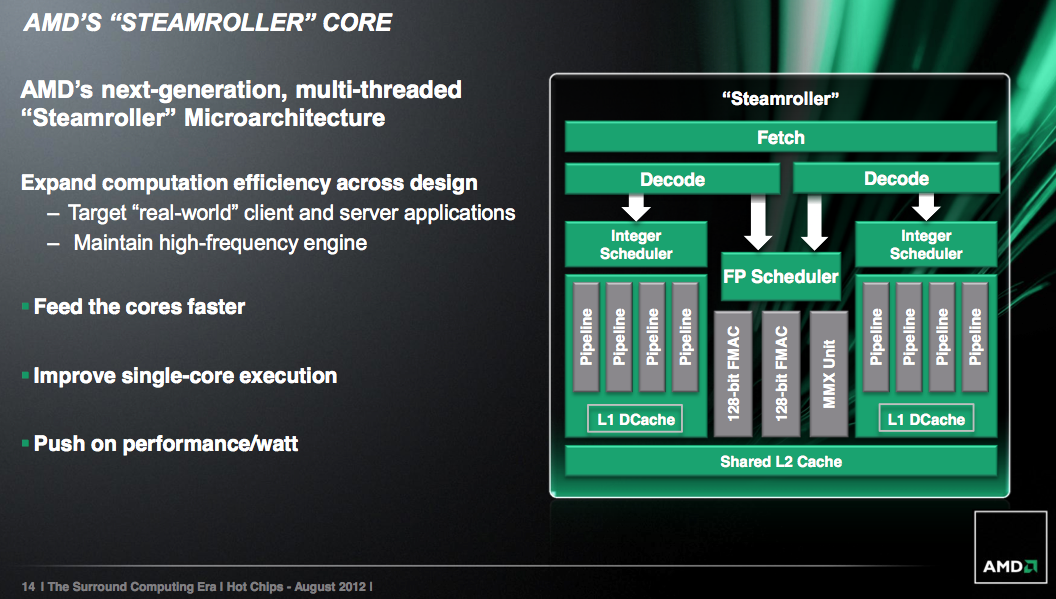
Zda tato kritika byla oprávněná, nebo šlo jen o údaj, který byl nejvíc na ráně a proto používaný jako vysvětlivka Bulldozeřího výkonu, se skutečně dozvíme až po vydání Steamrolleru. Právě ten totiž rozšířil instrukční dekodéry, takže umožňuje zpracovávat 4 instrukce na jádro. Navíc oba dekodéry v modulu mohou fungovat paralelně, nikoli prokládaně (ve stylu ping-pong).
Výpočetní jednotky (FPU, INT), branch prediction a register file
AMD převazala predikci větvení z architektury Piledriver, kterou ještě dál vylepšila, což i v kombinaci s větší bufferem snížilo počet chybných predikcí až o 20 % - tohoto čísla ale bude dosahováno spíše v serverové sféře.
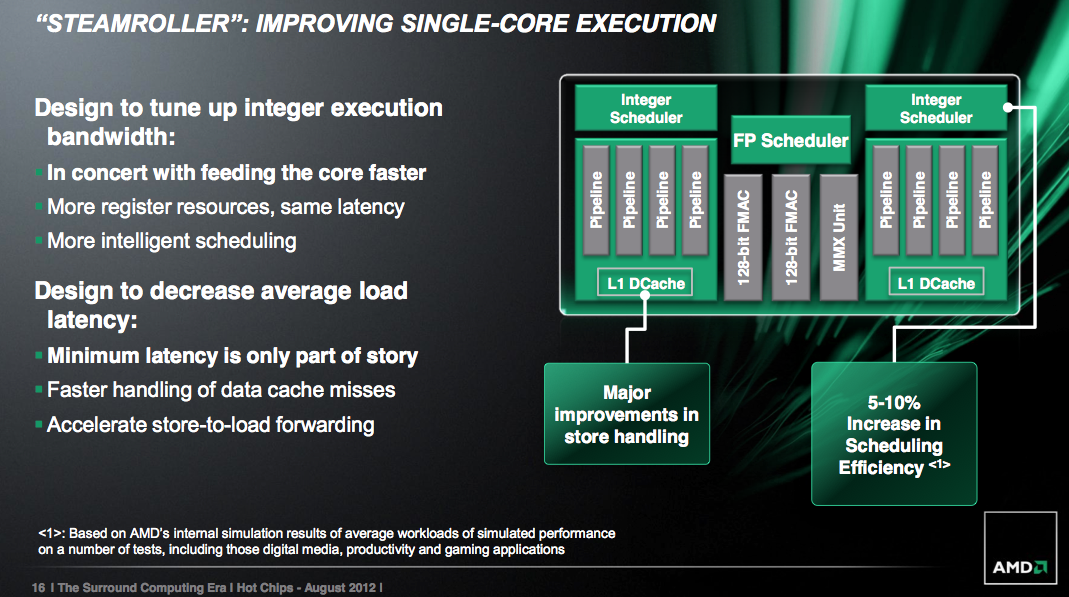
Architektura samotné FPU zůstala po funkční stránce beze změny - podařilo se však zredukovat její proporce a to i sdílením některých částí hardwaru (MMX jednotka) bez negativního dopadu na výkon. Funkčně se nezměnily ani INT jednotky - odlišný však bude způsob, jakým je s nimi zacházeno. Už jsme zmínili širší instrukční dekodéry - rozšířené byly i registry, které díky kompresi (i) duálních operátorů budou využívány o fous efektivněji.
Na následující stránce se podíváme na změny L1 a L2 cache…
Zdroje:
následující kapitola
Kapitoly článků
1. Instrukční dekodér, výpočetní jednotky, branching a register file























