
Lovelace není jen Ampere-refresh. To ale neměl být nikdy.

V posledních dnech se vyrojila řada článků a příspěvků na téma, že grafická architektura Nvidia Lovelace není jen zrychlený Ampere. Nebo že byla, ale už není. Což je však krajně nepravděpodobné…
Tyto zdroje a články nemá cenu podrobněji rozebírat - v podstatě všechny tvrdí totéž: Že současná Lovelace není tím, o čem se donedávna mluvilo a že z jakéhosi „Ampere-refresh“ udělala Nvidia pomocí neupřesněného „čáry máry fuk“ cosi jako „skoro-Hopper“. A ještě k tomu mělo dojít někdy v poslední době.
Tyto zprávy vykazují jeden společný jmenovatel a to nepochopení, jak vývoj GPU funguje a co je vůbec možné. V první řadě je potřeba říct, že pokud Nvidia paralelně vyvíjí dvě architektury pro 5nm/4nm procesy, Lovelace a Hopper a obě mají být vydané v roce 2022, pak tyto architektury budou podobně pokročilé, tedy na podobné technologické úrovni (což nemá nic společného s jejich orientací na různé segmenty trhu). Skutečně si nelze představovat, že pánové v Nvidii, kteří vyvíjeli Ampere (vydaný 2020 a po stránce architektury dokončený nejpozději v roce 2019), od té doby jen seděli a koukali: [2019] „Tak máme hotový Ampere. Co budeme dělat?“ - „Nic. Do Ampere se přidají výpočetní jednotky a nazveme to Lovelace.“ - „A ty tři roky tu budeme jenom sedět?“ - „Můžeme vařit kafe. Jensen si ničeho nevšimne.“ Tři roky utekly, přišel rok 2022, kdy má být Lovelace vydána a vývoj přišel s nápadem, že ukradne myšlenky týmu vyvíjejícímu výpočetní jádro Hopper, přilepí je do Lovelace a tím dožene tři léta ztracená kávovými dýchánky.
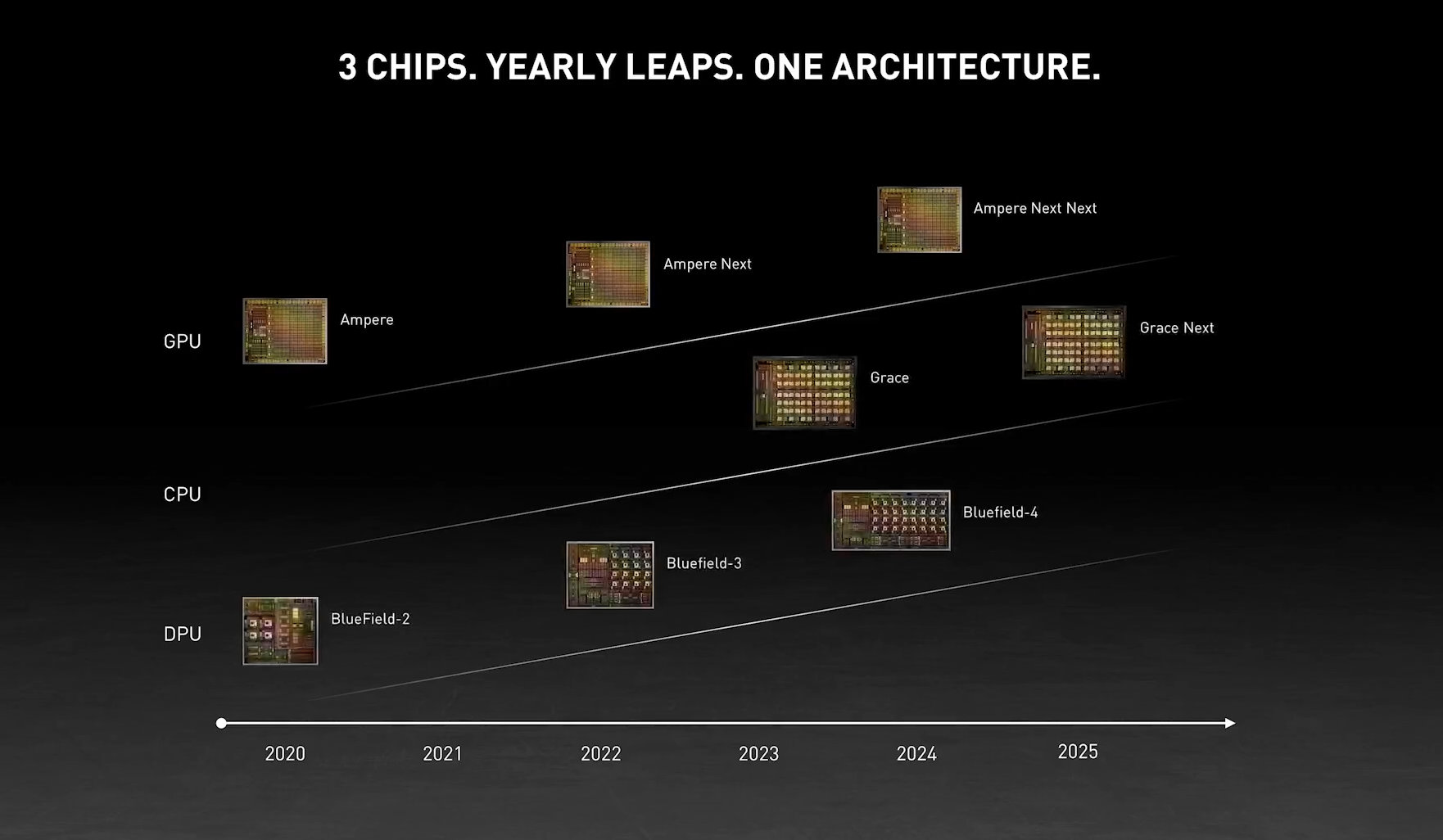
Tak skutečně vývoj nefunguje a fungovat nemůže. Všechny prvky architektury, které mají být do čipu implementovány, musejí být definované v časné fázi vývoje, nikoli v roce vydání (nebo rok před ním). Takový zásah by znamenal potřebu začít u řady vývojových kroků znovu a posunul vydání o (podstatně) více než rok.
Co se reálně mohlo stát a co se nejspíš i stalo, je, že se leakeři dostali k podrobnostem o architektuře Lovelace, které v předchozích materiálech, jež Nvidia poskytuje partnerům, neuváděla. Zkrátka, že se krom údajů o počtu funkčních bloků, sběrnicím a TDP začaly objevovat údaje i o tom, jak jsou tyto funkční bloky konfigurované. To nezapadlo do představy těchto leakerů, která se odvíjela od konfigurace Ampere a rozpor si vysvětlili změnou na poslední chvíli ze strany Nvidie. Změna samozřejmě čistě teoreticky možná je, ale pokud by k ní došlo, muselo to být v rané fázi vývoje. Rozhodně ne v posledním roce.
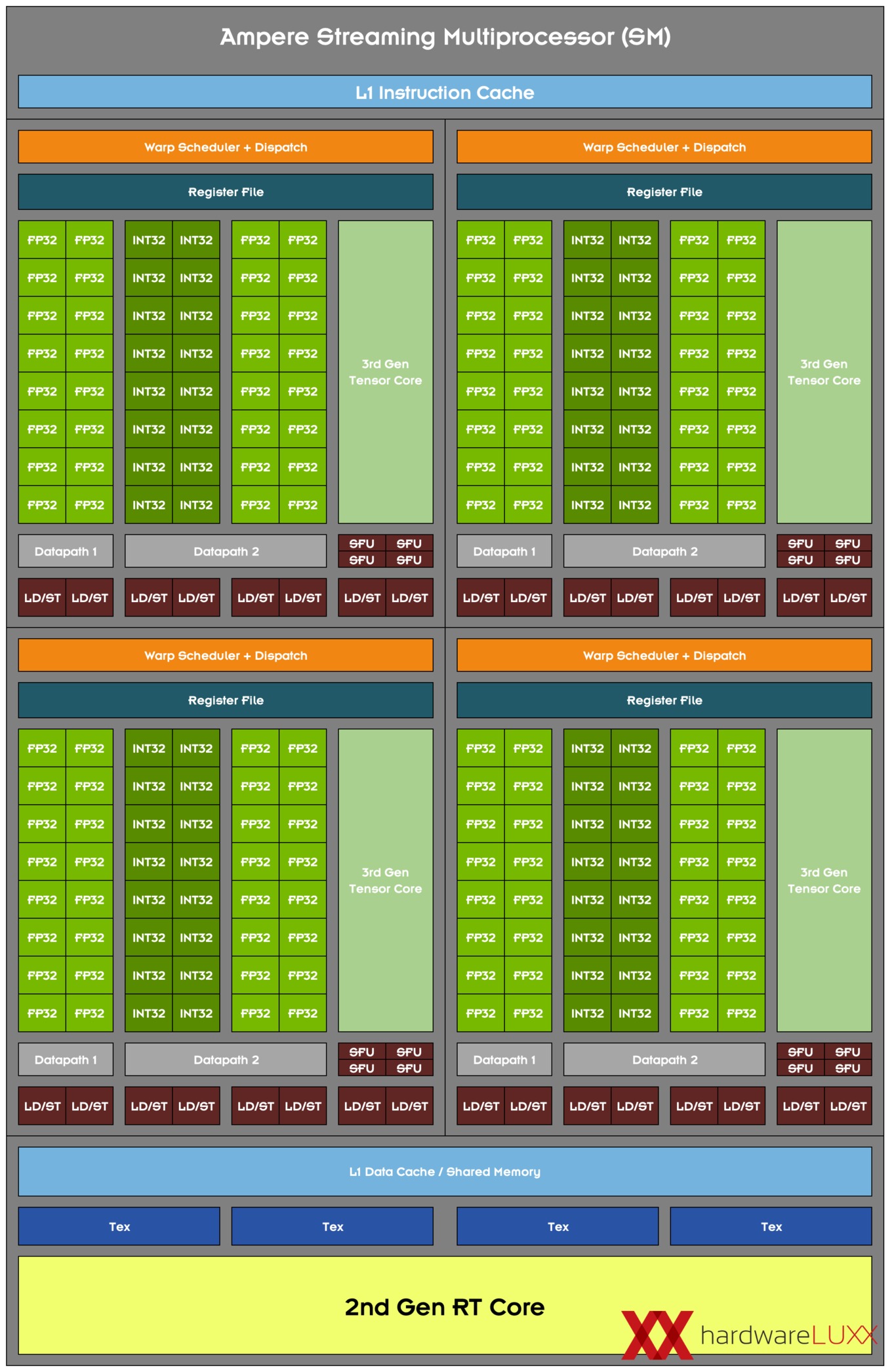
SM blok Ampere (druhý set FP32 jednotek sdílí hardwarové prostředky s INT32 jednotkami)
Co tedy leakery překvapilo? Čistě teoreticky to krom zvětšené L2 cache může být úprava konfigurace SM bloků se stream-procesory. Připomeňme, že Ampere v každém SM nese 2× více FP32 jednotek než jeho předchůdce Turing. Jenže v přepočtu na FP32 FLOPS dosahuje Ampere nižšího výkonu než Turing. Čím to je? Důvody jsou dva:
(1) Prudce vzrostl počet FP32 jednotek, ale tento nárůst nebyl kopírován nárůstem počtu texturovacích jednotek ani nárůstem počtu ROP. Můžeme si to ilustrovat následovně:
- FP32 jednotek: 4608 -> 10752 => 2,33×
- texturovacích jednotek: 288 -> 336 => 1,17×
- ROP: 96 -> 112 => 1,17×
Taktovací frekvence k tomu přidala 10 % výkonu navrch. Reálný herní výkon stoupl mezigeneračně 1,45×, přičemž výše uvedené 17% navýšení počtu základních bloků v kombinaci s 10% navýšením taktů by zajistilo mezigenerační posun FPS 1,28×. Zdvojnásobení počtu FP32 jednotek mělo tedy na herní FPS vliv jen asi 13 %.
(2) Druhý (přidaný) set FP32 jednotek u Ampere není ve stejném postavení jako ten původní (sdílí svoji pozici s celočíselnými jednotkami). Zjednodušeně řečeno pouze první set Ampere má k dispozici vlastní pipeline a může být využit libovolně. Druhý set bylo možné využít jen v rámci co-issue, tedy ne vždy, ale jen za určitých příznivých okolností. Ač bylo takové řešení kompromisní, pravděpodobně Nvidii nestálo příliš tranzistorů, takže ač klesla efektivita vyjádřená v poměru teoretických FLOPS na reálné FPS, z hlediska efektivity na tranzistor to mohlo mít smysl.
Je docela pravděpodobné, že další vývoj - a zvlášť při posunu z 8nm na 5nm nebo 4nm proces - by spočíval v implementaci tranzistorů potřebných pro to, aby i tyto přidané FP32 mohly fungovat nezávisle. To by opět zlepšilo efektivitu v poměru teoretických FLOPS na reálné FPS. Možná však ne na úroveň Turingu, neboť - jak je vysvětleno výše - důvody pro snížení jsou dva. Stále platí, že zdvojnásobením počtu aritmetických jednotek bez zdvojnásobení počtu texturovacích jednotek a ROP neznamená zdvojnásobení celkového herního výkonu. Aritmetika je ale relativně levná na tranzistory, a tak může být výhodné prostě ponechat výpočetní jednotky zčásti nevytížené, než výkon navyšovat jinou cestou.

Paralelu bychom mohli vidět v GPU ATi R580 (Radeon X1900 XTX) nastupujícím po R520 (Radeon X1800 XT). Tehdy došlo ke ztrojnásobení počtu aritmetických jednotek při zachování počtu texturovacích jednotek a ROP. Aritmetické jednotky byly nezávislé (využití nebylo podmíněno co-issue jako u Ampere) a tento trojnásobek znamenal průměrně 21% nárůst herních FPS. Implementace onoho „trojnásobku“ však stála jen o 19,6 % tranzistorů navíc.
Podobnou filozofii zřejmě s generacemi Ampere a Lovelace uplatňuje Nvidia, jen s těmi rozdíly, že nejde o trojnásobek, ale dvojnásobek aritmetických jednotek a že jejich výkon není zpřístupněn najednou, ale postupně (u Ampere jako co-issue).
Právě hypotetická úprava a efektivnější využití dostupných aritmetických jednotek mohou být důvodem, proč se některé zdroje domnívají, že se v Lovelace něco na posledních chvíli změnilo. Je však pravděpodobnější, že architektonické změny byly plánované dlouhodobě.























