
Podpora Navi 10, Vega 20 a Vega 12 zaznamenána v ovladači AMD
Ovladače Radeon Software Adrenalin Edition 18.1.1 Alpha pro Windows sice opravily potíže s několika DX9 hrami, ale krom toho přinesly jednu zásadní novinku: Podporu pro nové grafické produkty…
Když v polovině prosince přišla zpráva, že se v ovladačích poprvé objevila podpora nadcházejícíc grafické architektury AMD Navi, měly četné zdroje tolik práce s uváděním této zprávy na pravou míru (že žádná podpora Navi v ovladači není, protože daný kód nepochází z ovladače, ale jde o placeholder z debuggeru), že si ani nevšimly, že se mezi tím podpora Navi („gfx1000“) v ovladači skutečně objevila, konkrétně v části pro OpenCL.

Asi tedy nemůžeme tvrdit, že nyní přichází ovladač s prvotní podporou Navi, to se odehrálo již v prosinci, ale můžeme tvrdit, že přichází ovladač, v němž byla poprvé nalezena podpora konkrétně pro trojici čipů Navi 10, Vega 12 a Vega 20:

Vezměme to od konce:
Vega 20 je v zásadě podobný čip jako stávající Vega 10 použitá na Radeonech RX Vega 56 a 64 (nese 4096 stream-procesorů, 256 texturovacích jednotek, 64 ROP). Disponuje ale přinejmenším třemi zásadními rozdíly: Je vyráběn na 7nm procesu (namísto 14nm), podporuje rychlé výpočty v double-precision (FP64) a je vybaven dvojnásobně širokým paměťovým rozhraním pro HBM2, takže sběrnice může při osazení 2GHz HBM2 dosahovat přenosové rychlosti 1 TB/s. Podstatnější ale je, že dvojnásobek paměťových kanálů umožňuje osazení dvojnásobku HBM2 čipů, tj. kapacity až 32 GB. Právě velká paměť a rozšířená výpočetní podpora předurčují toto jádro do profesionálního segmentu. Pro hráče patrně určeno nebude (snad kdyby nastalo zpoždění u Navi), na ty se zaměří právě Navi.
Vega 12 je docela záhada, o existenci tohoto čipu víme již nějaký ten pátek, přesto není přesně známo, o co jde. Pokud bychom vycházeli z paralely u Polaris (10, 11, 12), pak by muselo jít o GPU menší než Vega 11, nicméně není to na beton jisté. Teoreticky lze připustit, že jde o nějakou speciální verzi Vegy 11, ale osobně bych se zatím klonil k tomu, že zkrátka půjde o menší Vegu s řekněme 768-1024 stream-procesory. Spekulovat, zda by nesla HBM2, nebo tzv. low-cost HBM, nebo nějaké GDDR, by v tuto chvíli bylo na házení kostkou.
Navi 10. Architektura Navi je nástupcem architektury Vega, který je plánovaný pro 7nm výrobu. Protože AMD připravuje Vegu 20 orientovanou na rychlé double-precision (FP64) výpočty, lze předpokládat, že přinejmenším první produkty z generace Navi rychlé FP64 podporovat nebudou, tudíž budou určené hlavně pro hráče a akceleraci AI.
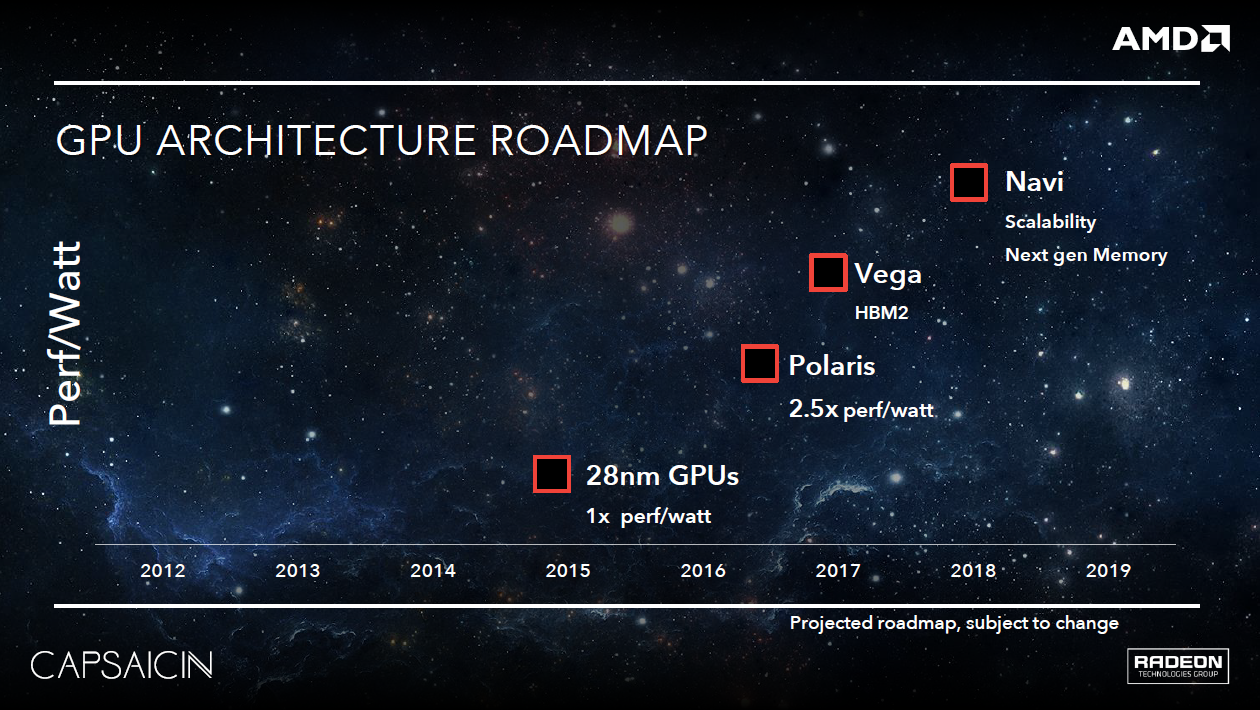
Existuje předpoklad, že Navi bude podporovat skládání čipů podobně jako procesory s jádry Zen. Tento předpoklad vychází z několika indicií:
- První je poznámka „scalability“, která se u chlívečku „Navi“ objevila v oficiální roadmapě AMD. Řetězení jednotlivých křemíkových čipletů by bylo možné chápat jako škálovatelnost.
- Druhou indicií je poznámka „next-gen memory“. Pokud by se Navi měla existovat výlučně v podobě monolitických čipů, stačily by jí stávající HBM2, jejichž potenciál nebyl dosud plně využit. Pokud ovšem z důvodu skládání bude na pouzdru GPU málo místa, byly by třeba HBM3, které s jedním čipem zvládnou to, na co jsou potřeba dva HBM2.
- Třetí střípek pochází z výroku (donedávna) šéfa grafické divize, Raji Koduriho, který v době vydání Fiji prohlásil, že ve vývoji dalších velkých čipů nevidí smysl. Vega ukázala, že mezigenerační zvětšování, které trvalo od vydání GPU RV770 (RV790 → Cypress → Cayman → Tahiti → Hawaii → Fiji) skutečně zastavilo a Vega 10 byla plošně o 112 mm² (tedy zhruba čtvrtinu) menší. Skládání se tedy nabízí jako alternativní cesta k velkým (≥600mm²) monolitickým čipům.
- Čtvrtý střípek pak vychází z faktu, že AMD pro grafické čipy implementovala sběrnici Infinity Fabric, kterou používá u procesorů Zen jak k propojení jader uvnitř čipu, tak ke vzájemnému propojení křemíkových modulů.
I když všechny čtyři indicie ukazují jedním směrem, musíme brát v potaz i fakt, že šéf Radeon Technology Group, Raja Koduri, který nastavil vývoj právě tímto směrem, již ve společnosti nepracuje. Oficiálně z firmy odešel v listopadu 2017, ale na chod grafické divize přestal mít vliv již koncem léta, kdy odešel na dlouhodobou dovolenou. Uvedení architektury Navi se původně očekávalo na konci roku 2018, ale v současnosti to vypadá spíš na první pololetí 2019 (14nm Vega: 2017, 12nm Vega: 2018, 7nm Navi: 2019).
To znamená, že mezi odchodem Koduriho a předpokládaným vydáním Navi může uběhnout 21 měsíců, tedy téměř dva rok. To je dostatečný čas na změny plánů. Jistě ne na změnu architektury, ale zcela jistě dost na to, aby mohlo být změněno rozhodnutí, jaká konfigurace čipu půjde do sériové výroby. V každé generaci totiž vznikají i různé prototypy a konfigurace, které se nikdy na pulty nedostanou - jejich návrhy a vzorky ale existují a rozhodnutí, který z nich půjde na trh, lze do určité fáze příprav změnit. Pokud by tedy kompetentní osoba v AMD rozhodla, že se škálovatelnost je u grafických čipů zatím příliš riskantní krok a rozhodla se na architektuře Navi postavit monolit, zřejmě by se taková změna za necelé dva roky stihnout dala. Tím samozřejmě netvrdím, že k něčemu podobnému muselo dojít, pouze to, že to technologicky možné je.

Prozatím ale ovladač hovoří pouze o jednom čipu, Navi 10. Hypotetické škálování, skládání z křemíkových modulů, má v případě grafických čipů své specifika, která jsou jiná než ve světě procesorů. V první řadě má svět procesorů výhodu v tom, že aplikace jsou optimalizované na vícejádrové procesory a jestli jsou jádra v jednom kusu křemíku nebo ve dvou, není pro aplikaci až tak zásadní, fungovat bude rovnou obojí. Naopak u GPU bylo až dosud skládání výkonu (SLI, CrossFire) dvou čipů věcí výrobce hardwaru (ovladače) a naopak aplikace žádnou speciální podporu nepřinášely. To se změnilo s DirectX 12, nicméně naprostá většina DX12 aplikací vlastní podporu pro využití více grafických čipů nepřináší, takže tudy cesta nevede. Pokud má více grafických čipů fungovat jako jeden, musí se implicitně chovat jako jeden a samotný fakt, že jde o více kusů křemíku, musí být pro aplikaci transparentní.
To je ale docela oříšek. Hypoteticky můžeme rozdělit velké monolitické GPU na dvě části, ale aby fungovaly, musejí být vzájemně propojeny stejně rychlou sběrnicí, jako v případě monolitického řešení. Vyvést tak rychlou a širokou sběrnici vně křemíku je náročné - vyžádá si to další křemík pro externí rozhraní této sběrnice, zvýší to energetické nároky a tak dále. Pro realizovatelnost a funkčnost je tedy klíčové rozdělit čip na takové části, mezi kterými neprobíhají tak intenzivní datové přenosy a pokud možno ještě navrhnout architekturu tak, aby tyto datové přenosy byly minimalizované (kapacita cache, datová komprese, hierarchie cache…).
Pokud se toto podaří, je tu paradoxně jedna výhoda. Zatímco u procesorů budou z více jader v podobě přidaných modulů s dalšími jádry profitovat pouze ty aplikace, které jsou pro běh na více jádrech navržené, v případě výše popsaného konceptu grafického čipu nebude podpora aplikace potřeba a přidáním modulu vzroste výkon ve všech aplikacích.
Jisté je zatím jen to, že s myšlenkou skládání grafických čipů z dílčích křemíkových modulů / čipletů koketuje jak AMD, tak Nvidia. Kdy první takový produkt přijde a kdo ho představí, zůstává ve hvězdách.























