
Nvidia Ampere uveden: Vše na oltář Tensor Cores

V souladu s očekáváním uvedl CEO Nvidie Jen-Hsun Huang výpočetní Ampere / GA100 a rovněž v souladu s očekáváním jde o monstrózní produkt. Nvidia zašla opět o kus dál…
Nvidia zkrátka rozevírá nůžky a rozdíly ve výpočetní verzi architektury a herní verzi architektury (která zatím ohlášená nebyla, je však potvrzena) se čím dál tím zvětšují. Pro pochopení celé situace bude hned pro začátek vhodná menší „léčba šokem“, která čitatele naladí na myšlenky a filozofii, na nichž Ampere GA100 se svými 826 mm² stojí: Ampere GA100 oproti Volta GV100 zvyšuje rozpočet tranzistorů 2,5×, ovšem charakteristiky základního výpočetního výkonu v přesnosti FP32 a FP64 stoupají pouze o 24 %. Z 15,7 TFLOPS na 19,5 TFLOPS (FP32) a ze 7,8 TFLOPS na 9,7 FLOPS. Pokud by vás zajímalo, jaký výhon vykazují raytracing jádra, RT-cores, pak je odpovědí, že nulový. Ampere GA100 je neobsahuje, šly z cesty.
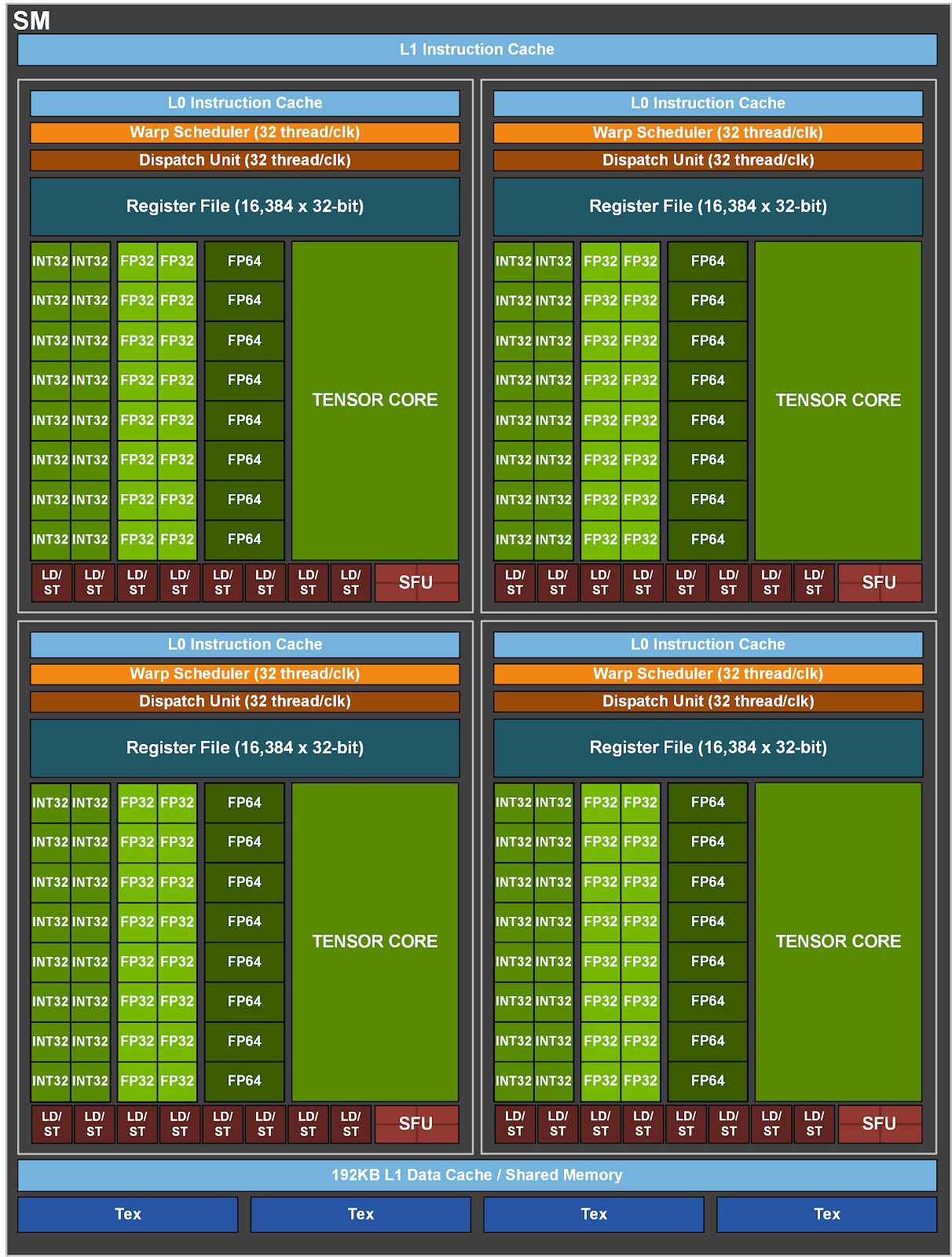
SM blok Ampere GA100: Tensor Cores vytlačila raytracing i jakoukoli možnost výraznějšího
nárůstu počtu standardních FP32 / FP64 jader
Z toho je zřejmé, že univerzální výpočetní výkon i podpora pro raytracing se pro Nvidii u výpočetního Amperu staly prakticky nepodstatnými a produkt, který tu bude přinejmenším dva roky, cílí jinam. Veškeré tranzistory navíc a většina z těch, která se ušetřila na RT-cores (a dalších prvcích), šla do Tensor Cores, jednotek na násobení matic.

Schema neořezaného jádra GA100
Zatímco minulá generace na úrovni Tensor Cores podporovala formát FP16, v případě Ampere GA100 přibyla plnohodnotná podpora pro formát FP32, dokonce i FP64 a na druhé straně pro celočíselné INT8 a INT4. K FP16 pak přibyla i podpora formátu BF16 (BFloat16).
Formát BFloat16 vznikl jako řešení určené na míru světu akcelerátorů umělé inteligence, konkrétně DL, strojového učení (Deep Learning). Je důsledkem faktu, že většina hardwaru zvládá formát FP16 2× rychleji než FP32, respektive formát FP32 2× pomaleji než FP16 a ve chvílích, kdy FP16 nebyl dostatečně přesný (z hlediska výsledku) a bylo nutné přistoupit v k využití FP32, docházelo k degradaci výkonu. Na BFloat16 můžeme nahlížet jako na formát, který vznikl z FP32 (32bit IEEE 754), který disponuje 8 bity pro dynamický rozsah (exponent) a 24 bity pro přesnost tohoto formátu (mantisa). BFloat16 zachovává 8 bitů dynamického rozsahu (exponent), ale přesnost formátu (mantisa) je snížena na 8 bitů. Z hlediska DL výpočtů není pro přesnost výsledků tolik důležitá přesnost formátu (mantisa) jako rozsah (exponent), takže výsledky výpočtů jsou podobně přesné jako při FP32, ale výkon je díky 16 bitům (8 bitů exponent + 8 bitů mantisa) podobný jako při použití FP16. Jde tedy o kompromis na míru. |
Tím to nekončí. Jen-Hsun Huang při uvádění nových architektur rád ohromuje vysokými čísly, v posledních generacích hovořil o nárůstech výkonu nebo energetické efektivity v násobku 5-25. Ani tentokrát tomu nebylo jinak a Ampere má přinést dvacetinásobný nárůst výkonu oproti generaci Volta. Týká se kombinace dvou prvků. Tím prvním je plná podpora FP32 na úrovni Tensor Cores. Z ní vychází desetinásobné zrychlení. Dané je ovšem tím, že když stejnou úlohu zadáme Volta GV100, nemůže ji provádět na Tensor Cores, protože ta FP32 nepodporují (jen částečně pro sčítání) a musí ji provádět standardními (klasickými) FP32 jednotkami, které na tyto operace nejsou optimalizované. V důsledku toho u Volty dojde k desetinásobnému zpomalení, v jehož důsledku je Ampere 10× rychlejší.

Pro dosažení oné dvacítky je potřeba ještě dvojnásobek. Ten se týká přístupu, který Nvidia nazývá jako sparsity nebo sparse, tedy jakási řídkost. Vychází z toho, že v určité fázi strojového učení (deep learning) se stává vliv některých váhových proměnných (weights) zanedbatelný a pouze část má reálný dopad na výslednou aplikaci (inference). Pokud toho daný systém dokáže využít, může benefitovat ze schopnosti architektury Ampere seškrtat při tréningu váhové proměnné v poměru 4:2 (z každých čtyř anulovat dvě), tím klesne objem dat na polovinu a Tensor Core dosáhne efektivně dvojnásobného výkonu. Nvidia uznává, že teoretické hodnoty (dvacetinásobku) nebude obvykle dosaženo, ale máme alespoň vysvětleno, jak Jen-Hsun Huang přišel k této hodnotě.

Výše dimenzovaným Tensor Cores se samozřejmě musely přizpůsobit i cache, takže kapacita L2 stoupla z 6144 KB na 40960 KB a tzv. sdílenou paměť (shared memory) lze nastavit z původní kapacity až 96 KB na současných až 164 KB.
Tolik k největším posunům architektury a tomu nejpozitivnějšímu. Nyní se podíváme na to, co už není tak optimistické. V úvodu bylo řečeno, že počet tranzistorů a denzita stoupl y na 2,5-násobek oproti Voltě. 2,5× vyšší denzita je větší posun, než s jakým přišla při raném nasazení 7nm procesu AMD; má to ovšem několik háčků. Zatímco 12nm Volta ve svém nejzdařilejším provedení zvládala dosahovat boostu až 1600 MHz při TDP 250 wattů, 7nm Ampere GA100 v nyní uvedeném provedení A100 dosahuje boostu 1410 MHz při TDP 400 wattů. Boost 1410 MHz je dokonce nižší než u 16nm generace Pascal P100 (1480 MHz).
| Nvidia Tesla P100 | Nvidia Tesla V100 | Nvidia A100 | |
|---|---|---|---|
| GPU | GP100 | GV100 | GA100 |
| architektura | Pascal | Volta | Ampere |
| formát | SXM | SXM2 | SXM4 |
| SM | 56 | 80 | 108 |
| TPC | 28 | 40 | 54 |
| FP32 jader / SM | 64 | 64 | 64 |
| FP32 jader / GPU (celkem) | 3584 | 5120 | 6912 |
| FP64 jader / SM | 32 | 32 | 32 |
| FP64 jader / GPU (celkem) | 1792 | 2560 | 3456 |
| INT32 jader / SM | 64 | 64 | |
| INT32 jader / GPU (celkem) | 5120 | 6912 | |
| Tensor Cores / SM | 8 | 4 | |
| Tensor Cores / GPU | 640 | 432 | |
| GPU Boost Clock | 1480 MHz | 1530 MHz | 1410 MHz |
| ↓↓↓ T(FL)OPS ↓↓↓ | |||
| FP16 tensor (FP16 acc) | 125 | 312/624* | |
| FP16 tensor (FP32 acc) | 125 | 312/624* | |
| BF16 tensor (FP32 acc) | 312/624* | ||
| TF32 tensor | 156/312* | ||
| FP64 tensor | 19,5 | ||
| INT8 tensor | 624/1248* | ||
| INT4 tensor | 1248/2496* | ||
| FP16 | 21,2 | 31,4 | 78 |
| BF16 | 39 | ||
| FP32 | 10,6 | 15,7 | 19,5 |
| FP64 | 5,3 | 7,8 | 9,7 |
| INT32 | 15,7 | 19,5 | |
| ↑↑↑ T(FL)OPS ↑↑↑ | |||
| texturovacích jednotek | 224 | 320 | 432 |
| sběrnice | 4096bit HBM2 | 4096bit HBM2 | 5120bit HBM2 |
| kapacita paměti | 16 GB | 32 GB / 16 GB | 40 GB |
| HBM | 1,4 GHz | 1,755 GHz | 2,43 GHz |
| paměť. propustnost | 720 GB/s | 900 GB/s | 1555 GB/s |
| L2 Cache | 4096 KB | 6144 KB | 40960 KB |
| Shared Memory / SM | 64 KB | ≤ 96 KB | ≤ 164 KB |
| Register File / SM | 256 KB | 256 KB | 256 KB |
| Register File / GPU (celkem) | 14336 KB | 20480 KB | 27648 KB |
| TDP | 300 W | 300 W | 400 W |
| Transistorů | 15,3 mld. | 21,1 mld. | 54,2 mld. |
| plocha GPU | 610 mm² | 815 mm² | 826 mm² |
| proces (TSMC) | 16 nm FinFET+ | 12 nm FFN | 7 nm N7 |
* s využitím sparsity / Sparse Tensor Cores
zeleně a tučně zvýrazněn dvacetinásobný nárůst výkonu
Nvidia si tedy stanovila cíl dostat do 7nm čipu Tensor Cores vybavené výše popsaným arzenálem technologií. K tomu ovšem potřebovala využít papírové možnosti denzity 7nm procesu prakticky nadoraz. Tím ovšem šla na oltář Tensor Cores energetická efektivita (čím více tranzistorů na malé ploše - tím více tepla je potřeba odvést a tím obtížněji se toto teplo odvádí), což muselo být kompenzováno nižšími takty. Nvidia cíli nepodřídila jen vysokou denzitu. Jak již bylo řečeno, nestoupl nijak významně klasický FP32 / FP64 výkon, byly vyškrtnuty jednotky pro raytracing, dále byl vyškrtnut obvod pro akceleraci komprese videa NVENC a také obrazové výstupy (pokud situaci chápu správně, tak na úrovni návrhu čipu). GPU GA100 se navíc v uvedeném provedení jeví jako výrazněji ořezané než GV100, která z 5376 stream-procesorů disponovala aktivními 5120.

V případě Nvidia A100 pochází aktivních 6912 stream-procesorů z celkových 8192, což znamená vypnutí více než 15 % potenciálu čipu. Dále je deaktivován jeden z šesti paměťových HBM2 kanálů. Z teoreticky možné 6144bit sběrnice je aktivní 5120bit část a v důsledku toho je z možných 48 GB paměti k dispozici 40 GB (a z možné propustnosti 1866 GB/s je využito 1555 GB/s). Skutečně se zdá, že Nvidia měla o 7nm procesu trochu jiné představy a návrh jádra dimenzovala na úroveň, kterou nelze bez nezanedbatelných obětí zrealizovat. Aby nedošlo k omylu - Ampere A100 je v tuto chvíli a svého typu produkt, který nemá v akceleraci AI přímou konkurenci a popsaná ořezání na tom nic nemění. Stejně tak ale samotný fakt konkurenceschopnosti nic nemění na tom, že s tímto návrhem Nvidia plánovala cílit (ještě) výš, což však nebylo možné.
V tomto kontextu stojí za zmínku, že podle dostupných informací je jádro Ampere GA100 vyrobeno na první generaci 7nm procesu TSMC (N7, jako například samostatné Ryzeny nebo Vega 20 z konce roku 2018), nikoli na vylepšené N7P nebo N7+ s EUV. Nvidia, ačkoli již bylo na výběr ze tří variant procesu, zvolila nejlevnější.

Vrátíme-li se ke konceptu jádra, lze říct, že s Ampere se z univerzálního výpočetního řešení, jakým bylo jádro Pascal P100 nebo ještě Volta V100, stává ze „stovkových“ čipů úzce zaměřené řešení, akcelerátor AI. Ne že by výkon v FP32 / FP64 byl nízký - on stoupl. Ale s ohledem na cenu nelze očekávat, že by se pro obecné výpočetní využití (míněno mimo AI) Ampere vyplatil. Vyplatí se jako specializované řešení pro AI. Tam míří i systém na 8× Ampere A100 postavený, kterým se CEO společnosti pochlubil s předstihem v kuchyni.

Systém s osmi A100 a - perlička - dvěma procesory AMD Epyc (Rome) 7742 s 64 jádry každý, vyjde na $199 000 a můžete si jej objednat již nyní. Těžko říct, co Nvidii vedlo k volbě procesoru od AMD. Respektive těžko říct, co převážilo - zda-li podpora PCIe 4.0 (kterou Intel nenabízí), nebo poměr cena / výkon (který Intel nenabízí), nebo takový počet jader, který by systém nebrzdil (který Intel nenabízí).
Zdroje:
Nvidia, VideoCardz aj.























