
Nvidia Hopper: Nejvýkonnější AI akcelerátor na světě, až 6× rychlejší než Ampere

Zdroj: Nvidia
Říká se, že CEO Nvidie Jen-Hsun Huang je tak trochu megaloman. Na to může mít každý vlastní názor, faktem však zůstává, že Nvidia za včerejší den vydala 34 tiskových zpráv…
Nvidia si skutečně dala záležet, aby na GTC ohromila. Výpočetní GPU Hopper GH100 je nakonec (dokonce) 4nm (TSMC), skládá se z 80 miliard tranzistorů, používá HBM3, ve většině případů dosahuje 3× vyššího výkonu než Ampere GA100, ovšem v některých specifických situacích může jít až o 2-3násobek této hodnoty.
Komu by bylo 80 miliard tranzistorů málo, může se obdivovat switchi Spectrum-4, který jako první podporuje 400G, rovněž využije 4nm proces a stojí rovnou na 100 miliardách tranzistorů. Vzorky začne Nvidia partnerům dodávat na konci čtvrtého kvartálu letošního roku.
Superlativy padaly i ve vztahu k CPU Nvidia Grace chystaném na první pololetí 2023. Bude vybaveno 900 GB/s rozhraním k propojení například s druhým CPU Grace. V takovém případě vzniká tzv. Grace Superchip s celkem 144 procesorovými jádry, LPDDR5X sběrnicí o celkové propustnosti až 1 TB/s, 396MB cache a celkovým TDP 500 wattů. Nvidia očekává, že v době vydání bude dosahovat 2× vyšší energetické efektivity než ostatní procesory. Namísto druhého CPU lze připojit GPU Hopper. Případně ke dvojici CPU Grace až osm GPU Hopper.

Grace Hopper, modul spojující CPU Grace a GPU Hopper chystaný na rok 2023
K tomu Jen-Hsun Huang ohlásil řadu projektů týkajících se AI, samořídících (autonomních) automobilů, omniverse, sítí (zde stojí za zmínku otevření NVLINK) a jiných. Podrobnosti najdete ve zmíněných 34 tiskových zprávách.
Hopper GH100
Nyní se vraťme k Hopper. Jak se poslední týdny proslýchalo, není jádro GH100 složeno z čipletů. Jde o monolit nesoucí 80 miliard tranzistorů, což je mezigeneračně téměř 50% navýšení. Plocha je nakonec o chlup nižší než u Ampere GA100 (814 mm²), což je důsledkem nečekaného použití 4nm výroby (při 5nm by se plocha blížila 900 mm², takže je možné, že Nvidia zvolila pokročilejší proces v průběhu vývoje. 4nm proces TSMC je totiž vylepšená verze 5nm výroby.
Nvidia neupřesnila verzi - TSMC zatím ohlásila tři. První, nazvaná N4, se oproti 5nm procesu liší jen o 6 % vyšší denzitou a o 4-5 % vyšší takty. U té by k zahájení sériové výroby mělo dojít zhruba v současné době. Druhá, nazvaná N4P, ke zmíněné denzitě nabízí navíc o 11 % vyšší takty nebo o 22 % nižší spotřebu. Tento proces by byl podstatně přínosnější, ovšem výroba vzorků nezačne dříve než ve druhém pololetí (sériová výroba asi až příští rok). Na papíře existuje i výkonnější N4X proces chystaný kompletně na příští rok s až o 15 % vyššími takty (oproti 5nm výrobě). O výběru konkrétního procesu by mohlo napovědět datum dostupnosti Hopper GH100 / Nvidia H100, ale žádné datum CEO společnosti nezmínil. Podle neoficiálních leaků však nepůjde o první pololetí letošního roku a navzdory tomuto březnovému představení by produkty neměly být široce dostupné výrazně dříve než u konkurenční CDNA 3 od AMD. To však ještě uvidíme.
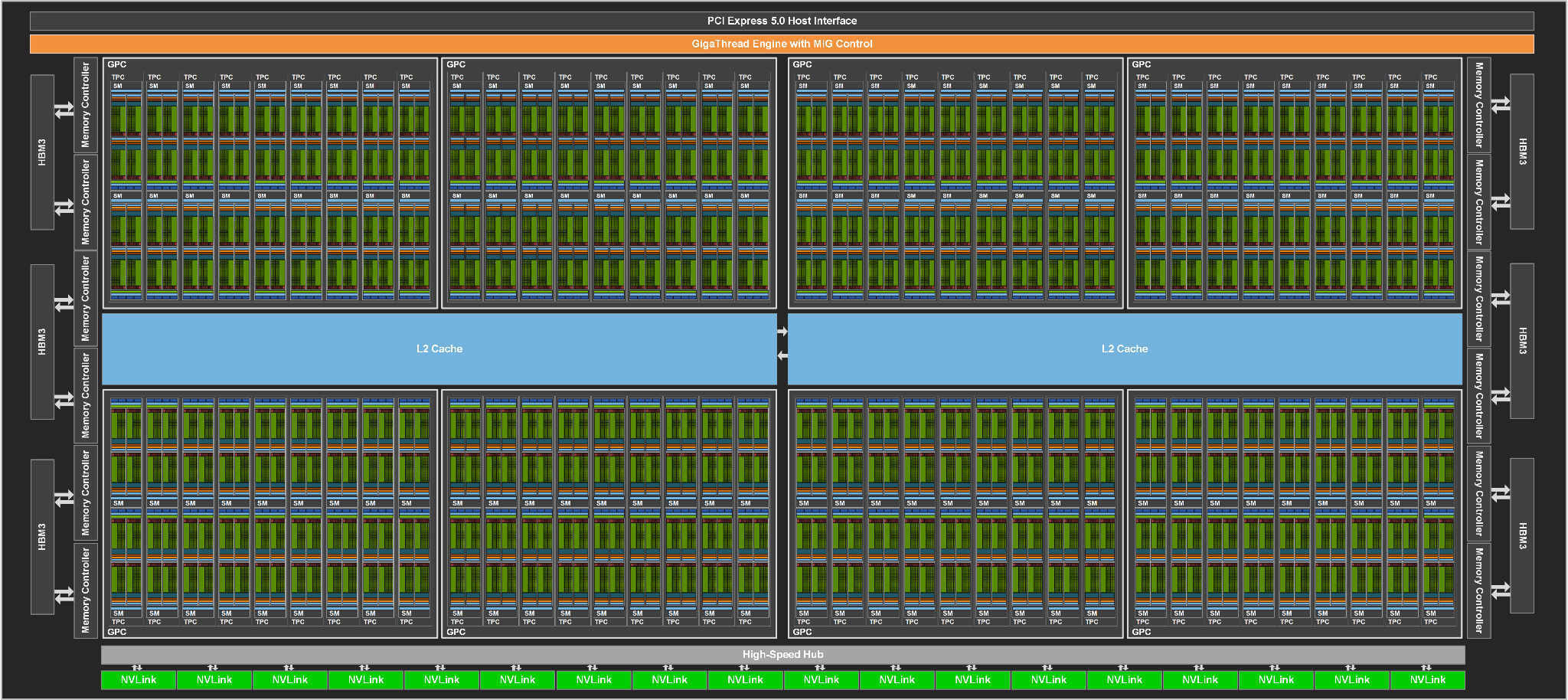
Nvidia Hopper prezentuje jako první GPU vybavené PCIe 5.0 a první GPU vyba bavené HBM 3. To je samozřejmě pravda za předpokladu, že za klíčové datum budeme považovat datum ohlášení, nikoli reálnou dostupnost. V té po stránce PCIe 5.0 nejspíš Nvidii předběhne Intel. A následně desktopová GPU samotné Nvidie a poté i AMD.
V době vydání Ampere GA100 prezentovala Nvidia toto výpočetní GPU jako univerzální řešení - jak pro akceleraci AI, tak pro HPC v klasickém slova smyslu. Za tu druhou polovinu tvrzení si odnesla oprávněnou kritiku, neboť výkonnostní posuny v ne-tenzorových operacích byly nízké a Nvidia se v tomto směru nechala záhy předběhnout řadou CDNA od AMD. S Hopper si zřejmě vzala ponaučení. Nikoli co do posunu výkonu v klasických operacích, ale v prezentaci Hopper jakožto nejvýkonnějšího AI akcelerátoru.

SM blok architektury Hopper
Aby posun výkonu nekopíroval pouze navýšení počtu funkčních jednotek a taktovacích frekvencí (ty zatím nebyly stanoveny, což by korespondovalo s očekáváním, že reálné vydání za dveřmi zdaleka není), došlo k vylepšení Tensor Cores, kterým nyní Nvidia říká Transformer Engine. Mohou využívat pro různé účely různé přesnosti, např. kombinovat výpočty v přesnosti FP16 s akumulací v přesnosti FP32 a podobně. Dále přibyla podpora přesnosti FP8, takže operace, pro které dostačuje, mohou probíhat 6,4× rychleji než původně přes FP16. Naproti tomu HPC výkon v FP16 stoupl pouze o polovinu.
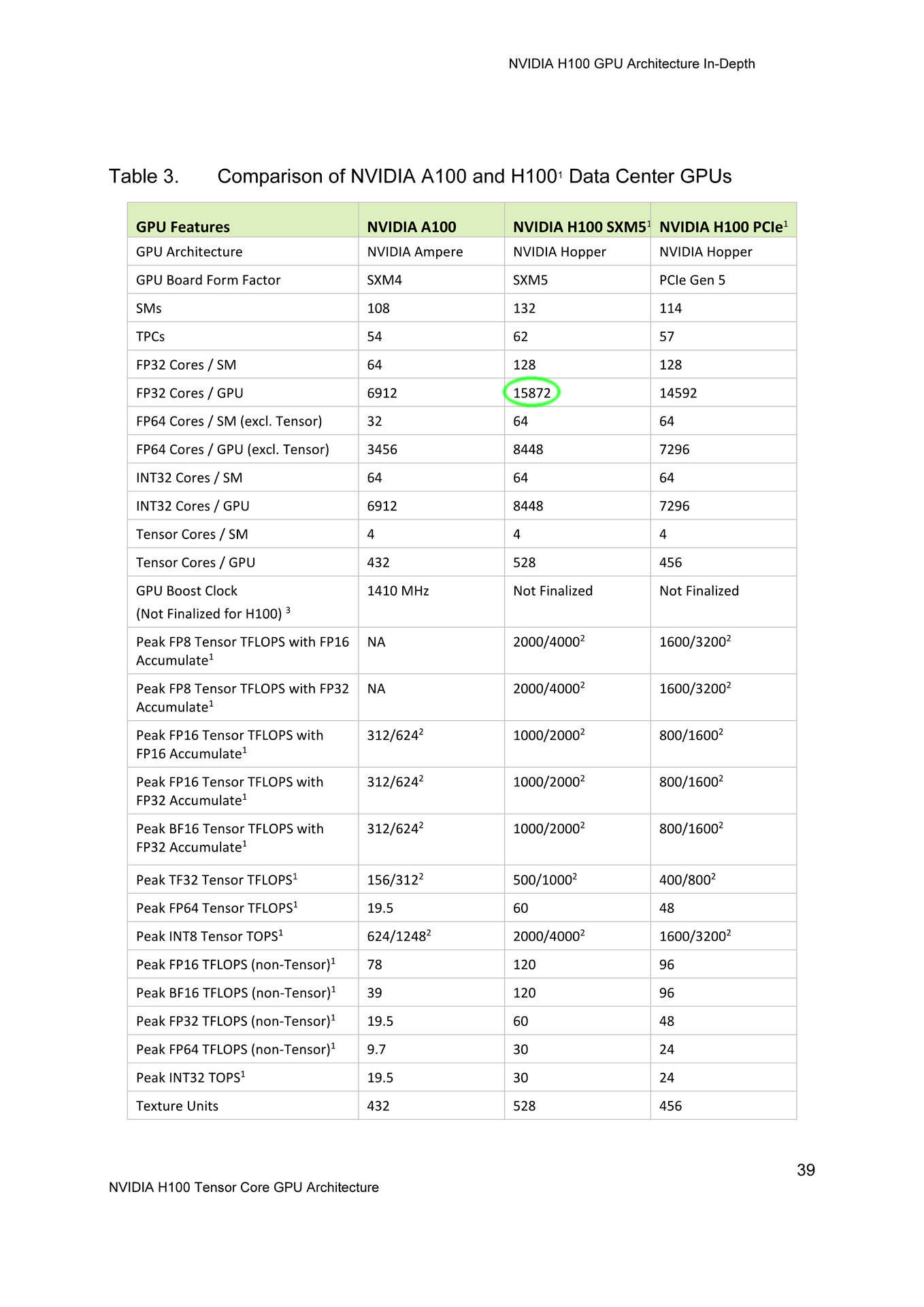
| AMD MI250X | AMD MI300 | Nvidia Tesla V100 | Nvidia A100 | Nvidia H100 | ||
|---|---|---|---|---|---|---|
| GPU | Aldebaran | Rigel | GV100 | GA100 | GH100 | |
| architektura | CDNA 2 | CDNA 3 | Volta | Ampere | Hopper | |
| formát | OAM | OAM | SXM2 | SXM4 | SXM5 | |
| CU/SM | 220 | ? | 80 | 108 | 132 | |
| FP32 jader | 14080 | ? | 5120 | 6912 | 15872 16896 | |
| FP64 jader | - | - | 2560 | 3456 | 8448 | |
| INT32 jader | - | - | 5120 | 6912 | 8448 | |
| Tensor Cores | 880 | ? | 640 | 432 | 528 | |
| takt | 1700 MHz | ? | 1530 MHz | 1410 MHz | ? | |
| ↓↓↓ T(FL)OPS ↓↓↓ | ||||||
| FP16 | 383 | ? | 31,4 | 78 | 120 | |
| BF16 | 383 | ? | 39 | 120 | ||
| FP32 | 95,7 47,8 | ? | 15,7 | 19,5 | 60 | |
| FP64 | 47,8 | ? | 7,8 | 9,7 | 30 | |
| INT4 | 383 | ? | ? | ? | ? | |
| INT8 | 383 | ? | ? | ? | ? | |
| INT16 | ? | ? | ? | ? | ? | |
| INT32 | ? | ? | 15,7 | 19,5 | 30 | |
| FP8 tensor | ? | 2000/4000* | ||||
| FP16 tensor | 383 | ? | 125 | 312/624* | 1000/2000* | |
| BF16 tensor | 383 | ? | 312/624* | 1000/2000* | ||
| FP32 tensor | 95,7 | ? | 19,5 | 60? | ||
| TF32 tensor | ? | 156/312* | 500/1000* | |||
| FP64 tensor | 95,7 | ? | 19,5 | 60 | ||
| INT8 tensor | 383 | ? | 624/1248* | 2000/4000* | ||
| INT4 tensor | ? | ? | 1248/2496* | ? | ||
| ↑↑↑ T(FL)OPS ↑↑↑ | ||||||
| TMU | -? | ? | 320 | 432 | 528 | |
| LLC | 16 MB | ? | 6 MB | 40 MB | 50 MB | |
| sběrnice | 8192bit | ? | 4096bit | 5120bit | 5120bit | |
| paměť | 128 GB | 128 GB | 32 GB / 16 GB | 40 GB | 80 GB | 80 GB |
| HBM | 3,2 GHz | ? | 1,755 GHz | 2,43 GHz | 3,2 GHz | 4,8 GHz |
| pam. prop. | 3277 GB/s | ? | 900 GB/s | 1555 GB/s | 2048 GB/s | 3072 GB/s |
| TDP | 500 W 560 W | ? | 300 W | 400 W | 700 W | |
| transistorů | 58,2 mld. | ? | 21,1 mld. | 54,2 mld. | 80 mld. | |
| plocha GPU | 2× ? | 4× ? | 815 mm² | 826 mm² | 814 mm² | |
| proces | 6 nm | 5nm | 12 nm | 7 nm | 4nm | |
| datum | 11. 2021 | 2022? | 2017 | 5. 2020 | 11. 2020 | 2022? |
S tenzorovými operacemi Nvidia utíká řadě AMD Instinct MI200, s HPC výkonem zůstává trochu ve skluzu. Je však potřeba dodat, že v praxi je vysoký HPC výkon řady MI200 v některých případech limitován paměťovou propustností, takže praktický rozdíl může být nižší než teoretický a Hopper může v některých situacích pomáhat velká cache. Datová propustnost Hopper je paradoxně o chlup nižší než u Instinctu a to HBM3 navzdory. Paměťová sběrnice totiž rozšířena nebyla a zůstává fyzicky 6144bit, z čehož je aktivní 5120bit část (pět kanálů ze šesti).
Krom Nvidia A100 v provedení 700W SXM5 modulu (jak popisuje tabulka), připravila Nvidia ještě verzi pro PCIe 5.0. Liší se nižším počtem aktivních jednotek (14592 namísto 15872 16896), nižšími takty, pamětmi HBM2e namísto HBM3 a TDP sníženým na 350 wattů.
Aktualizace 23. 3. 2022: Při odhalení 22. 3. 2022 uváděly specifikace pro Nvidia H100 SXM5 15872 stream-procesorů, následně Nvidia hodnotu změnila na 16896. Obě verze dokumentů jsou navzdory rozdílům označené jako „version 1.0“:

Videostream:























