
Exkluzivně: Patent AMD potvrzuje GCN schopnou běžet na asynchronních taktech

Nový patent AMD popisuje technologii, která umožňuje, aby různé stream-procesory GPU běžely na různých taktech, případně aby se nevyužité vypnuly a umožnily přetaktování jiných.
Tento článek můžete brát jako pokračování „předchozího dílu“ z dubna. Možná ale oceníte krátkou rekapitulaci: Médii a diskusemi tehdy již nějakou dobu kolovaly zvěsti, že AMD pracuje na verzi architektury GCN s proměnlivou šířkou SIMD bloků. SIMD jsou skupiny 16 stream-procesorů, které v počtu čtyř (s doplněním texturovacích jednotek, registrů a dalších funkčních prvků) tvoří blok zvaný Compute Unit (CU), případně GCN. SIMD mají v současnosti šířku 16 (stream-procesorů) a bez bližšího vysvětlení si lze jen těžko představit situaci, jak by hardwarový prvek pevně ukotvený v křemíku mohl nabývat proměnlivé šířky.
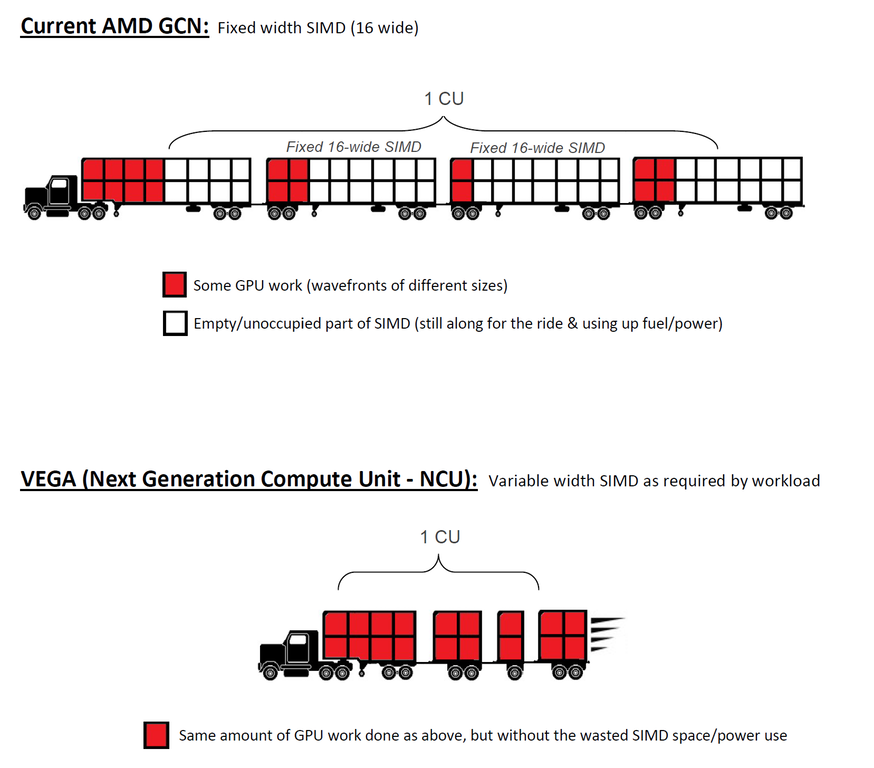
První smysluplné vysvětlení tehdy nabídl uživatel Beyond3D fóra Jawed. Narazil na zdánlivě nesouvisející patent, který z hlediska řízení čipu popisuje, jak realizovat dynamické vlnoplochy (wavefronts) pro výpočetní jednotky. Uvědomil si, že souvisí se stejným problémem, jen popisuje řešení jiné jeho části a navíc, že pojetí tohoto tématu je trochu jiné, než předpokládaly zmíněné spekulace. SIMD by totiž zůstal široký celých 16, ale podle potřeby by buďto celý nebo jednotlivé linky mohly být podtaktovány nebo úplně zastaveny (např. v celkem 5 stupních) a tím efektivně změněna šířka daného SIMD. Přínos by byl především energetický: Vypnutím či zpomalením nevyužitých nebo málo využitých částí by se ušetřila elektrická energie a tím se snížily energetické nároky čipu.
Jawed měl zřejmě pravdu, protože nyní v červnu byl zveřejněn další patent AMD, který se opět věnuje tomuto problému, ale už nikoli z hlediska řízení čipu, ale z hlediska řízení spotřeby. Popisuje technologii ke správě energie jednotlivých linek včetně možnosti jejich úplného odpojení. Počítá i s tím, že energie z odpojených linek by mohla být rozdělena mezi zbývající aktivní linky a to jak rovnoměrně, tak i nerovnoměrně. Z toho vyplývá, že zbývající linky by mohly být s využitím ušetřené energie „přetaktovány“ nad svoji nominální hodnotu. Tím by byla část kódu, která nedokáže efektivně využít celou šířku SIMD, zpracována rychleji (bylo-li by to žádané). Případně by prioritu dostala jen část čipu, která by zpracovávaly kritickou úlohu, u níž je žádoucí vyšší priorita. To by bylo využitelné i pro další zefektivnění asynchronních výpočtů.
Ačkoli výše znázorněné náklaďáčkové schéma (jehož původ je neznámý) hovoří o architektuře Vega, je zcela možné, že se popsané technologie týkají architektury Navi, nebo některého jejího nástupce. To už z patentů vyčíst nelze. Můžeme říct jen tolik, že dosud zveřejněné oficiální materiály k architektuře Vega o této ani podobné technologii neinformují.
Zdroje:























