
Exkluzivně: AMD připravuje GCN schopnou běžet na asynchronních taktech

Loni v říjnu se objevilo několik neoficiálních zpráv o údajné změně v architektuře GCN, která se týká uspořádání výpočetních bloků. Ve dvou bodech: 1. Informace byla pravdivá. 2. Ale špatně podaná.
Pokud se mluví o architektuře GCN, pak může tato zkratka nabývat dvou odlišných významů. V širším smyslu je tím chápána kompletní architektura grafického čipu se vším všudy (výpočetní část, ROP, řadič, multimediální obvody…) v užším smyslu je tímto označením chápána jen výpočetní část čipu, která integruje i texturovací jednotky. Právě o té bude nyní řeč.

Diagram jádra Tahiti (Radeon HD 7970), černě bloky GCN (= CU), každý s 64 stream-procesory
Všechny grafické čipy s architekturou GCN mají výpočetní jednotky (Stream-Procesory, SP) uspořádané v blocích po 64, které bývají označované jako CU, Compute Unit nebo GCN blok. Tato skupina 64 stream-procesorů je dále rozdělena do čtyř bloků po 16. Těmto blokům se říká SIMD (Single Instruction, Multiple Data), což samo o sobě naznačuje, jakým způsobem fungují.

GCN blok (CU), červeně 64 stream-procesorů ve 4 skupinách po 16 (SIMD); plus jedna skalární jednotka
Z výše zobrazeného schématu se zaměříme jen na červené jednotky, tedy stream-procesory uspořádané ve čtyřech SIMD a skalární jednotku. SIMD obsahují 16 stream-procesorů a jak již bylo řečeno, provádí jednu instrukci nad různými daty. Za běhu může být vždy obsazeno všech 16 stream-procesorů, nebo může být obsazena jen jejich část. To už záleží na objemu dat, nad kterým je konkrétní instrukce prováděna (pokud je velmi malý, neobsadí SIMD plně).
V říjnu minulého roku zveřejnil web WCCFTech výše znázorněné schéma, podle kterého AMD plánuje architekturu GCN upravit tak, že nabídne SIMD o různé šířce, tzn. pro různě velké datové objemy. Tyto zprávy provázely obecné řeči o zvýšení efektivity, ale ani náznakem nedošlo k vysvětlení, jak by něco podobného měla (nebo mohla) AMD uskutečnit. WCCFTech navíc dával tuto architektonickou změnu do spojitosti již s architekturou Vega:

O nějakou dobu později se v diskusi na reddit objevilo podobné schéma, které předkládalo více-méně tutéž myšlenku, ale opět žádné vysvětlení, ani původ informace:
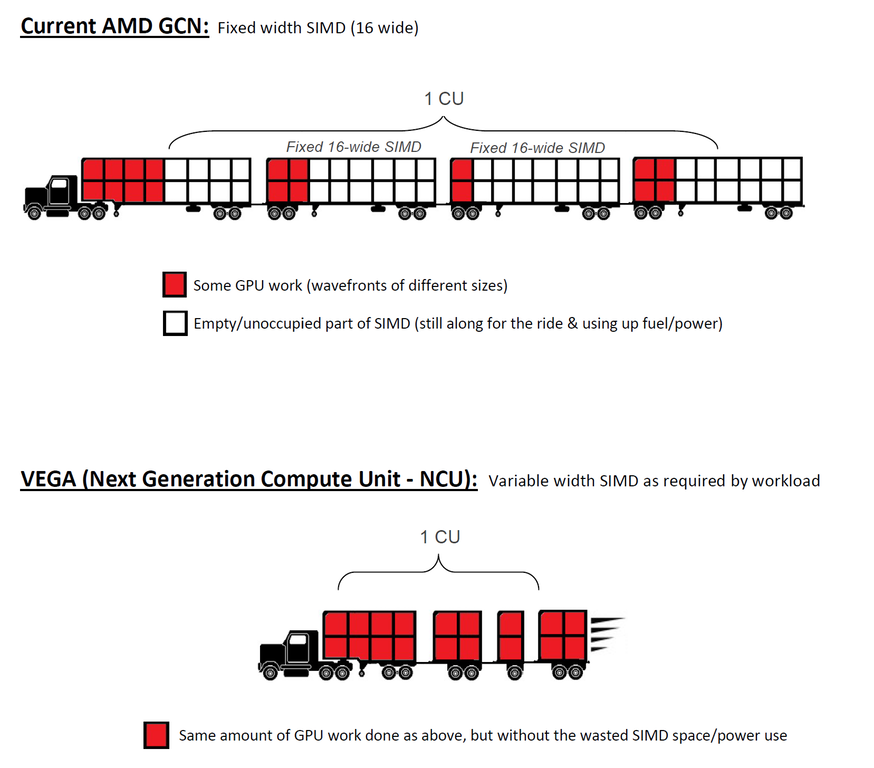
S půlročním odstupem můžeme konstatovat známé „na každém šprochu pravdy trochu“. Došlo totiž ke znovuobjevení patentu AMD, který skutečně podobnou technologii popisuje. Patent samotný byl známý již od loňského roku, ale je poměrně obecně formulován, takže nikoho nenapadlo, jak konkrétně by měla být technologie implementována, aby mohla fungovat a hlavně aby ji bylo možné implementovat do konkrétních grafických čipů. S odstupem času si uživatel Jawed z diskusního fóra Beyond 3D uvědomil, že existuje jeden způsob, který je až překvapivě jednoduchý a přitom funkční a implementovatelný do architektury GCN. Spočívá v prostém nastavení různých taktů pro bloky SIMD.
Bloky SIMD nemusejí mít fyzicky různou šířku, ani není třeba řešit jejich variabilní šířku na úrovni hardwaru. Mohou být hardwarově prakticky stejné jako nyní. Zúžení jednoho SIMD ze 16 na kupříkladu 8 lze velmi snadno realizovat úpravou taktovací frekvence určitých linek tohoto SIMD oproti ostatním. Jawed jako příklad uvádí 5 stavů, mezi kterými by se mohlo podle potřeby přepínat:
- 100 % maxima (16)
- 75% maxima (12)
- 50% maxima (8)
- 25% maxima (4)
- zcela vypnuto
Teoreticky je možné připustit i jiné hodnoty, například :
- plná (16)
- 1/2 (8)
- 1/4 (4)
- 1/8 (2)
- zcela vypnuto (?)
Poslední možnost je s otazníkem, protože schéma možnost úplného vypnutí neilustruje. To už je ale z hlediska konceptu technologie jako takové jen detail.
K čemu by možnost snižování frekvencí na úrovni jednotlivých SIMD byla? V současnosti, i když dojde na využití jen poloviny kapacity SIMD, běží na plných taktech a její spotřeba je podobná, jako kdyby byla plně využita. Pokud můžeme snížit takt, znamená to, že klesne spotřeba. Takto ušetřená energie může být využita buďto ke snížení TDP čipu, nebo naopak k nastavení vyšší maximální frekvence při stejném TDP. Což by znamenalo, že bod „1.“, tedy plná frekvence, může být s použitím této technologie vyšší než bez jejího použití. Jinými slovy čip může běžet na vyšším taktu, nabídnout vyšší výkon a to při stejném TDP. Výsledkem je pak vyšší energetická efektivita.
Poslední a zásadní otázka je, u jaké generace grafických čipů může AMD tuto technologii využít. Říjnová zpráva WCCFTech ji zmiňovala v souvislosti s Vegou. Oficiální prezentace Vegy ale nic podobného neuvádějí a s ohledem na loňskou publikaci patentu skutečně nemusí jít o technologii, která by s Vegou souvisela. Teoreticky může přijít s další generací, architekturou Navi, nebo jejím nástupcem.
Zdroje:























