
Rozbor: AMD vydává Kaveri, APU s HSA jádry Steamroller a GCN

Tímto okamžikem je oficiálně uvedeno APU Kaveri, patrně nejdéle očekávaný produkt AMD posledního roku. Dnes se dozvíte o jeho architektuře a desktopových modelech, které vycházejí jako první…
Kapitoly článků
2. Grafické jádro a HSA
Grafická část - GCN+ a „výpočetní jednotky“
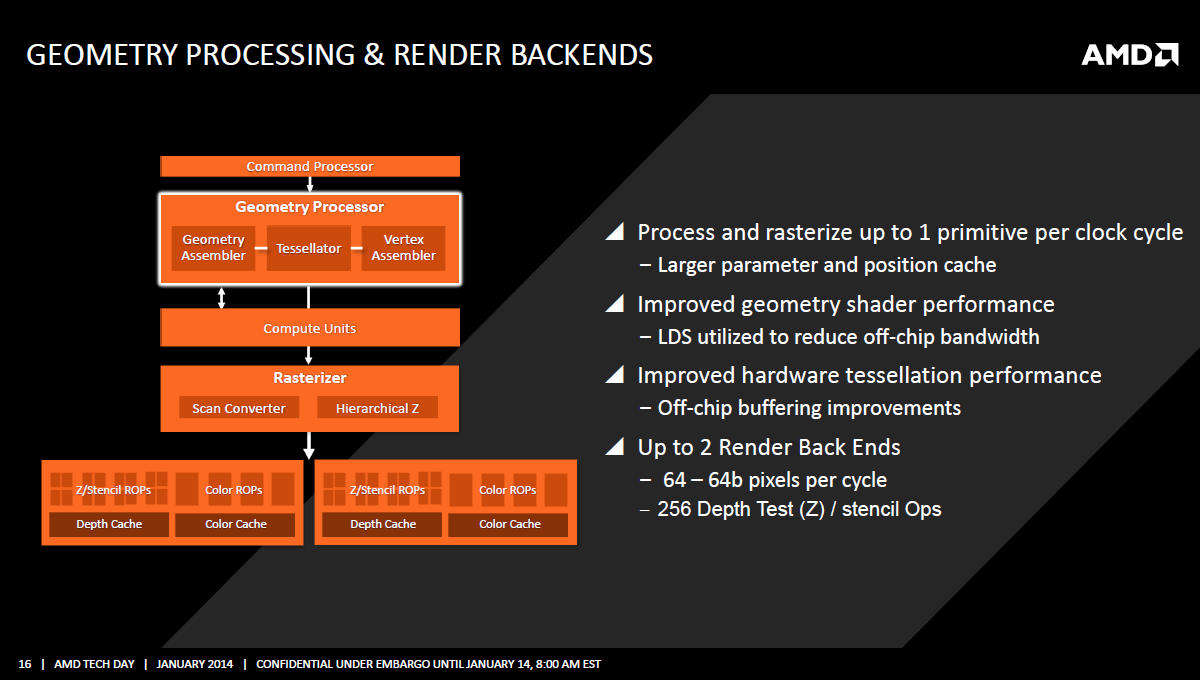
Kaveri je téměř z poloviny (přesně ze 47 %) tvořena grafickým jádrem. To patří do generace GCN+, tedy na tutéž úroveň, jako nejnovější grafická jádra Bonaire a Hawaii (Radeon R7 260/260X a R9 290/290X). Znamená to, že nechybí žádné vylepšení, o kterém jsme mluvili při vydání GPU Hawaii.

V první řadě jde o efektivnější teselaci a geometry shading, tedy mírně vyšší výkon geometrické jednotky při stejné taktovací frekvenci. Zlepšení vychází ze tří prvků: Větších cache, využití LDS pro snížení objemů datových přenosů mimo čip a nakonec je to vylepšený buffering pro přenosy čip-paměť. Ze změn, které přímo ovlivňují grafický výkon, to jsou i mírně vylepšené ROP.
Do druhé skupiny patří výpočetní zlepšení, které ale mohou mít i nepřímý vliv na grafický výkon. Na úrovni výpočetních jednotek (CU) jde především o zvýšení přesnosti pro operace LOG/EXP na 1ULP. V praxi to může přinést významné zrychlení v OpenCL, protože dosavadní čipy architektury GCN prováděly tyto operace buďto s nižší přesností (a rychle), nebo s plnou přesností, ale velmi pomalu.
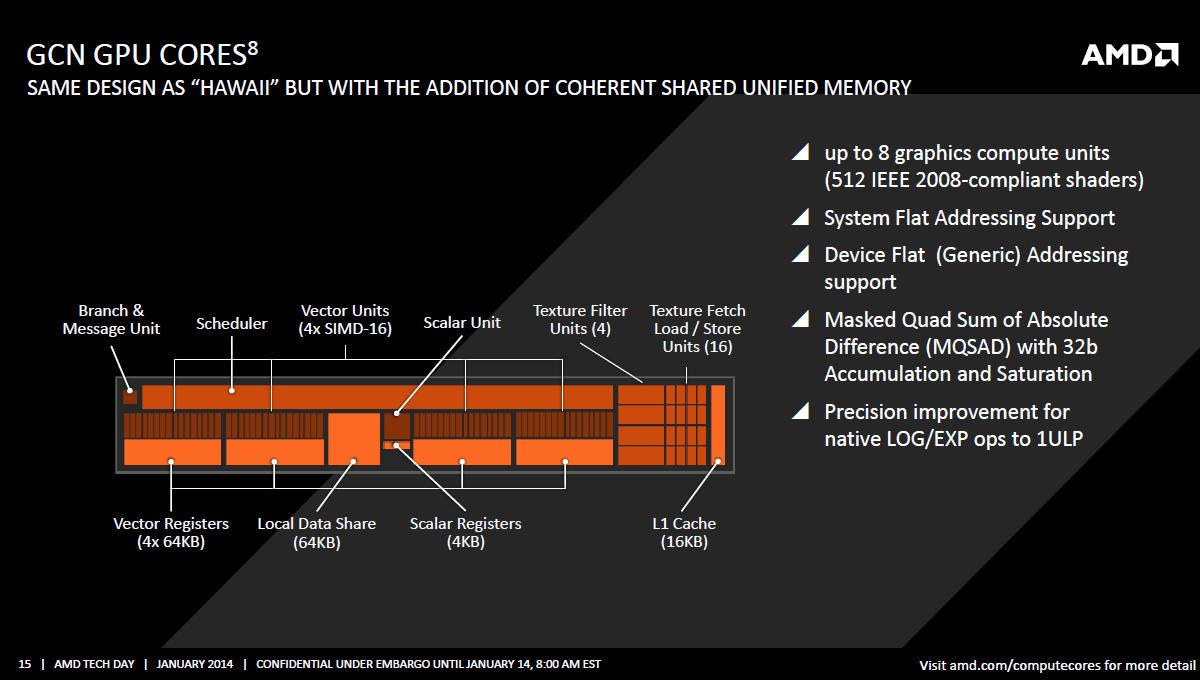
Pokud to řekneme ještě jednodušeji, defaultem pro OpenCL je plná přesnost, což znamenalo nízký výkon. Rychlejší způsob zpracování byl použit výhradně tehdy, pokud programátor specifikoval, že mu na přesnosti výpočtu nesejde.

Druhá část výpočetních optimalizací souvisí s jejich řízením. Grafická jádra nové generace herních konzolí (Playstation 4, Xbox One) vybavila AMD osmi ACE (čtyřnásobkem oproti Radeonů HD 7900) a totéž se týká i GPU Hawaii a APU Kaveri. ACE (asynchronous compute engine) jsou zodpovědné za efektivní nakládání s výpočetními úkoly. Mají na zodpovědnost převzetí úlohy, její rozdělení a provedení prostřednictvím dostupných výpočetních bloků. ACE mohou fungovat nezávisle, umožňují efektivní multi-tasking, rozhodují o alokaci zdrojů, řízení priority a podobně. Přestože je GCN (jak je v případě grafických čipů zvykem) in-order architektura, mohou ACE úpravou priority ovlivnit, v jakém pořadí budou úlohy dokončeny.
Třetí hromádka grafických změn je už jakási všehochuť. Jednou z nejdůležitějších je podpora XDMA, tedy lépe synchronizovaného CrossFire bez můstku. Absence můstku je zrovna u APU vedlejší, ale zlepšení synchronizace je docela klíčová záležitost. AMD navíc přislíbila, že Catalysta 14.1 beta přinesou frame-pacing (rozšířené řízení synchronizace) i pro kombinaci APU a Radeonů R7. Právě efektivní párování APU Kaveri s Radeony R7 má být jednou ze zásadních výhod nové platformy. Radeony R7 240 a 250 umožňují efektivně zdvojnásobit grafický výkon, jaký nabízí samotné APU. Možnost využití potenciálu integrované grafiky i po doplnění samostatné, je něco, co v současnosti konkurence nemůže nabídnout a AMD to dává náležitě najevo.
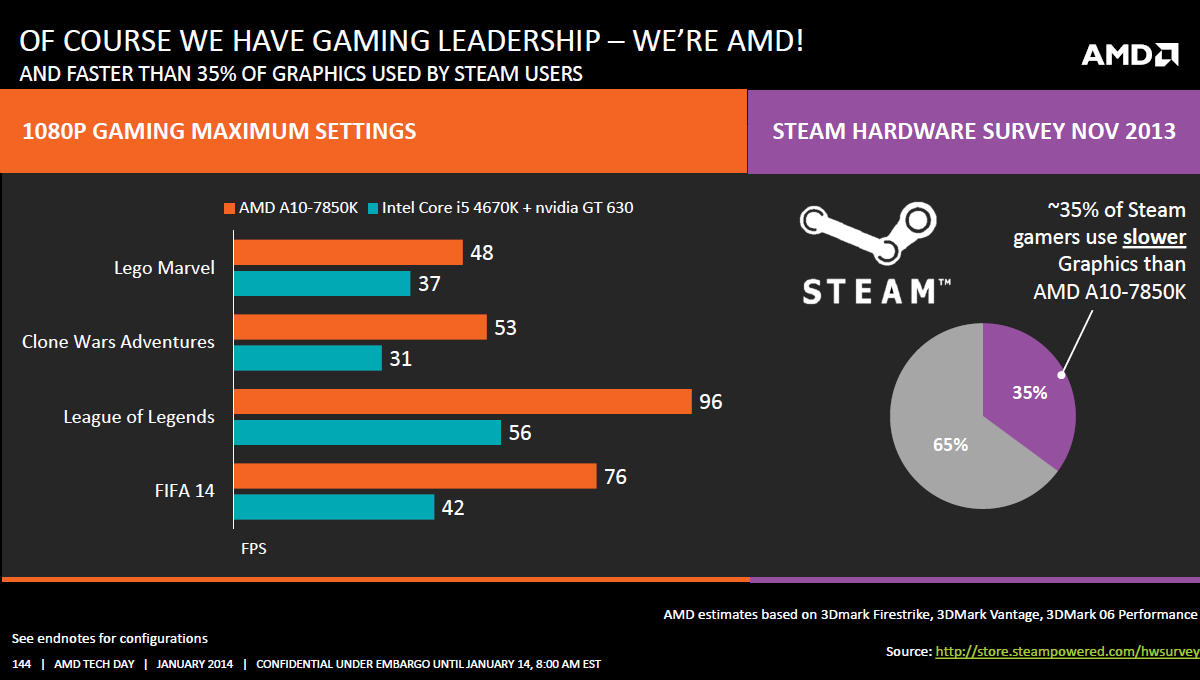
Podle listopadových statistik více než třetina uživatelů Steamu používá grafickou kartu pomalejší, než jaká je integrována v rámci Kaveri, což znamená nemalý tržní potenciál. Samozřejmě to už neříká nic o tom, jak ho AMD dokáže využít.
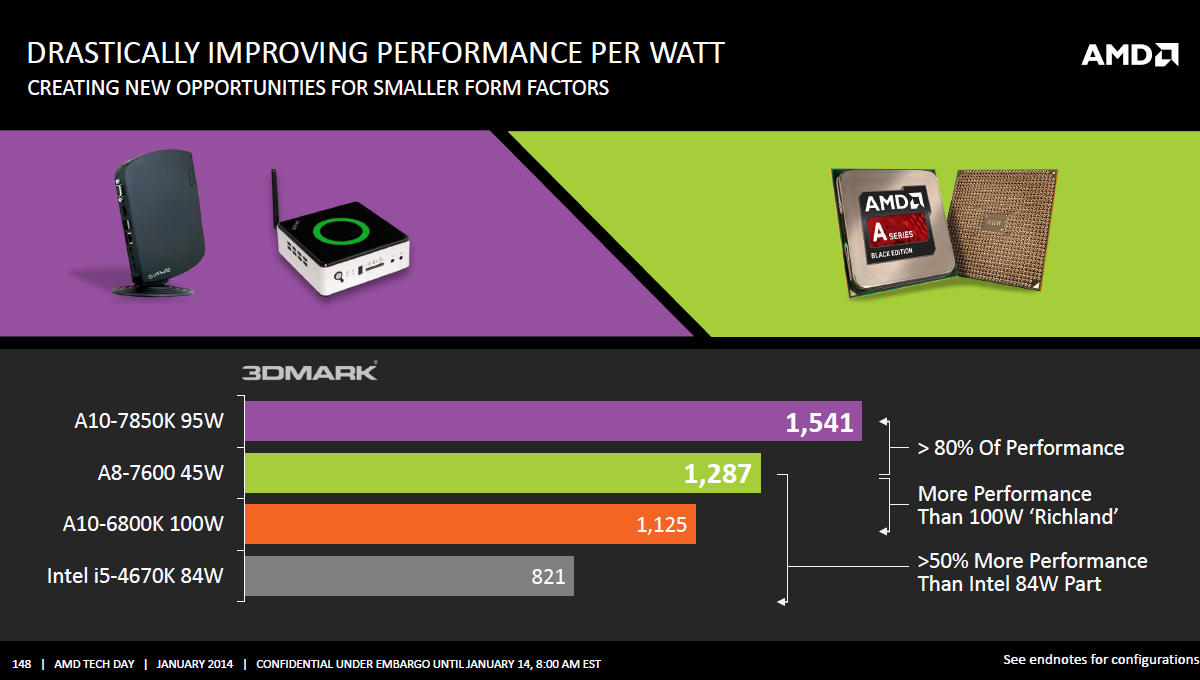
V souvislosti s TDP jsme zmiňovali, že největší nárůst energetické efektivity budou vykazovat modely s nižším než 95W TDP. Srovnávací graf ukazuje konkrétně 45W Kaveri, která dosahuje vyššího grafického výkonu než 100W Richland A10-6800K, top model předešlé generace.
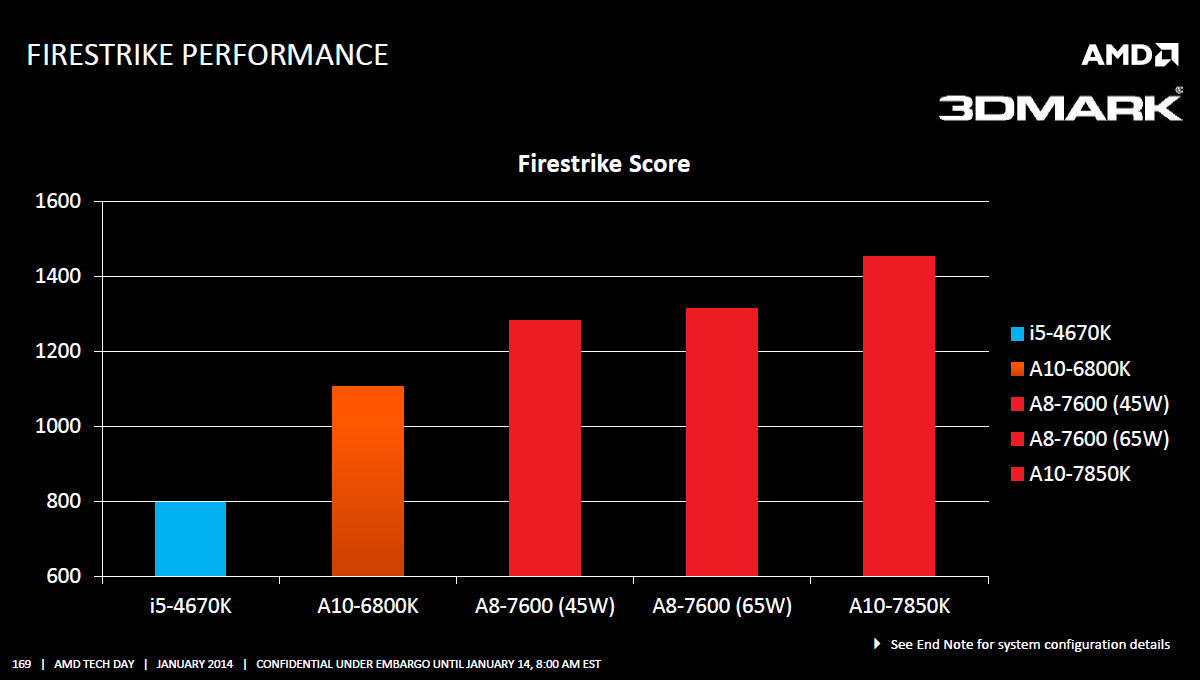
V podobném duchu vyznívá další srovnání, které bohužel nezačíná v nule. AMD si tím tak trochu dává gól do vlastní brány, protože graf začínající v nule by ukázal velice zajímavou energetickou efektivitu 45W modelu oproti 65 a 100W modelům.
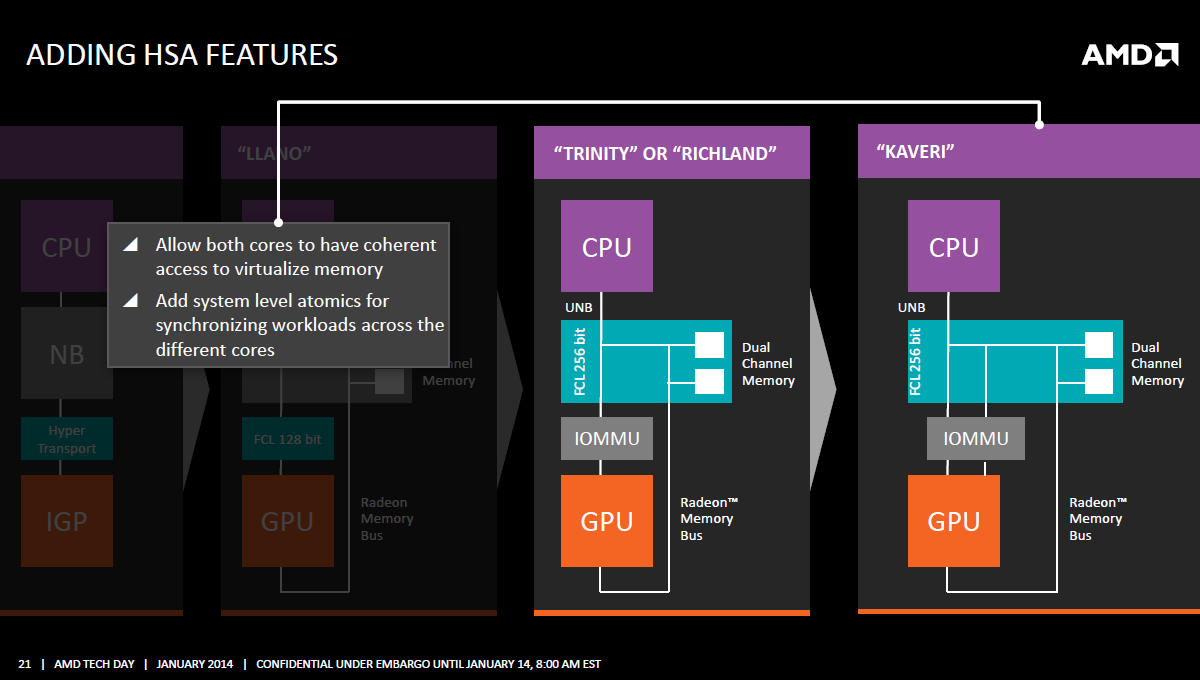
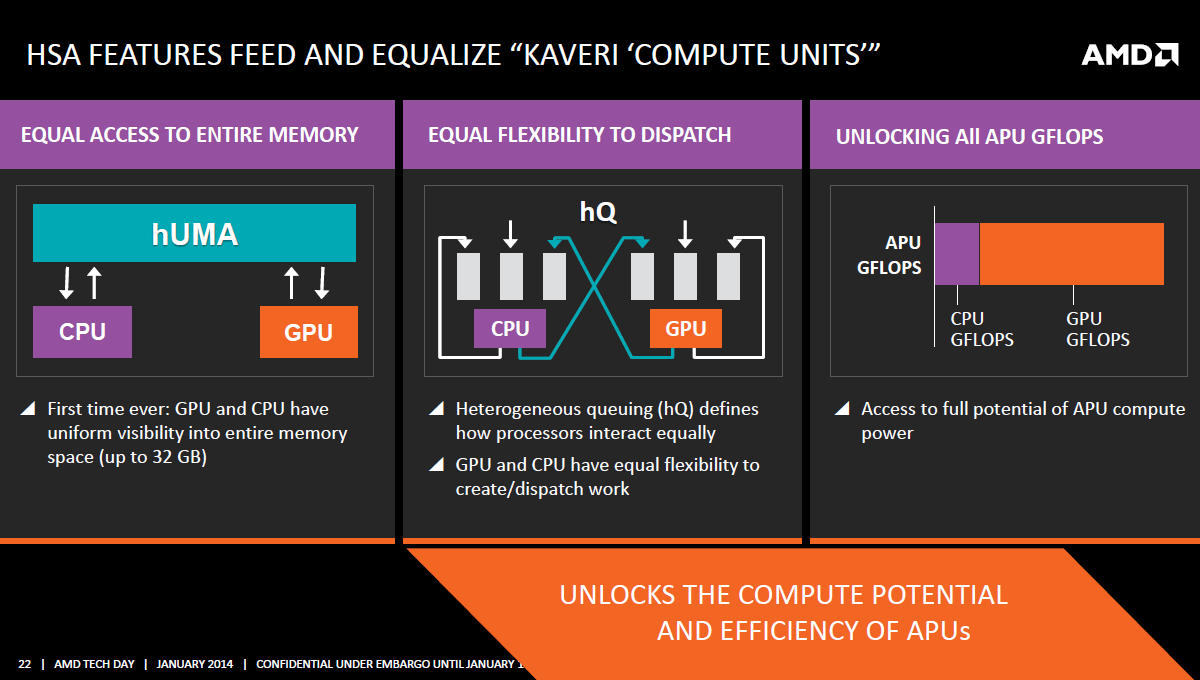
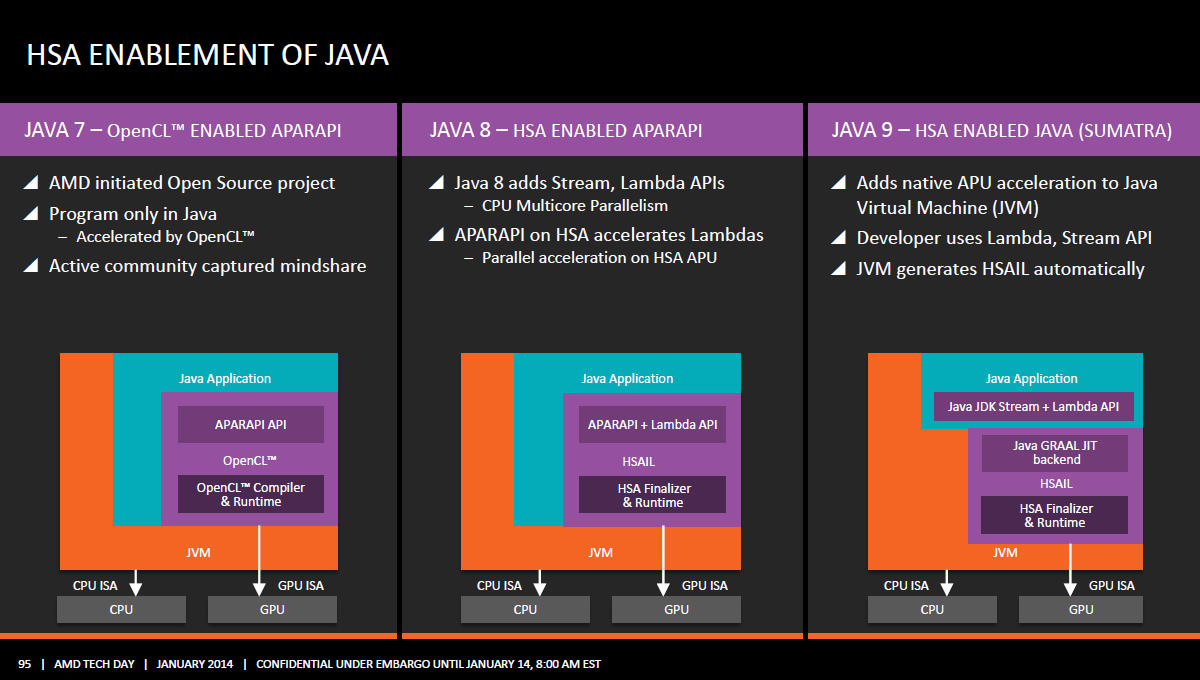
HSA
Možná jste si všimli na některých slajdech, které nedočkaví novináři vypustili před konce informačního embarga, že AMD o Kaveri hovoří jako o čipu s 12 výpočetními jednotkami. Důvody jsou dva.

Společnost považuje za zavádějící hovořit o Kaveri jakožto o čtyřjádru s integrovanou grafikou, když právě základem a největší částí je grafika (47 %), nikoli procesor. Druhý důvod je nástup HSA, tedy možnost využívat grafického jádra jakožto koprocesorů.

AMD proto jako výpočetní jádra nazývá nejen jádra procesorová, ale také bloky GCN. Jako výpočetní jádro (compute core, CC) pak definuje: HSA-kompatibilní hardwarový blok, který je programovatelný, schopný realizovat běh alespoň jednoho procesu nezávisle na ostatních. 4 jádra Steamroller a 8 jader GCN tak dává výsledných 12 výpočetních jader.






předchozí kapitola
následující kapitola
Kapitoly článků
2. Grafické jádro a HSA


















