
AMD naznačila možné další využití Infinity Cache
Technologie, která umožňuje GPU s mainstreamovou sběrnicí a generaci starým typem paměti dosahovat high-endového výkonu samozřejmě najde uplatnění i v nižších cenových relacích…
Jak konkrétně, to na několika místech nenápadně naznačuje technologická prezentace v materiálech AMD. Předně ale musíme mít na paměti základní principy fungování této cache.
O kolik zvyšuje Infinity Cache datovou propustnost
V případě GPU Navi 21 použitého na Radeonech RX 6800 / 6900 dosahuje kapacity 128 MB a se zbytkem čipu je propojena interní 8192bit sběrnicí dosahující taktu 1,94 GHz. Fyzická datová propustnost Infinity Cache je tedy (8192 × 1,94 / 8 =) ~2 TB/s. Infinity Cache funguje jako cache poslední úrovně, tedy co se v ní nenachází, pro to je potřeba sáhnout do grafické paměti. Ta je připojena 256bit sběrnicí, dosahuje efektivní přenosové rychlosti 16 GHz a kapacity 16 GB. Datová propustnost je 512 GB/s.

Pro běh her ve 4k rozlišení platí, že případů, kdy se potřebná data najdou v Infinity Cache (a nemusí se přistupovat ke grafické paměti) je v průměru 58 %. (Je tedy 58% šance, že se v 0,1GB úseku paměti najde požadovaný obsah, který může ležet kdekoli 16GB paměti = hit rate 58 %) Těchto 58 % v praxi znamená, že ve 4k rozlišení je v 58 % využívána datová propustnost Infinity Cache (2 TB/s) a ve zbytku případů datová propustnost GDDR6 (512 GB/s). Průměrně tedy Infinity Cache poskytuje jádru typických 1152 GB/s a GDDR6 512 GB/s, což znamená 1664 GB/s celkem.
Na čem závisí hit-rate
Obecně tedy platí, že o výši bonusu datové propustnosti, který Infinity Cache nabídne, rozhoduje několik faktorů:
- rozlišení, ve kterém je vykreslováno
- kapacita Infinity Cache
- kapacita grafické paměti, respektive objem paměti, který hra svými daty obsadí
Pokud např. spustíme nějakou starou či nenáročnou hru, která z paměti obsadí jen jednotky procent, může být hit-rate výrazně vyšší (větší procento obsahu paměti se vejde do Infinity Cache a tím je vyšší šance, že se v jejím obsahu najdou požadovaná data a bude využita její vyšší propustnost).
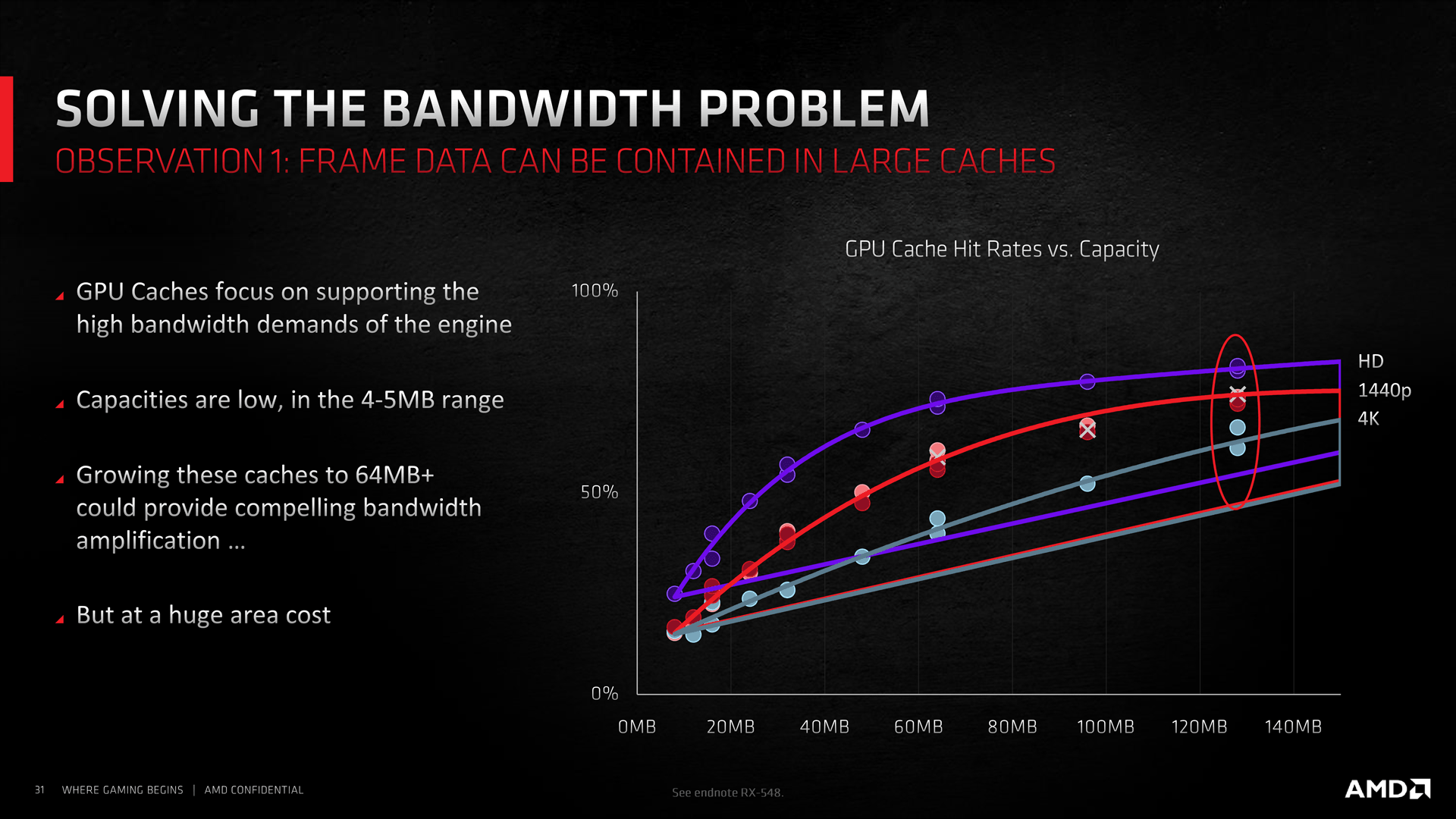
AMD nabídla výše zobrazené údaje ohledně závislosti hit-rate Infinity Cache na zvolené kapacitě a cílovém rozlišení. Závislost bere v potaz konfiguraci čipu (počet CU), takže nejde jen o teoretický model vztažený ke konfiguraci Navi 21 (Radeony RX 6800 / 6900), ale o závislost vypovídající i o dalších produktech s nižším výkonem. Můžeme si všimnout, že tři hodnoty jsou označeny křížkem: (zprava) 128 MB, 96 MB a 64 MB. Hit-rate pro jednotlivé hodnoty odpovídá zhruba:
| fyzická propustn. IC** | plocha IC*** | hit-rate a efektivní propustnost IC (GB/s) | ||||||
|---|---|---|---|---|---|---|---|---|
| 1920×1080 | 2560×1440 | 3840×2160 | ||||||
| 12 MB | 186 GB/s | 12 mm² | 31 % | 58 | 19 % | 35 | 15 % | 28 |
| 16 MB | 248 GB/s | 16 mm² | 37 % | 92 | 25 % | 62 | 17 % | 42 |
| 24 MB | 373 GB/s | 24 mm² | 48 % | 179 | 31 % | 116 | 24 % | 90 |
| 32 MB | 497 GB/s | 32 mm² | 55 % | 273 | 39 % | 194 | 26 % | 129 |
| 48 MB | 745 GB/s | 48 mm² | 66 % | 492 | 49 % | 365 | 34 % | 253 |
| 64 MB | 993 GB/s | 64 mm² | 72 % | 715 | 59 % | 586 | 41 % | 407 |
| 96 MB | 1490 GB/s | 96 mm² | 78 % | 1162 | 66 % | 983 | 52 % | 775 |
| 128MB | 1987 GB/s | 128 mm² | 81 % | 1609 | 74 % | 1470 | 62 %* | 1232 |
*z grafu vyplývá pro 4k rozlišení hit-rate 62 % (namísto v původní prezentaci uváděných 58 %); graf mohl vzniknout na základě odlišného testovacího setu, nebo se hit-rate pomocí určitých optimalizací podařilo nepatrně zvýšit
**mimo údaj pro 128MB kapacitu jde o odhad na základě předpokladu, že s kapacitou bude přímo úměrně klesat i šířka sběrnice Infinity Cache; počítáno s taktovací frekvencí sběrnice / IC až 1940 MHz
***platné pro 7nm proces, odhad na základě údaje o parametrech odpovídajících L3 cache Zen 2
Zvýraznění hodnot pro kapacity 128 MB, 96 MB a 64 MB tak může vypovídat o tom, že pro Navi 21 byla zvolena 128MB kapacita (již známý údaj), pro Navi 22 96MB kapacita a pro Navi 23 64MB kapacita.
Navi 22
To jsou poněkud vyšší hodnoty, než by se dalo s ohledem na cílová využití očekávat. Začněme u mainstreamové Navi 22, GPU očekávaném na Radeonech RX 6700. Toto jádro ponese 192bit sběrnici, tedy sběrnici o 25 % užší, než je pro daný výkonnostní segment (bez Infinity Cache) obvyklé (256bit). V případě high-endové Navi 21 ale byla 256bit sběrnice o 33 % užší, než je pro daný výkonnostní segment (bez Infinity Cache) obvyklé (384bit). Infinity Cache tedy u Navi 22 bude kompenzovat daleko nižší deficit a dávalo by smysl snížit kapacitu výrazněji než jen na základě závislosti hit-rate a rozlišení (není zapotřebí tak vysoký hit-rate, protože propustnost grafické paměti je poměrně vysoká). S ohledem na rozlišení by tedy dávala smysl kapacita 64 MB, s ohledem na nižší deficit 192bit sběrnice oproti 256bit (ve srovnání 256bit oproti 384bit) by se dalo uvažovat i o nižší hodnotě jako 48 MB. V grafu vyznačená hodnota však napovídá 96MB kapacitu.
Navi 23
V případě Navi 23 vybavené (pravděpodobně) 128bit sběrnicí by šlo o kapacitu 64 MB, ačkoli by očekávané cílení jádra (1920×1080 s vyskými detaily pro desktop nebo až 2560×1440 se středními detaily pro notebooky) naznačovalo, že 48MB kapacita by byla více než dostatečná.
APU Rembrandt a Van Gogh
Graf dále obsahuje údaje pro kapacity jako 8, 12, 16, 24 a 32 MB, které by mohly najít uplatnění v APU.
| APU | rok | proc. | CPU | GPU | plocha |
|---|---|---|---|---|---|
| Llano | 2011 | 32nm | 4/4× K10,5 | 400 SP VLIW-5 | 226 mm² |
| Trinity Richland | 2012 2013 | 32nm | 4/4× Piledriver | 384 SP VLIW-4 | 246 mm² |
| Kaveri | 2014 | 28nm | 4/4× Steamroller | 512 SP GCN2 | 245 mm² |
| Carrizo Bristol Ridge | 2015 2016 | 28nm | 4/4× Excavator | 512 SP GCN3 | 245 mm² |
| Raven Ridge Picasso | 2017 2019 | 14nm 12nm | 4/8× Zen(+) | 704 SP Vega | 210 mm² |
| Renoir Lucienne | 2020 2021 | 7nm | 8/16× Zen 2 | 512 SP Vega+ | 156 mm² |
| Cezanne | 2021 | 7nm+ | 8/16× Zen 3 | 512 SP Vega+ | 1xx mm² |
| Rembrandt | 2022 | 6nm | 8/16× Zen 3 | RDNA2 | 208 mm² |
16-32MB by mohla být kapacita určená pro APU Rembrandt (Zen 3 + RDNA2 na zimu 2021/2022) a 16-12-24MB pak pro úsporné APU Van Gogh (Zen 2 + RDNA 2 pro první pololetí 2021).
Kolik křemíku stojí Infinity Cache
Jaké nároky má vlastně Infinity Cache na plochu křemíku? Hodně hrubý (spíše řádový) obrázek dal graficky upravený snímek jádra (v úvodu). Právě grafické úpravy zakrývají skutečné detaily, takže hodnota může být značně nepřesná. Konkrétně to vycházelo na asi 80 mm² pro 128 MB.
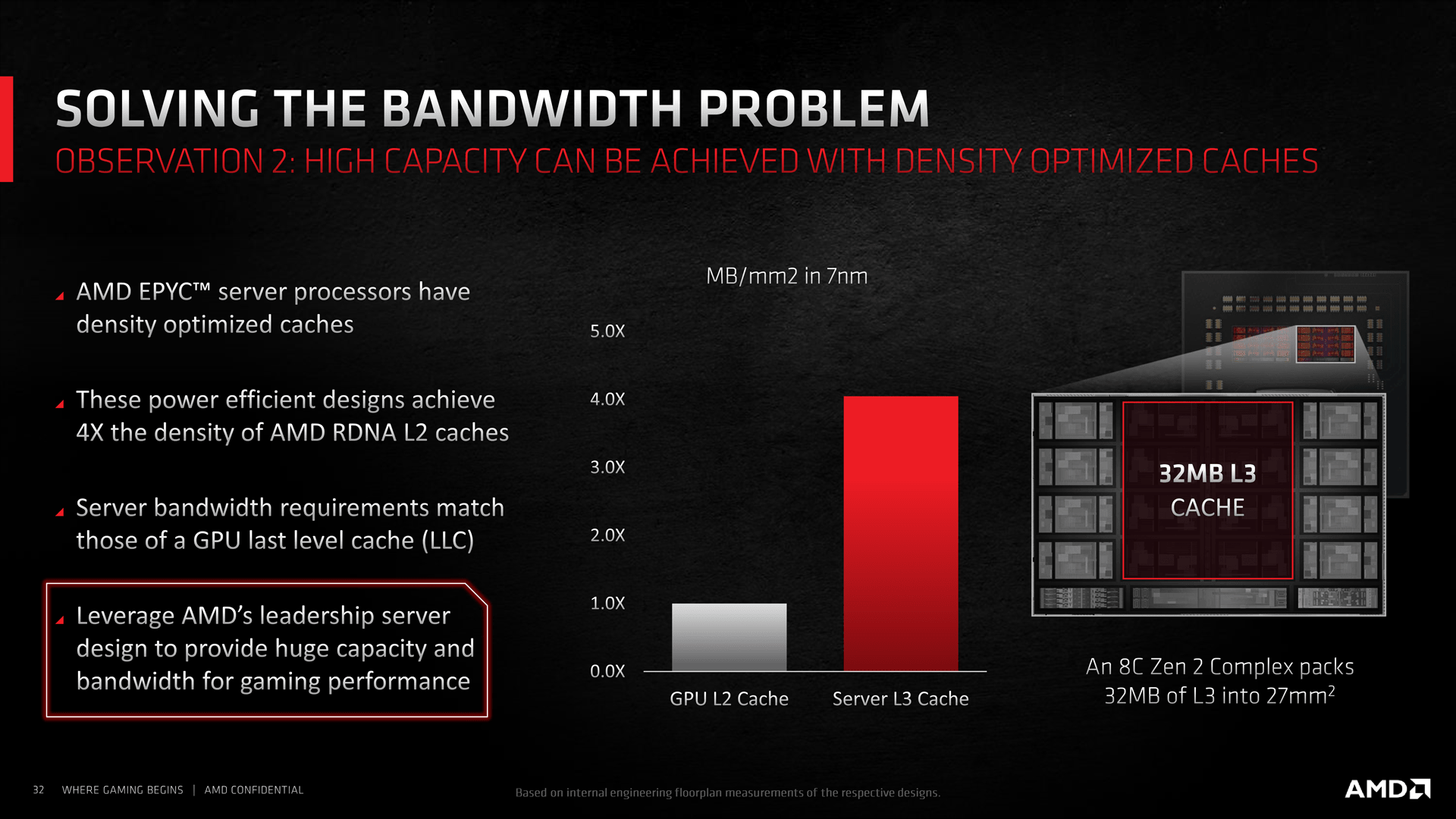
Teoreticky přesnější indicie vyplývá z dalšího slajdu AMD, který uvádí, že Infinity Cache vzešla z L3 cache Zen 2, která dosahuje 4× vyšší denzity než L2 cache GPU a dosahuje právě takové datové propustnosti, která je vhodná pro cache poslední úrovně u GPU. Pokud nebylo potřeba měnit datovou propustnost, nebude se výrazně lišit ani denzita a pro hrubou představu lze předpokládat, že by denzita byla stejná, tedy zhruba 1 mm² na 1 MB kapacity. Což by znamenalo asi 128 mm² na 128 MB. (AMD uvádí trochu méně, důvodem je pravděpodobně, že počítá pouze plochu cache a nikoli sběrnici, případně další obvody, které ji spojují se zbytkem čipu).
V případě APU Rembrandt, kde máme očekávat plochu jádra 208 mm² (tedy podstatně více než u současného APU Renoir se 156 mm² navzdory mírně lepšímu - 6nm - procesu) by tedy výrazná část tohoto navýšení byla vysvětlitelná 32 MB (~32 mm²) Infinity Cache.
Kolik datové propustnosti může Infinity Cache přidat APU
V současnosti, s APU Renoir, je v desktopu k dispozici řekněme dvoukanálové zapojení DDR4-3200, která nabízí 51,2 GB/s. To je vše (po odčtení nároků procesorových jader a dalších obvodů), co má integrované GPU k dispozici.
Bude-li APU Rembrandt určeno pro socket AM4, zůstáváme u DDR4, tedy například oněch 51,2 GB/s. Je pravděpodobné, že šířka sběrnice Infinity Cache škáluje s kapacitou, takže (např.) 32MB cache nedisponuje 8192bit sběrnicí (jako 128MB), ale 2048bit. Ta by měla propustnost asi 497 GB/s. Pro rozlišení 1920×1080 je uveden hit-rate asi 55 %, což by bylo 273 GB/s k Infinity Cache + 51 GB/s k RAM, tedy efektivně celkem 324 GB/s, asi šestinásobek toho, co má APU k dispozici nyní. Jelikož jde o vyslovený overkill (i kdyby se výkon integrovaného APU zvýšil na dvojnásobek, je tento nárůst 3× vyšší, než by bylo potřeba). AMD tak může použít i nižší kapacitu, nebo snížit taktovací frekvenci sběrnice Infinity Cache pro úsporu energie (což je pro APU, určená i pro mobilní segment, podstatný aspekt).
V případě 24MB cache by měl Rembrandt k dispozici efektivně (179+51) 230 GB/s. I kdyby škálování u APU nebylo takto „dokonalé“ a praxe byla o desítky procent horší, stále by se efektivní paměťová propustnost měla zvýšit na úrovni nižších násobků a umožnit mnohem větší posun grafického výkonu, než k jakému v tomto segmentu docházelo doposud.


























