
Infinity Fabric 3.0 zvládne propojit CPU s 8 GPU, AMD chystá i X3D pouzdření
Rozhraní propojující CPU s GPU o propustnosti vyšší než PCIe 5.0, možnost propojit do kruhu 8 GPU nebo spojit čtyři GPU přímo s procesorem a ještě vzájemně. To je nová Infinity Architecture…
Infinity Fabric AMD definovala jako sběrnice sloužící jak k propojení jednotlivých částí uvnitř čipu, tak k propojení samotných čipletů či modulů, a nakonec i k propojení celých samostatných čipů. První generace přišla se Zenem a Vegou, druhá se Zen 2 a nyní se dozvídáme, jaké možnosti nabídne generace třetí.
AMD v této souvislosti hovoří spíše o Infinity Architecture, byť i termín Infinity Fabric 3.0 padl. Jak tomu budeme říkat, je v podstatě vedlejší (to si i AMD asi ještě ujistí) - zajímavější je, co to umožní.

Třetí generace v provedení sloužícímu ke spojení procesoru a grafické karty (výpočetní grafické karty) dosáhne 2,25× vyšší přenosové kapacity než PCIe 4.0, takže mírně překoná i možnosti PCIe 5.0. Druhá podstatná výhoda tkví v podpory koherentní paměti, kdy CPU a GPU mohou přistupovat do své paměti, jako by šlo o cache. Výhodou je zjednodušení kódu pro GPU akcelerátory v HPC segmentu.

Krom prostého propojení jednoho CPU s jedním GPU umožňuje třetí generace propojit procesor přímo se čtyřmi grafickými jádry, která jsou navíc propojena vzájemně do kruhu. Tento systém bude pravděpodobně využit v případě 2EFLOPS superpočítače El Capitan.
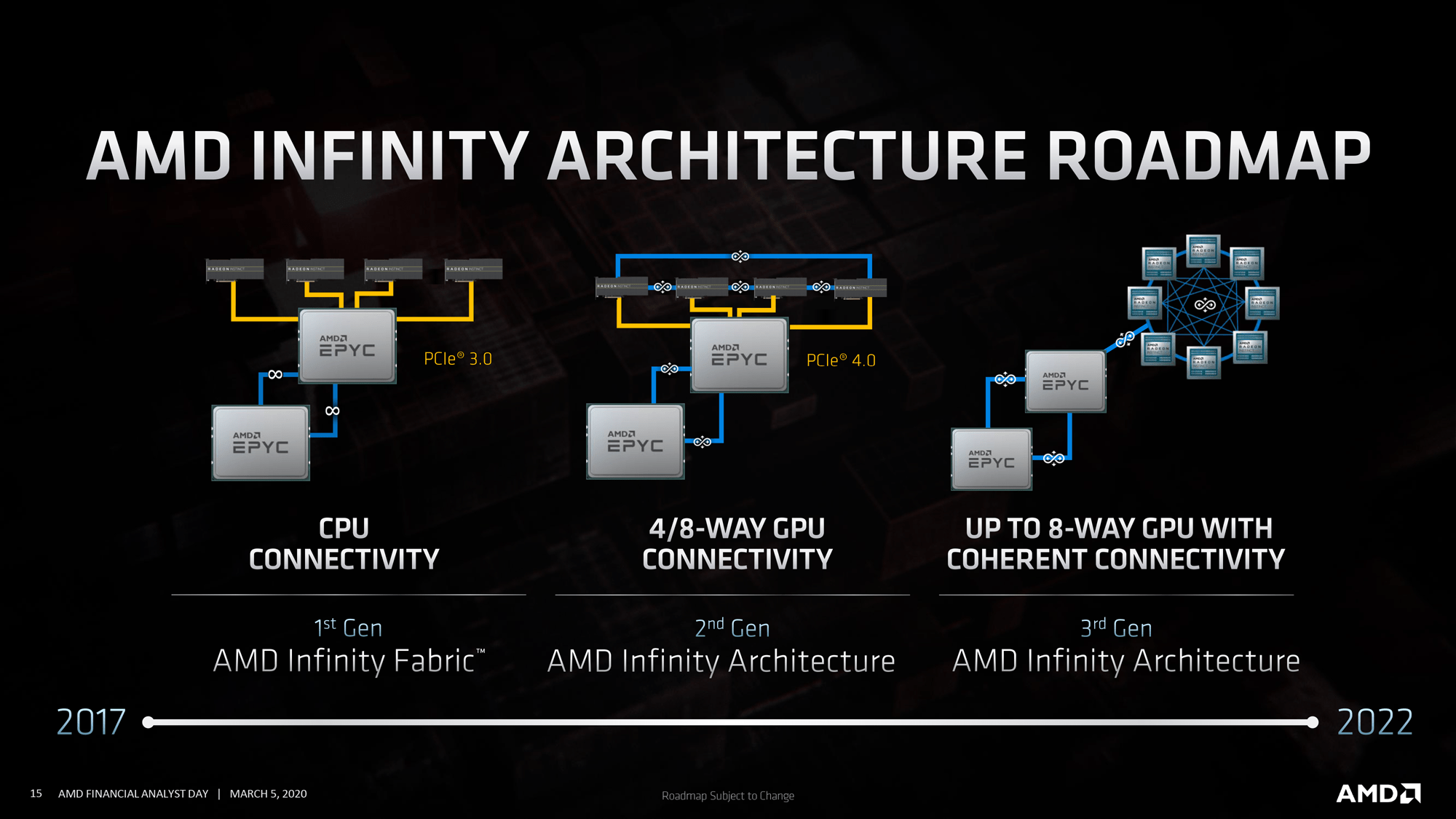
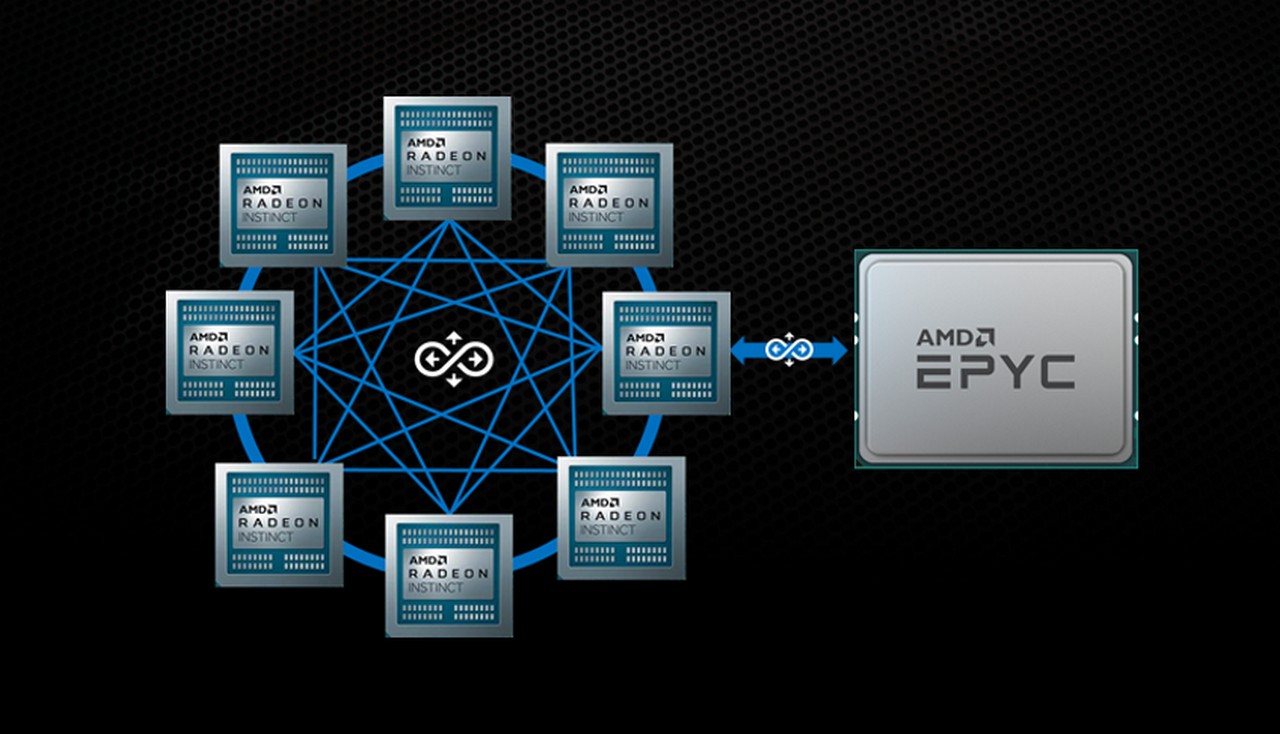
Další z možností je propojení procesoru s kruhem osmi GPU, která jsou dále propojena přímo každé s každým. Novinka nespočívá pouze v počtu propojených GPU, ale také ve faktu, že dosud CPU a GPU AMD komunikovala přes PCIe - Infinity Fabric se využívala jen ke vzájemnému propojení skupiny GPU a vzájemnému propojení dvou CPU. Infinity Architecture 3.0 bude podporována na produktech chystaných na rok 2022, což bude mimo jiné Zen 4 a CDNA 2.

Další novinka je z trochu jiného soudku, ale s Infinity Architecture nakonec bude souviset taky. Jde o nové metody pouzdření, které zkříží tzv. 2,5D pouzdření (křemíky umístěné na společné podložce - interposer) a 3D pouzdření (vrstvení). Příklad na slajdu zobrazuje čtyři čiplety obklopené čtyřmi štoky vrstvených (nejspíš) pamětí.
Co jsou ony čtyři centrální čiplety zač, není jasné. Jednou možností je CPU, druhou GPU. CPU by asi datovou propustnost HBM pamětí (4096bit sběrnice) nevyužilo, takže spíš GPU. Čipletový design pro herní GPU je nejspíš hudba budoucnosti, takže by mohlo jít o výpočetní produkt, čiplety architektury CDNA 2. Pro HPC není rozdělení na čiplety problém, ke vzájemnému sdílení velkých objemů dat mezi nim, jako je tomu v grafice, totiž při výpočtech nedochází.























