
Rozbor: Architektura Turing a jádro TU106 odhaleny

S předstihem před oficiálním vydáním se můžeme podívat na novinky architektury Turing…
Redakce webu VideoCardz si od některého subjektu, který je pod NDA, opatřila prezentaci architektury Nvidia Turing. Lze předpokládat, že daná prezentace je překrytá logy onoho subjektu, kterému byla adresována, takže se VideoCardz rozhodla klíčové prvky věrně překreslit, aby jej zveřejněním slajdů s logy nekompromitovala. Díky tomu se dozvídáme první podrobnější informace o Turingu.
Turing SM

SM blok Turing
Co vidíte výše, je SM blok architektury Turing. Abychom měli lepší srovnání, následuje SM blok architektury Volta:

SM blok Volta
Nenechte se zmást odlišnými barvami nebo tvary, jde v obojím případě jen o schémata. Na první pohled je vidět, že schéma zveřejněné pro Turing je zjednodušené oproti schématu zveřejněnému pro Voltu, takže srovnání není snadné (a u některých prvků není ani možné, protože nejsou znázorněné).
Ve srovnání s Voltou zůstalo zachováno 4× 16 (tzn. 64) FP32 („stream-procesorů“, „CUDA jednotek“) na SM blok. Stejně tak i 4× 16 (tzn. 64) INT32 jednotek na SM blok. Byť to na schématu Volty není uvedeno, i jeho INT jednotky jsou INT32. Pokud bychom srovnávali s Pascalem, je to ještě obtížnější, protože ten existuje ve dvou architektonických mutacích - GP100 a ostatní (GP102, GP104 atd.), přičemž Volta a Turing jdou spíše ve šlépějích architektonické varianty GP100.
Nvidia uvádí INT32 jednotky jako novinku, což je pravda, pokud je srovnáváno s Pascalem, nikoli s Voltou. Turing umožňuje FP32 a INT32 jednotky využívat paralelně, což Nvidia (společně s několika dalšími změnami) prezentuje jako až o 36 % zvýšení výkonu v přepočtu na CUDA jednotku. Nesmíme ovšem zapomínat na to, že jde de facto o přidání další výpočetní jednotky, která jen není počítána mezi CUDA (FP32) jednotky. Mezi zmíněnými dalšími změnami je uveden upravený caching textur a upravená L1 cache, díky nimž má být celkový výkonnostní posun přepočtený na CUDA jednotku až 50 %. Není jasné, do jaké míry jde o změny oproti architektuře Pascal a do jaké míry oproti architektuře Volta. Rozdíl v cache by však mohl být i oproti druhé.
Samotná schémata SM Turing a SM Volta se dále liší absencí FP64 jednotek a L0 cache. Protože některé prvky na schématu SM Turing kvůli zjednodušení chybějí, nelze jednoznačně odvodit, do jaké míry jde o rozdíl v architektuře a do jaké míry o rozdíl v prezentaci. Je zřejmé, že Turing (alespoň ve stávající podobě) nepodporuje rychlé FP64 (double-precision), ale bylo by neobvyklé (nikoli však nemožné), kdyby jej - jak naznačuje schéma - nepodporovala vůbec. Naopak co bez debat přibylo jak oproti architektuře Pascal, tak oproti Volta, je RT Core pro ray tracing. O jeho výbavě se prozatím nedozvídáme.
Paměti, komprese
Turing přichází jako první produkt Nvidie s podporou pamětí GDDR6. Pro další zrychlení datových přenosů došlo ke zvýšení efektivity bezztrátové komprese. Nvidia hovoří o 50% efektivním zvýšení datových přenosů Turingu oproti Pascalu.
Co se týče vylepšené komprese, jde pravděpodobně o prvek, kterým disponuje již Volta. To vede k myšlence, že se toto číslo týká jedné specifické situace a to komprese 10bit textur, která Pascalu - řekněme - příliš nešla (existují názory, že šlo o bug návrhu). Ta je používána především pro HDR, což je důvodem, proč u her limitovaných paměťovou propustností docházelo u Pascalu při použití HDR k výraznějšímu propadu výkonu. Dalo by se předpokládat, že tato slabina byla u nástupců Pascalu vyřešena a komprese 10bit textur snižuje objemy dat až o třetinu, jinými slovy zvyšuje datovou propustnost.
Shading
- Mesh Shading - nový model pro teselaci, vertex- a geometry shading, který umožňuje realizovat vyšší počet objektů ve scéně; bližší informace zatím nejsou k dispozici, ale na první pohled to vypadá, že by mohlo jít o alternativu k technologii Primitive Shader architektury Vega (snad funkční ;-)
- Variable Rate Shading (VRS) - vývojář může určit přesnost; snížením přesnosti tam, kde to nemá dopady na vizuální stránku, lze zvýšit výkon; jakási alternativa k Rapid Packed Math Vegy
- Texture-Space Sharing - uložení výsledků v paměti bez potřeby duplikace
- Multi-View Rendering (MVR) - rozšíření podpory o Pascalu ze stereo single-pass na multi-view single-pass; není nám známo, na jaké úrovni byla podpora MVR u Volty
Video a obraz
- DisplayPort 1.4a (umí 8k při 60 Hz, GPU zvládne 2× 8k displej při 60 Hz přes DP či USB-C)
- vylepšený NVENC zvládá komprimovat h.265 při 8k a 30 FPS
- vylepšený NVDEC zvládá HEVC YUV444 10bit / 12bit HDR, h.264 8K a VP9 10bit / 12 bit HDR
NVLINK aneb konec 3-way / 4-way SLI
- GeForce RTX 2080 Ti - 2× x8 2nd Gen NVLINK
- GeForce RTX 2080 - 1× x8 2nd Gen NVLINK
- GeForce RTX 2070 - nepodporuje
Je možné propojit dvě karty, podpora pro třícestné a čtyřcestné SLI byla odstraněna.
TU102, TU104 a překvapení: TU106
Turing TU106
Podoba jádra TU102 použitého na GeForce RTX 2080 Ti byla zhruba známa. Diagram potvrzuje až 4608 stream-procesorů a až 96 ROP (GeForce nemá všechny jednotky aktivní). GPU dosahuje 754 mm²
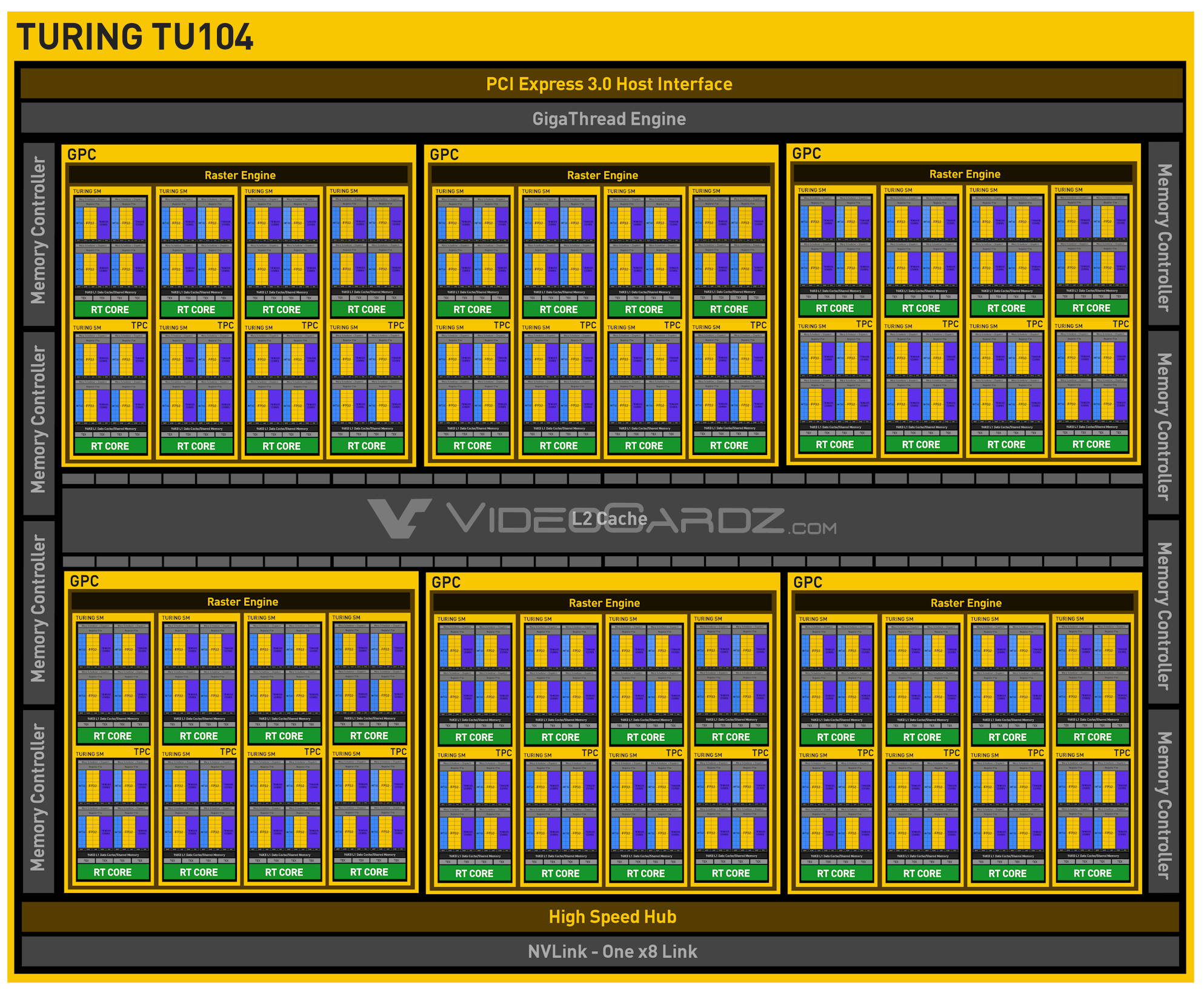
Turing TU104
Jádro TU104 použité na GeForce RTX 2080 disponuje fyzicky 3072 stream-procesory a 64 ROP. V případě GeForce je opět část neaktivní. Novinka: GPU dosahuje 545 mm² (což je slušně blízko našemu odhadu o 560 mm²)
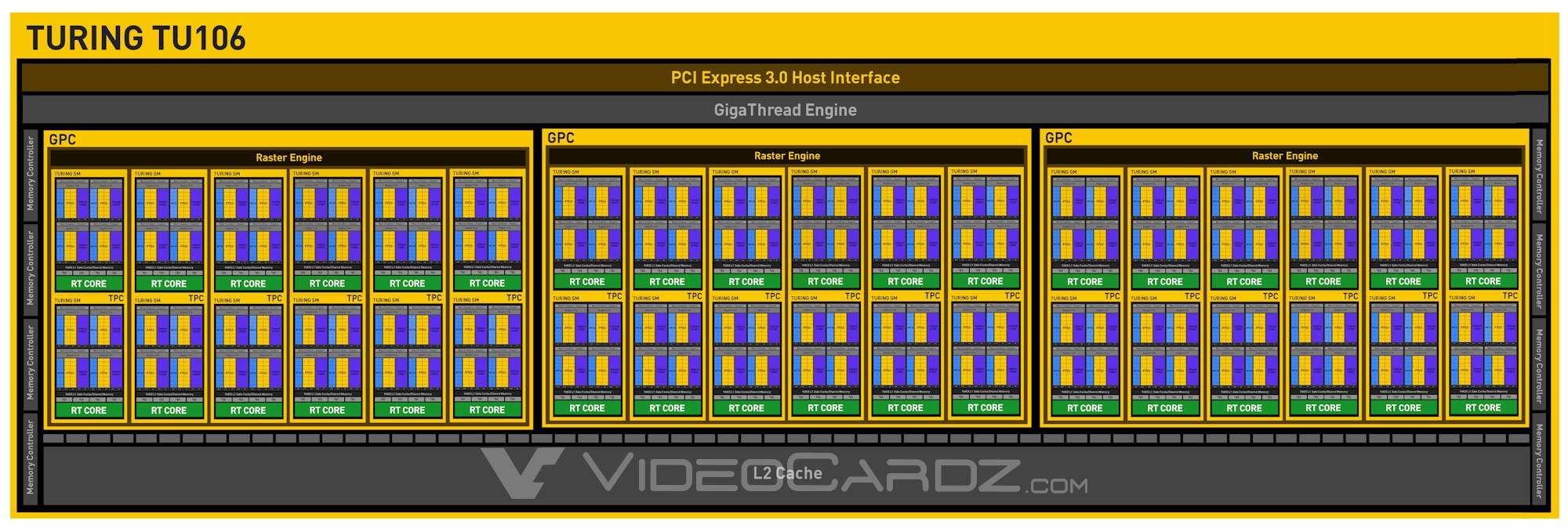
Turing TU106
Překvapení: GeForce RTX 2070 není oproti původním předpokladům postavená na ořezaném jádru TU104, ale na plně aktivním jádře TU106. Přestože Nvidia „šestku“ tradičně používá ke značení mainstreamových čipů, které disponují zhruba polovinou stream-procesorů oproti „čtyřkovému“ čipu, tentokrát se věci mají jinak. TU106 není mainstreamová ani počtem stream-procesorů, který je poloviční oproti TU102 (a nikoli proti TU104), ani sběrnicí, která je stejná jako u TU104, tzn. 256bit (a nikoli poloviční oproti větším GPU), ani plochou, která dosahuje 445 mm² (to je zcela nová informace), ani cenou výsledného produktu $599. Zajímavostí je, že jde o (zatím?) jedinou GeForce RTX, která nese plně aktivní jádro, což tentokrát znamená 2304 stream-procesorů, 64 ROP a 256bit sběrnici.
V souladu s novými informacemi upravuji i naší tabulku:
| GeForce RTX 2070 | GeForce RTX 2080 | GeForce RTX 2080 Ti | |
|---|---|---|---|
| GPU | TU106 10,6 mld. tr. | TU104 13,6 mld. tr. | TU102 18,6 mld. tr. |
| Plocha | 445 mm² | 545 mm² | 754 mm² |
| Proces | 12 nm TSMC | ||
| Zákl. takt | 1410 MHz | 1515 MHz | 1350 MHz |
| Boost | 1620 / 1710 MHz | 1710 / 1800 MHz | 1545 / 1635 MHz |
| SPs | 2304 | 2944 | 4352 |
| Tensor | 288 | 368 | 544 |
| RT Cores | 36 | 46 | 68 |
| TMUs | 144 | 184 | 272 |
| ROPs | 64 | 64 | 88 |
| tens. Int4 | ? | ? | 420 / 445(?) |
| tens. FP16 | ? | ? | 105 / 111 |
| FP16 (TFLOPS) | ? | ? | ? |
| FP32 (TFLOPS) | 7,5 / 7,9 | 10,1 / 10,6 | 13,4 / 14,2 |
| FP64 (TFLOPS) | ? | ? | ? |
| RT | 6 GR/s | 8 GR/s | 10 GR/s |
| RTX-OPS | 45 T | 60 T | 78 T |
| paměti | 8 GB 256bit GDDR6 | 8 GB 256bit GDDR6 | 11 GB 352bit GDDR6 |
| takt | 14 GHz | 14 GHz | 14 GHz |
| dat. prop. | 448 GB/s | 448 GB/s | 616 GB/s |
| napájení | 8 pin | 8+6 pin | 8+8 pin |
| TDP | 175 / 185 W | 215 / 225 W | 250 / 260 W |
| vydání | Q4 2018 | 20. září 2018 | 20. září 2018 |
| dob. cena | $499 / $599 | $699 / $799 | $999 / $1199 |
To je prozatím vše, co bylo možné z uniklých útržků vyžmuňkat.
Zdroje:























