
Infinity Cache je ještě hustší, než se zdálo
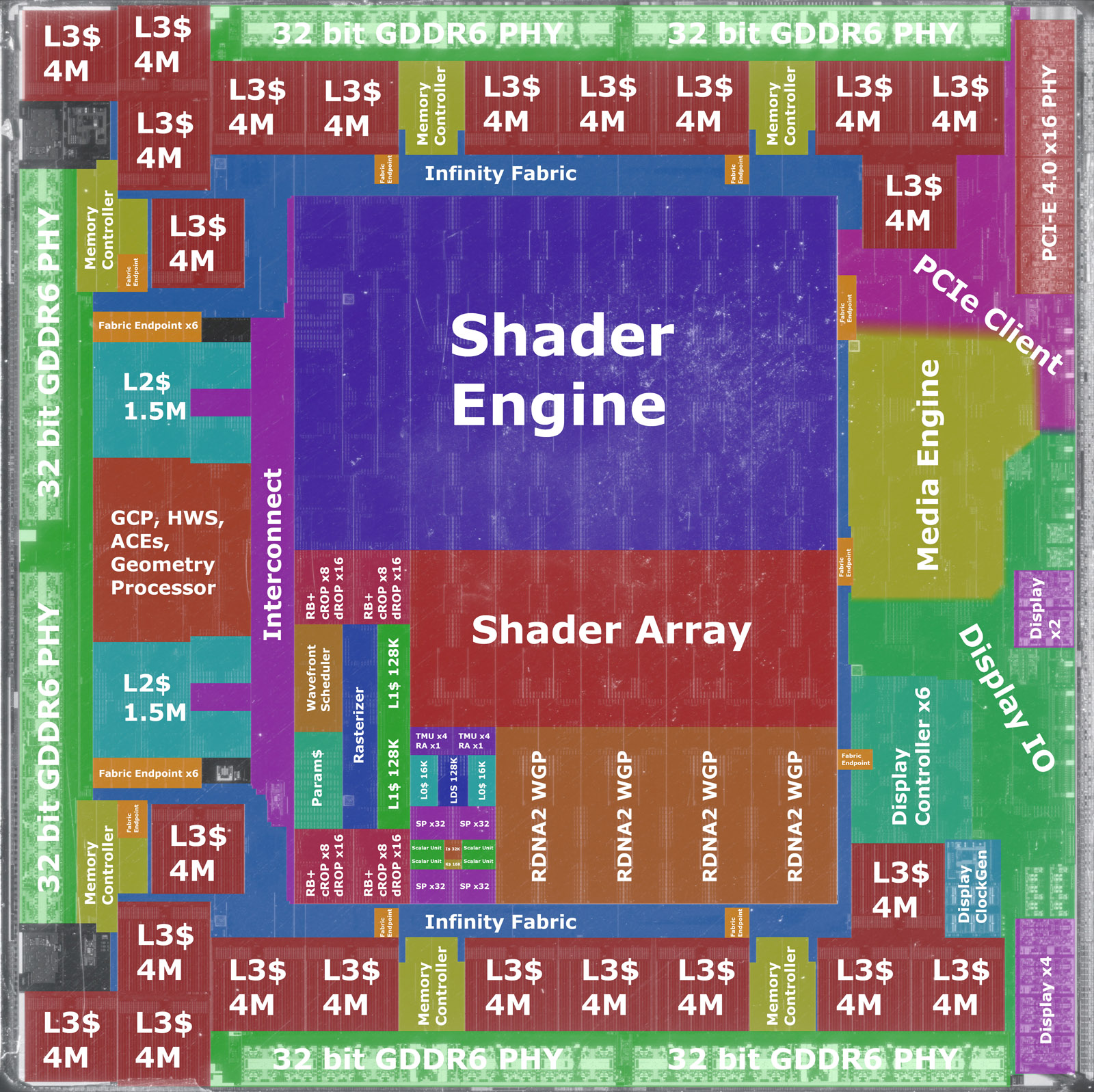
Zúžení paměťové sběrnice na polovinu, zvýšení výkonu i přes setrvání u GDDR6, zlepšení poměru spotřeba / výkon, zvýšení taktovacích frekvencí. Nejen to. Ukazuje se, že Infinity Cache je hodně hustá…
V roce 2020 jsme se ve dvojici článků věnovali principům Infinity Cache a výhledu, jakým způsobem a v jakých produktech by se dala využít dále. AMD totiž krátce po vydání Radeonů RX 6000 přiznala, že impulsem k jejímu nasazení původně nebylo dosažení maximálního výkonu v desktopu, ale mobilní segment. U mobilních zařízení není prostoru nazbyt, a tak je úzká sběrnice ceněna. Čím užší sběrnice, tím méně paměťových čipů a tím nižší nároky na plochu PCB. Ušetřené místo pak může okupovat jiné zařízení, například chladič, baterie a podobně. Pokud tedy v mobilním segmentu produkt „A“ dosahuje výkonu 100 % při 128bit sběrnici, je v lepší konkurenční pozici než produkt „B“, který téhož 100% výkonu dosahuje při 256bit sběrnici.
Nasazení Infinity Cache by z tohoto důvodu by pro AMD mělo smysl i v případě, že by ostatní přínosy nevyvažovaly náklady navíc spojené s vyšší plochou jádra potřebnou pro Infinity Cache. Jenže těch přínosů nakonec bylo poměrně dost. Že Infinity Cache nezabírá nějakou extrémně velkou část jádra, bylo známé od začátku. AMD zveřejnila, že inženýři grafické divize využili L3 cache Zen 2, která byla navržena pro maximalizaci kapacity na jednotku plochy. Tato L3 cache dosahuje mírně přes 1 MB na mm² křemíku 7nm procesu TSMC. Právě s tím jsme počítali v našich předchozích článcích - tedy zjednodušeně: 1 MB na mm², tedy 128 mm² pro 128MB cache GPU Navi 21 (Radeony RX 6800 / 6900).
| fyzická propustn. IC | plocha IC | hit-rate a efektivní propustnost IC (GB/s) | ||||||
|---|---|---|---|---|---|---|---|---|
| 1920×1080 | 2560×1440 | 3840×2160 | ||||||
| 12 MB | 186 GB/s | 12 7 mm² | 31 % | 58 | 19 % | 35 | 15 % | 28 |
| 16 MB | 248 GB/s | 16 10 mm² | 37 % | 92 | 25 % | 62 | 17 % | 42 |
| 24 MB | 373 GB/s | 24 15 mm² | 48 % | 179 | 31 % | 116 | 24 % | 90 |
| 32 MB | 497 GB/s | 32 20 mm² | 55 % | 273 | 39 % | 194 | 26 % | 129 |
| 48 MB | 745 GB/s | 48 29 mm² | 66 % | 492 | 49 % | 365 | 34 % | 253 |
| 64 MB | 993 GB/s | 64 39 mm² | 72 % | 715 | 59 % | 586 | 41 % | 407 |
| 96 MB | 1490 GB/s | 96 59 mm² | 78 % | 1162 | 66 % | 983 | 52 % | 775 |
| 128MB | 1987 GB/s | 128 79 mm² | 81 % | 1609 | 74 % | 1470 | 62 % | 1232 |
Aktualizovaná tabulka z loňského článku
Jak ale ukázal skutečný snímek jádra Navi 22, který připravil uživatel Nemez (snímek v úvodu), Infinity Cache dosahuje podstatně vyšší hustoty než 1 MB na mm², konkrétně 1,63 MB na mm². 128 MB Navi 21 tak nezabralo 128 mm² křemíku (jak se zdálo původně), ale pouze na 78,5 mm². Pokud by AMD chtěla dosáhnout datové propustnosti na úrovni GeForce RTX 3090 bez Infinity Cache, potřebovala (s ohledem na absenci podpory GDDR6X) 512bit sběrnici. Ta by stála (tedy její rozhraní a řadič) přinejmenším 62 mm² křemíku. Reálně o něco víc, protože lze jen těžko odhadovat, kolik křemíku by spotřebovala delší sběrnice Infinity Fabric obsluhující tuto 2× širší sběrnici. Zdá se tedy, že Infinity Cache úsporou křemíku na straně méně komplexního paměťového rozhraní sama téměř „splatila“ křemík, který stála její implementace. Energetická efektivita jádra, vazba na optimalizace pro vyšší taktovací frekvence a možnost využití úspornějších a zároveň levnějších GDDR6 namísto GDDR6X byly prakticky bonusy „zdarma“.
Při této hustotě se jeví podstatně reálněji všechny ty zvěsti o 256-512MB Infinity Cache na čipech architektury RDNA 3. On se tu totiž začínal rýsovat jeden problém: Nové výrobní procesy zvládají ještě celkem použitelně zmenšovat logiku, ale se škálováním SRAM jsou na štíru. 5nm proces TSMC oproti 7nm zvýší denzitu (počet tranzistorů na plochu) 1,8× pro logiku, ale pouze 1,3× pro SRAM. Pokud by SRAM / Infinity Cache zabírala významnou část plochy jádra a nové procesy by ji nezmenšovaly, rostly by její proporce na úkor logiky. Jenže nyní vyplývá, že Infinity Cache zabírá skoro o 40 % méně plochy, než se zprvu zdálo, a k tomu během letošního roku vyplynuly informace, podle nichž AMD u větších čipů generace RDNA 3 neumístí Infinity Cache do jednoho čipletu s logikou, ale do samostatného křemíku (nebo samostatných kousků křemíku), které budou sloužit jako datové projky mezi čiplety s logikou. Tyto aktivní propojky (ať už je AMD nazve jako můstek, interposer či nějak jinak) budou vyráběné na starším procesu (6nm) než logika (5nm), což dává smysl. 5nm proces by SRAM příliš nezmenšil, ale byl by dražší, takže starší 6nm proces je v tomto ohledu výhodnější.
Zdroje:























