
NVLink propojí grafické čipy vzájemně i s procesorem rychleji než PCIe

Další novinka z GDC 2014 umožňuje realizovat vzájemné propojení (několika) grafických čipů vzájemně i vytvoření spoje přímo mezi grafickým jádrem a procesorem…
Rozhraní NVLink se objeví na grafických čipech architektury Pascal, o které jsme mluvili v souvislosti se změnami v roadmapě a nasazením 3D / HBM pamětí. Reálné produkty tedy můžeme čekat někdy v roce 2016.

NVLink bude úzce souviset s unifikovanou pamětí Pascalu. V první generaci půjde o propojení jednotlivých zařízení (které nabídne jisté výhody oproti PCIe), druhá generace by měla být rozšířena o koherenci cache jednotlivých čipů.
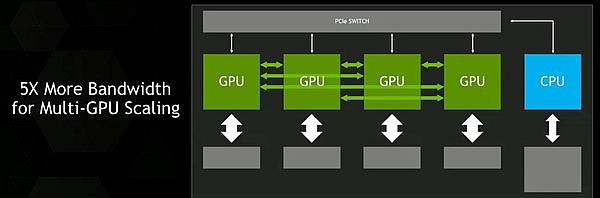
Rozhraní využívá programovacího modelu PCIe (podporuje i DMA), ale hardwarová implementace bude odlišná. Podle Nvidie se přenosová rychlost dostaně na úroveň 5-12× vyšší než u PCI Express. Za podstatnější parametr ale považujeme latence. Ty by proti PCIe měly být snížené, ale oficiální materiály Nvidie konkrétní čísla neuvádějí. Současným problémem akcelerace výpočetních úloh prostřednictvím GPU jsou právě latence PCIe (spíš než přenosová rychlost). Zatímco GPU dokáže řadu úloh zpracovat rychleji než CPU, nevyplácí se u mnoha typů úloh této akcelerace využívat, protože přenos dat do GPU a zpět k CPU je srovnatelný s výpočetním časem, za který úlohu zpracuje CPU. Vliv těsnějšího spojení procesoru s grafickým jádrem v poslední době demonstrovala například AMD s APU Kaveri, kde některé výpočty bylo možné provést rychleji než v případě využití samostatného grafického jádra (i s několikanásobně vyšším teoretickým výkonem). Rozhraní optimalizované pro výpočetní nasazení tak může významným způsobem zvýšit reálný výpočetní výkon systému.

K propojení jednotlivých GPU není třeba víc než sady GPUgenerace Pascal. Propojení s procesorem už je trochu specifičtější záležitost. Především proto, že daný procesor musí být vybaven rozhraním NVLink, což žádný z čipů na trhu není. Nvidia proto v rámci konsorcia OpenPower spolupracuje s IBM, jejíž nová generace čipů by měla být NVLinkem vybavena. Teoreticky lze čekat, že se rozhraní objeví i na dalších generacích SoC řad Tegra; architektura ARM je poměrně flexibilní co se implementace obvodů a rozhraní třetích stran týká. Pokud jde o AMD a Intel, zůstává otázkou, zda by se některý z těchto výrobců chtěl nechat přesvědčit. Určitá naděje může být u Intelu - na druhou stranu v jeho zájmu jsou především prodeje vlastního výpočetního hardwaru, který vzešel z architektury Larrabee. Pokud se nebude cítit ohrožen systémy postavenými na kombinaci hardwaru IBM a Nvidie, půjde spíš vlastní cestou.
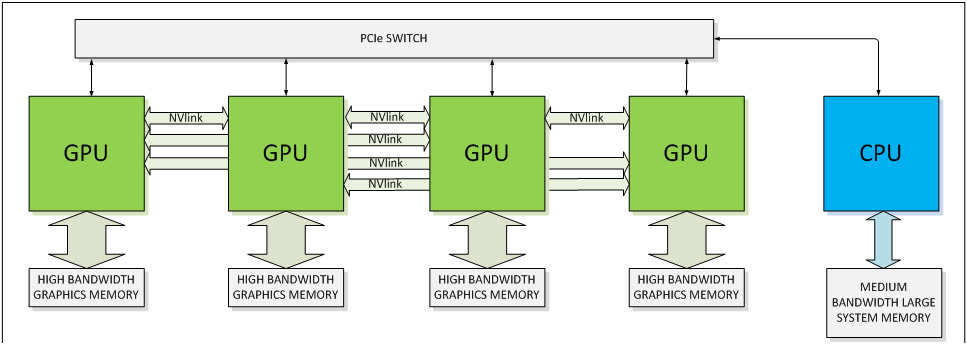
Jak už ze situace vyplývá, NVLink je rozhraní určené pro profesionální výpočetní sféru - v herních produktech patrně nebude využíván (možná by mohl posloužit v rámci SLI namísto stávajícího rozhraní). Pokud je ovšem rozhraní rychlejší a zároveň má nižší latence než PCIe, byla by škoda, pokud by zůstalo proprietárním řešením a nestal se z něj průmyslový standard, který by mohl PCIe nahradit.























