
Scheduler Alder Lake není všemocný, Intel počítá s optimalizacemi vývojářů
Architektura procesorů Alder Lake složená z velkých a malých jader má řešit rozložení úloh mezi nimi hardwarovým schedulerem. Ten však nezaručuje ideální výsledek…
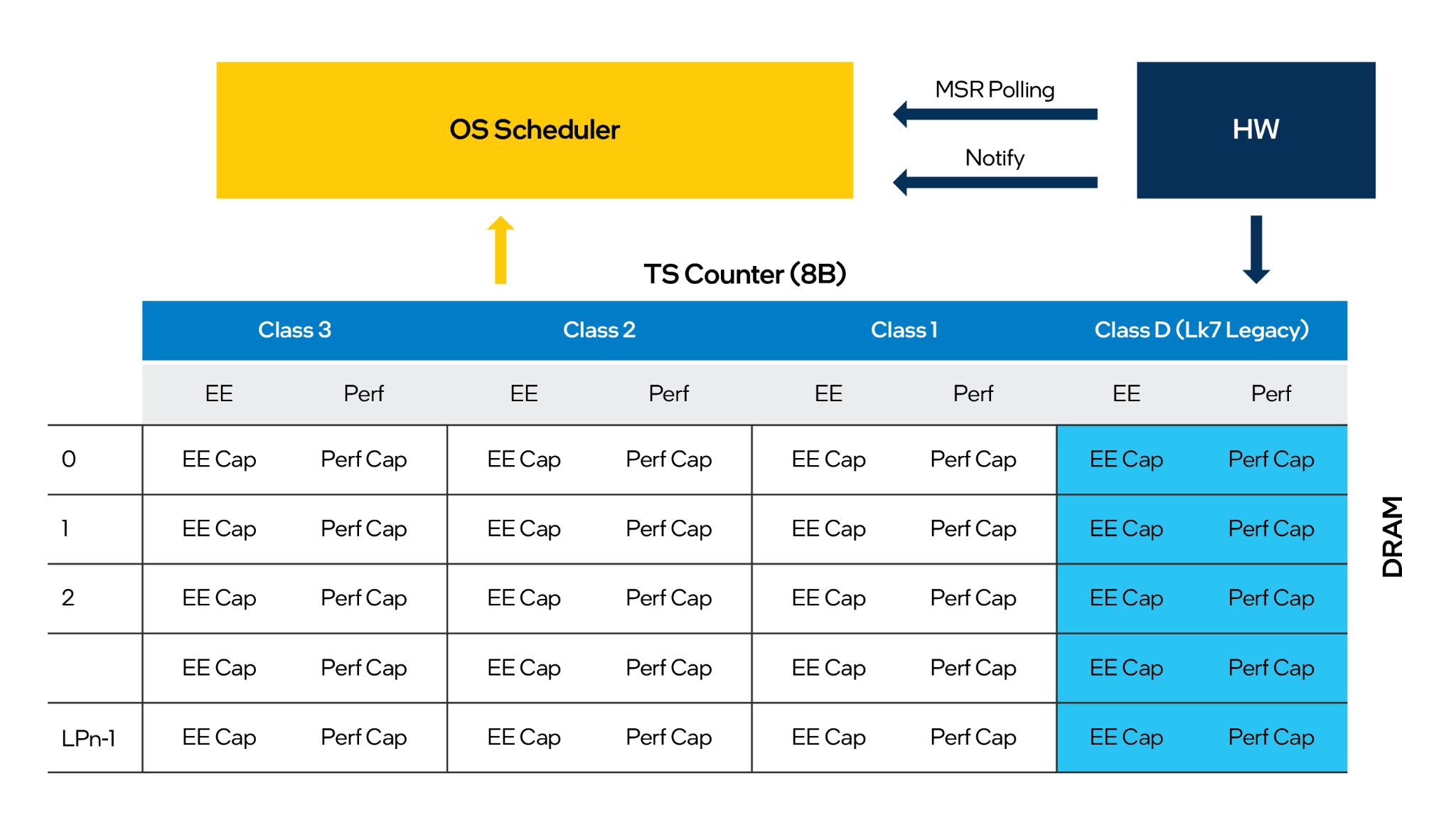
Intel zveřejnil tzv. Hybrid architecture optimization guide for developers, tedy příručku určenou vývojářů k optimalizaci softwaru pro hybridní architekturu. Z ní vyplývá, že hardwarově řízený scheduling, který předává operačnímu systému data, na jejichž základě mají být jednotlivé úlohy přiřazovány malým nebo velkým jádrům, nemusí volit přístup, který je skutečně optimální. Intel proto vybízí k optimalizacím ze strany vývojářů a popisuje tři typy možných scénářů:
- No optimizations - situace, kdy na procesoru běží standardní aplikace, která neobsahuje specifické optimalizace pro tuto architekturu. Rozložení zátěže mezi velká a malá jádra záleží čistě na tom, jak situaci vyhodnotí hardwarový obvod (který závěry svého algoritmu předá operačnímu systému). Může docházet k situacím, kdy vedlejší úloha poběží na velkém jádru nebo naopak klíčové úloha na malém.
- „Good“ scenario - situace, kdy vývojář podnikne základní kroky k optimalizaci úlohy pro Alder Lake. Obnáší vytvoření systému úloh na základě počtu velkých jader nebo maximálního počtu vláken (cílících na velká jádra) klíčových pro úlohu a nastavení priority (vysoká / nízká) vláken přes QoS API, aby tato vlákna cílila na správná jádra.
- „Best scenario“ - vytvoření dvou skupin vláken („hybrid-aware tasking system“), kdy první skupina cílí na výkonná jádra a sekundární (např. kompilace shaderů, mixování zvuku, dekomprese a další úlohy, které nejsou kritické pro výsledný výkon).

Ukázka rozložení zátěže mezi velkými (světle modrá) a malými (světle šedá) jádry Alder Lake
Intel dále uvádí diagram uspořádání a datového propojení velkých a malých jader (níže), který v podstatě vysvětluje, proč SiSoft při testování Alder Lake zaznamenal vysoké latence při potřebě komunikace mezi velkými a malými jádry, v jejímž důsledku bylo výhodnější při takových úlohách malá jádra nevyužívat:
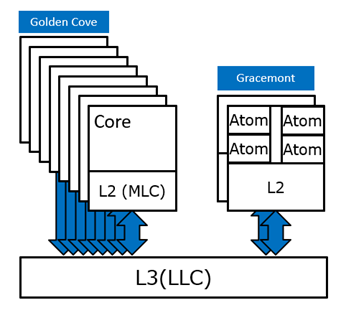
Zatímco velká jádra (Golden Cove) nesou každé vlastní L2 cache a každé má k dispozici vlastní datový kanál k L3 cache, malá jádra sdílí připojení k L2 cache po čtyřech a jeden kanál k L3 cache obsluhuje jádra čtyři. Komunikace mezi velkými a malými jádry je tedy podstatně pomalejší (dosahující vyšších latencí) než komunikace mezi malými jádry vzájemně nebo velkými jádry vzájemně.
Zdroje:






















