
Proč má Skylake-X 4× větší L2 cache než Skylake bez X?

S procesory Skylake-X (HEDT) se Intel odhodlal k restrukturalizaci cache oproti dosavadním modelům řady Skylake. To je samo o sobě natolik zajímavé, že si stojí za to položit otázku: Proč?
Pokud totiž dochází ke změně rozvržení cache, pak se to obvykle děje mezigeneračně, se změnou architektury procesoru jako takové. I mezigeneračně ale Intel obvykle nedělal změny takového rozsahu, jaké nastaly při přechodu mezi procesory Skylake a Skylake-X. Když před pár dny došlo na ohlášení těchto procesorů, mohli jste se dočíst, že velikost L2 cache stoupla 4× na jádro a velikost L3 cache naopak klesla 1,8× na jádro. Pro přesnější představu vězte, že z 256kB L2 se stala 1024kB L2 a L3, která dosahovala u Broadwell-E 2,5 MB na jádro, v případě Skylake-X dosahuje 1,375 MB na jádro. Jinými slovy objem L2 cache stoupl o 768 kB, objem L3 klesl o 1125 kB na jádro.
Některé články dále řeší inkluzivitu / exkluzivitu, tedy že doposud L3 cache kopírovala obsah L2 cache, což se u Skylake-X již nebude dít a dále hit- / miss rate 4× větší L2 cache, tedy jak se díky vyšší kapacitě L2 zvýší pravděpodobnost, že v ní budou ležet právě ta data, která v daný okamžik jádro potřebuje. Z toho pak vyplývá šance na zvýšení IPC.
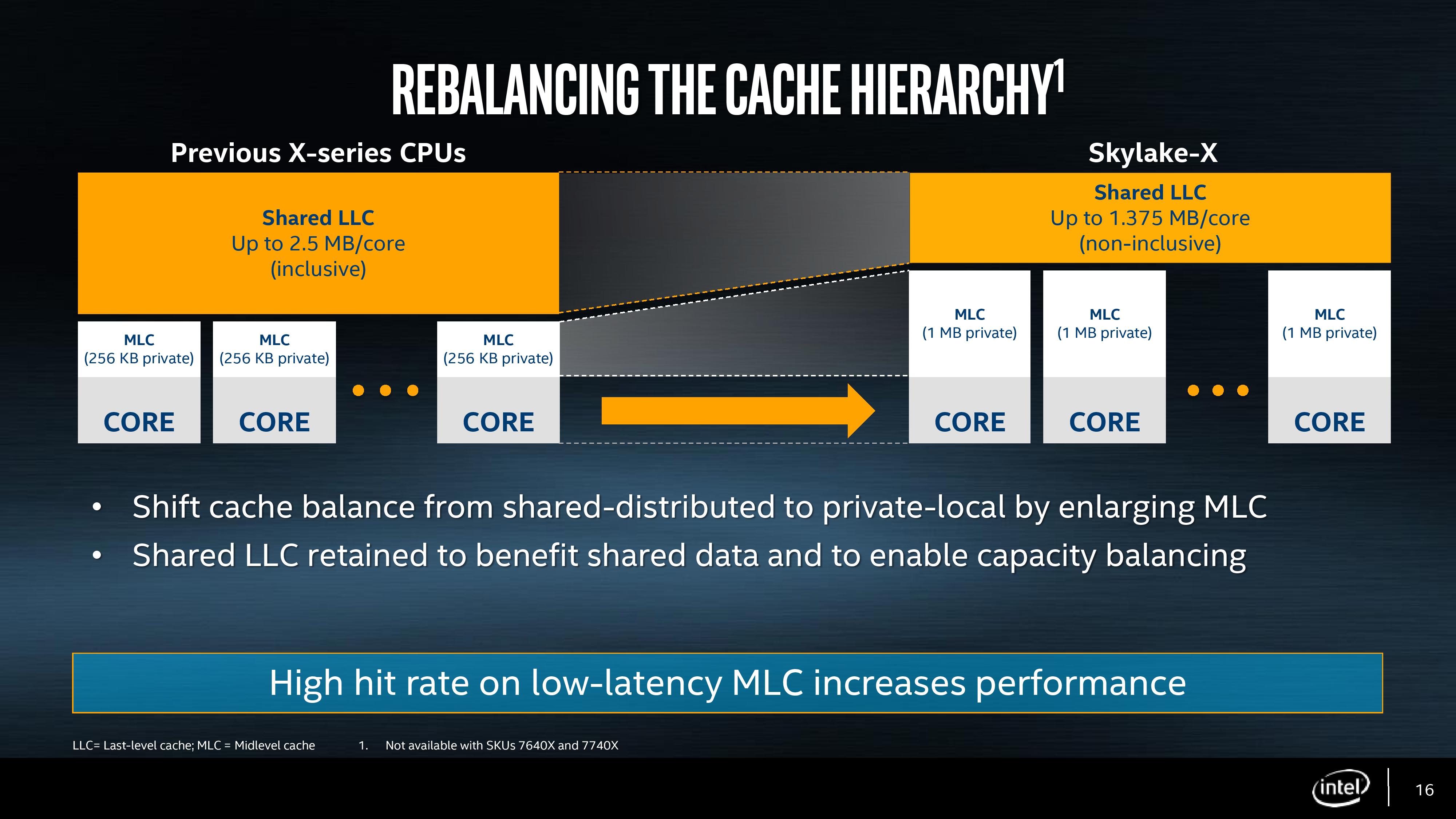
Co se ve článcích o Skylake-X nedočtete, je, zda neklesne hit rate menší L3 cache (a jaké dopady na IPC to bude mít) a hlavně, proč se vlastně Intel k tak zvláštnímu kroku odhodlal. Právě v případě této otázky bychom se mohli dopracovat ke smysluplné odpovědi. Začněme ale trošku jinde. Minulý týden David naťukl, že Intel bude vyrábět Skylake-X jako monolitické jádro, což spojoval s technologickou nadřazeností Intelu (pokud si to špatně nevykládám - pokud si to vykládám špatně, uvede to jistě na pravou míru v blogovém příspěvku ;-).
Intel zajisté v mnoha ohledech technologický náskok má, ale rozhodně nejsem přesvědčený o tom, že právě a zrovna Skylake-X vyrobený z jednoho kusu křemíku - oproti Ryzen ThreadRipperu ze dvou - je jeho projevem. Osmijádrový čip Zeppelin, základ Ryzenu, měří zhruba 195 mm², šestnáctijádrový monolit by s ohledem na fakt, že plocha zabraná čipsetem a komunikačním rozhraním neroste lineárně s počtem jader, měřil zhruba 340 mm² a čtyřiadvacetijádrový monolit do 450 mm², což je méně, než u high-endových grafických čipů. Podobně velké čipy nejsou pro TSMC, GlobalFoundries ani Samsung ničím nerealizovatelným.
Důvodem pro odlišnou koncepci mnohojádrových procesorů bude něco jiného, konkrétně odlišná firemní filozofie, která je dána jak historií posledních let, tak cílovými produkty, které obě firmy ze svých procesorů staví. Na jedné straně máme Intel se silným finančním zázemím, evolučním vývojem jdoucím na jistotu a na druhé straně máme rozpočtem omezenou AMD, která potřebovala v rámci své nabídky přijít s revolucí, kterážto nemohla skončit jako neúspěch. V tomto světle skutečností není překvapivé, že Intel své čipy po krocích mezigeneračně zvětšuje, až se dostal do situace, kdy si může dovolit i více než desetijádrový monolit, zatímco AMD byla v situaci, kdy si nemohla dovolit riskovat, že monolit nevyjde. Šla proto na jistotu s osmijádrovými čipy, které mají vysokou výrobní výtěžnost a ze kterých může skládat různé produkty.
Druhou příčinou jsou produkty. AMD se dala cestou modularity, protože krom samostatných procesorů, tedy Ryzenů z jednoho Zeppelinu, ThreadRipperů ze dvou Zeppelinů a Epyců ze dvou až čtyř Zeppelinů, plánuje vyrábět také výpočetní čipy integrující Zeppeliny a GPU Vega spojená v jednom pouzdře. Při poměrně širokém využití tohoto návrhu je zkrátka výhodnější navrhnout jeden modul a ten skládat a kombinovat s dalšími ve výsledné produkty. Pro Intel, který naopak nabízí základní procesory vždy doplněné integrovanou grafikou, taková cesta vhodná není - hypotetické šestnáctijádro složené například z jader Core i7-7700K, by neslo čtyři integrované grafiky, které by byly nevyužitelné a tím pádem pouze zvyšovaly výrobní náklady. Proto je pro Intel vhodnější každý produkt navrhnout jako samostatný čip, tím pádem (pokud možno) monolitický.

Proč vůbec řeším odlišnou filozofii obou firem, když měla být řeč o cache? Protože ta je toho přímým důsledkem. AMD, která má čip Zeppelin složený ze dvou čtyřjádrových stavebních jednotek CCX, používá samostatnou L3 pro každý čtyřjádrový CCX blok. Zeppeliny lze pak jednoduše řetězit, aniž by situaci s L3 bylo třeba nějak explicitně řešit. To je zásadní výhoda konceptu L3 u Zenu. Nevýhoda pak spočívá v tom, že u neoptimalizovaného vícevláknového kódu může popsané řešení přinášet o něco nižší výkon. Intel naproti tomu má u monolitických procesorů jednu velkou společnou L3 cache, která nabízí určitou výhodu v případě neoptimalizovaného vícevláknového kódu, ale zároveň přináší jinou komplikaci. Čím více jader čip má, tím více klientů se ke společné L3 cache snaží přistupovat. S počtem klientů, které s L3 cache komunikují, roste i objem datových přenosů a v určitém bodě bude dosaženo stavu, kdy výkon začne být omezován datovou propustností (jednoduše si to představte jako server, ze kterého stahuje třeba 100 uživatelů oproti serveru, ze kterého stahuje 1000 uživatelů). Právě to se jeví jako pravděpodobný důvod, proč Intel zároveň s navýšením počtu jader zvýšil čtyřnásobně kapacitu cache druhé úrovně - právě to totiž zredukuje datové přenosy do L3 cache.
Nad dalšími dopady ale můžeme až do vydání podrobných testů jen spekulovat. Zvětšení L2 cache může na jednu stranu zvýšit IPC, protože data, která se do 256kB L2 nevešla a byla „tahána“ z L3, se nyní do 1024kb L2 mohou vejít a přístup k nim bude rychlejší. Na druhou stranu je možné, že přístup k 1024kb L2 nebude až tak rychlý, jako jsme byli zvyklí u 256kB L2 a latence budou mírně vyšší. Teoreticky by mohly vzrůst latence při komunikaci mezi L2 a L3, která již není „L2-inkluzivní“. Je tedy možné, že pro některé situace (kdy se více dat vejde do L2) dojde ke zvýšení IPC, pro jiné (kdy bude nutné přistupovat k L3) naopak IPC klesne. O kolik nová struktura cache zvýší průměrný výkon, bude závislé na nárůstu těch situací, kdy se pozitivně projeví kapacita L2 cache oproti situacím, kdy se negativně projeví nižší kapacita a předpokládaná pomalejší dostupnost L3 cache.
Neobvyklý krok je podle všeho důsledkem výrazně zvýšeného počtu jader v rámci jednoho kusu křemíku. Důvodů může být více, ale tím, který je zřejmý už ze samotné konfigurace čipu, je snaha udržet pod kontrolou objemy datových přenosů (mezi L2 a L3), které vzrostly s počtem jader, jež je třeba zásobovat daty. Vliv na IPC se v tuto chvíli zdá být jen vedlejším projevem, který ovšem může být v některých situacích nezanedbatelně příznivý. Jak moc, prozradí recenze.





















