
Test nástřelu levnější sestavy pro FCAT

Koncem minulého týdne jsem se lehce rozpovídal na téma předražené testovací sestavy pro FCAT (Frame Capture and Analysis Tool) a navrhl sestavu levnější. Dnes se pokusím ověřit její použitelnost…
Kapitoly článků
4. Použitelnost záznamu
Toto je ukázkový výstup části záznamu (jiná část než ta, o níž byla řeč na předchozí straně, navíc jsem z výstupu odstranil černé 40řádkové VBlanky). Všímejte si především délky pruhů ([scanlines]):

Ukázka výstupu v Excelu - komprimovaný záznam H.264
Řádky, které jsou zvýrazněny, berte jako synchronizační značku pro následné srovnání s nekomprimovaným záznamem (jde o stejné místo). Nyní si všimněte zejména jednobodových řádků – Extractor si jich dle očekávání všiml a skutečně je zaznamenal jako samostatné snímky. To je samozřejmě špatně, vnáší nám to do výsledků chaos. Pro názornost jsem spáchal javascriptík, který z toho, co ve screenshotu Excelu vidíte, vyrobí barevnou tabulku odpovídající právě udané barvě pruhů a zmíněné jednořádkové přechody „zméněvýrazní“ („vyšedí“):
Protože jsou však tyto přechody snadno predikovatelné a vždy dlouhé přesně 1 řádek, dá se s nimi počítat a bylo by možné vyrobit nástroj, který by výstup Extractoru upravil a tyto přechody eliminoval (a to nikoli jen jejich vymazáním, ale započítáním každé části daného přechodu k tomu danému pruhu). Ovšem v situaci, kdy by náhodou docházelo ke generování takto rychlých skutečných snímků („jednořádkových“) by už byla komprese nepoužitelná, protože by se v ní tyto snímky ztrácely. Musíme tedy přitoupit k využití nekomprimovaného záznamu.
Výše uvedenou ukázku v Excelu si tedy nyní srovnejme s podobnou ukázkou ze stejné části scény (proto ta „synchronizační značka“ v podobě zvýrazněných řádků), ale zaznamenanou nekomprimovaně (samozřejmě se liší barvy pruhů a také délky snímků, protože podruhé to proběhlo jinak rychle, ale to je vedlejší, podobnosti v tom jistě sami najdete):

Ukázka výstupu v Excelu - nekomprimovaný záznam (YUY2)
Jak vidíte, v nekomprimovaném záznamu žádné „jednořádkové přechody“ nejsou. Třikrát hurá, tento záznam skutečně JE plně použitelný, protože z něj lezou smysluplné výsledky. Přibarveno a aromatizováno to vypadá takto:
Je to super. Dokonce je jedno, že ty pruhy v nekomprimovaném záznamu ve skutečnosti nejsou jednobarevné, ale skládají se z několika barviček. Pro názornost jsem vytáhl úrovně na extrém (v nekomprimovaném i komprimovaném záznamu):

Srovnání záznamku bez komprese a s kompresí - zvětšení a zvýraznění
Tyhle artefakty naštěstí Extractoru nevadí, zdá se, že s jistou tolerancí barevných odchylek počítá. Dokonce bych řekl, že tuším, proč. Inu, protože ani karta Datapath VisionDVI-DL nemá ty pruhy v záznamu úplně přesně a stále stejně barevné. Připomeňme si snímek z minulého dílu, který pocházel ze záznamu provedeného na PC Perspective (tam jsou i ty 40řádkové černé VBlanky):
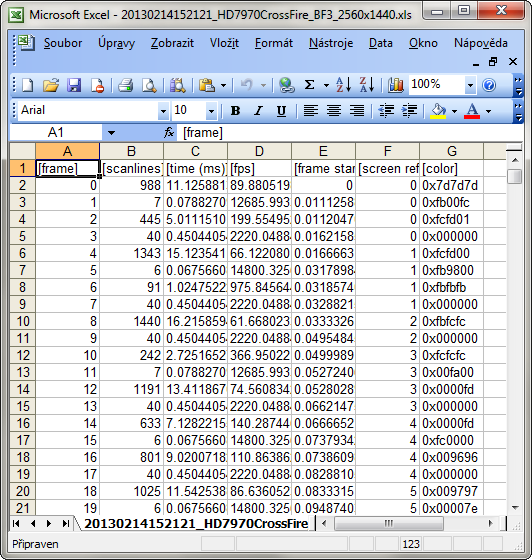
Excel_-_20130214152121_HD7970CrossFire_BF3_2560x1440.xls
Všimněte si řádků 6, 8 a 10. Je to jeden snímek (roztáhlý přes 3 obrazovky), byť každý zaznamenaný jako trošku jiná barva. Zjevně se tato chybovost vyskytuje i v původním drahém řešení a je s ní počítáno. Naše levnější řešení je tedy v tomto ohledu srovnatelné, protože ani původní drahé řešení není „kulevsky přesné“ ;-).
předchozí kapitola
následující kapitola
Kapitoly článků
4. Použitelnost záznamu


















