
AMD uvedla Milan-X s V-cache, Instinct MI200 (až 5× Ampere) a ohlásila Zen 4c

Na akci Accelerated Data Center Premiere uvedla AMD procesory Epyc Milan-X zvyšující v cílových aplikacích výkon až o 80 % oproti současným Epycům, dále akcelerátory Instinct MI250X a naťukla i Zen 4…
CEO AMD Lisa Su s kolegy představili a ohlásili řadu produktů určenou pro servery, HPC řešení, cloud a superpočítače. Došlo prakticky na vše očekávané, ale i několik překvapení.
Instinct MI200
Začněme akcelerátory. Top model řady Instinct MI200 nazvaný Instinct MI250X přinesl rámcově ty parametry, které jsme avizovali minulý týden: Řešení ze dvou čipletů s architekturou CDNA 2 obsahující 220 CU dosahující až 1700 MHz tedy zůstává. Zaměříme se tedy jen na upřesnění a rozdíly.

Arcturus
V první řadě je potřeba uvést informaci o počtu tranzistorů. Je pravdou, že počet tranzistorů stoupl zhruba na dvojnásobek oproti čipu Arcturus. Ukázalo se však, že 50 miliard uváděných četnými zdroji pro Arcturus (viz např. TPU a jiné databáze) je silně nadsazená hodnota, přičemž realita je skoro poloviční (25,6 miliardy). Tudíž oním dvojnásobkem nebude ~100 miliard tranzistorů pro Aldebaran, ale 58,2 miliard (v souvislosti s tím by zasloužila zrevidovat i plocha Arcturu, která jistě nebude stejnými zdroji uváděných 750 mm² - očekával bych asi o stovku méně).

OAM modul osazený Arcturem = Instinct MI250(X)
Dále je potřeba zmínit, že GPU je vyráběno 6nm procesem; je však možné, že údaj o 7nm výrobě byl správný, jen ne názvoslovně aktuální. TSMC totiž původně vyvíjela 7nm EUV (N7+) proces, který nedosahoval očekávaných výsledků, takže se téměř nerozšířil a do širší nabídky se dostala až jeho doladěná verze, kterou TSMC označila jako 6nm (N6) proces.

Základní parametry N7+ a N6 jsou téměř totožné a je dost možné, že Aldebaran byl původně navržen na N7+, ale z důvodu zmíněných problémů počkal až na jejich (vy)řešení označované jako N6. Každopádně se Aldebaran a akcelerátory Instinct MI200 stávají prvními vydanými produkty AMD využívajícími EUV litografie.
| AMD Radeon Instinct MI60 | Instinct MI100 | Instinct MI250X | Instinct MI300 | Nvidia A100 | |
|---|---|---|---|---|---|
| GPU | Vega 20 | Arcturus | Aldebaran | Rigel | GA100 |
| architektura | GCN 4 | CDNA | CDNA 2 | CDNA 3 | Ampere |
| CPU | |||||
| formát | PCIe | PCIe | OAM | OAM | SXM4 / PCIe |
| CU/SM | 60 | 120 | 220 (256) | (384-512?) | 108 |
| FP32 jader | 3840 | 7680 | 14080 (16384) | (24k-33k?) | 6912 |
| FP64 jader | - | - | - | - | 3456 |
| INT32 jader | - | - | - | - | 6912 |
| Tens. Cores | - | ? | 880 | ? | 432 |
| takt | 1800 MHz | 1502 MHz | ≤1700 MHz | ? | 1410 MHz |
| ↓↓↓ T(FL)OPS ↓↓↓ | |||||
| FP16 | 29,5 | 184,6 | 383 | ? | 78 |
| BF16 | 92,3 | 383 | ? | 39 | |
| FP32 | 14,7 | 23,5 | 95,7 47,9 | ? | 19,5 |
| FP64 | 7,4 | 11,5 | 47,9 | ? | 9,7 |
| INT4 | 118 | 184,6 | 383 | ? | ? |
| INT8 | 59,0 | 184,6 | 383 | ? | ? |
| INT16 | 29,5 | ? | ? | ? | ? |
| INT32 | ? | ? | ? | ? | 19,5 |
| FP16 tensor | 184,6 | 383 | ? | 312/624* | |
| BF16 tensor | 92,3 | 383 | ? | 312/624* | |
| FP32 tensor | 46,1 | 95,7 | ? | 19,5 | |
| TF32 tensor | ? | 156/312* | |||
| FP64 tensor | 95,7 | ? | 19,5 | ||
| INT4 tensor | ? | 1248/2496* | |||
| INT8 tensor | 184,6 | 383 | ? | 624/1248* | |
| ↑↑↑ T(FL)OPS ↑↑↑ | |||||
| TMU | 240 | 480? | - | ? | 432 |
| sběrnice | 4096bit | 4096bit | 8192bit | ? | 5120bit |
| kapacita paměti | 32 GB | 32 GB | 128 GB | ? | 40 GB 80 GB |
| HBM2 | 2,0 GHz | 2,4 GHz | 3,2 GHz | HBM3? | 2,43 GHz 3,20 GHz |
| paměť. propustn. | 1024 GB/s | 1229 GB/s | 3277 GB/s | ? | 1555 GB/s 2048 GB/s |
| TDP | 300 W | 300 W | 500W 560W | ~600W? | 400 / 250 W |
| transistorů | 13,2 mld. | 50 mld. 25,6 mld. | 58,2 mld. | ? | 54,2 mld. |
| plocha GPU | 331 mm² | 750 mm² | ? | ? | 826 mm² |
| proces | 7 nm | 7 nm | 6nm | ? | 7 nm |
| datum | 2018 | 2020 | 2021 | 2022-2023 | 2020 |
*pouze v režimu sparsity
Vysvětlení si ještě žádají dva údaje TDP. Standardní provedení, které bude dostupné OEM partnerům, bude mít TDP 500 wattů. Verze na zakázku pro superpočítač Frontier je chlazená vodou, díky čemuž má TDP konfigurované na 560 wattů. Připomeňme, že i s ním dosahuje nakonec Frontier nižší celkové spotřeby, než se původně počítalo.
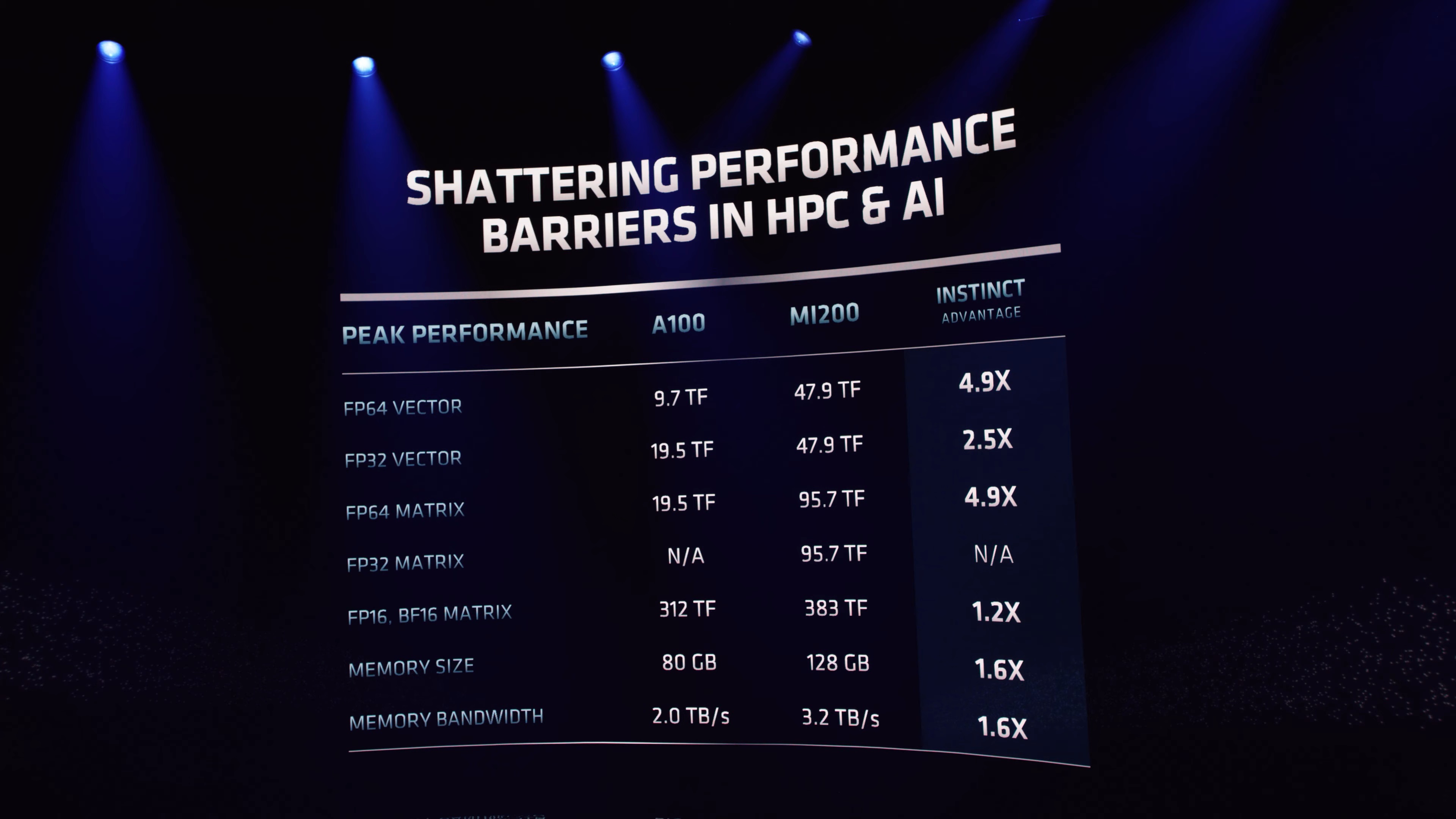
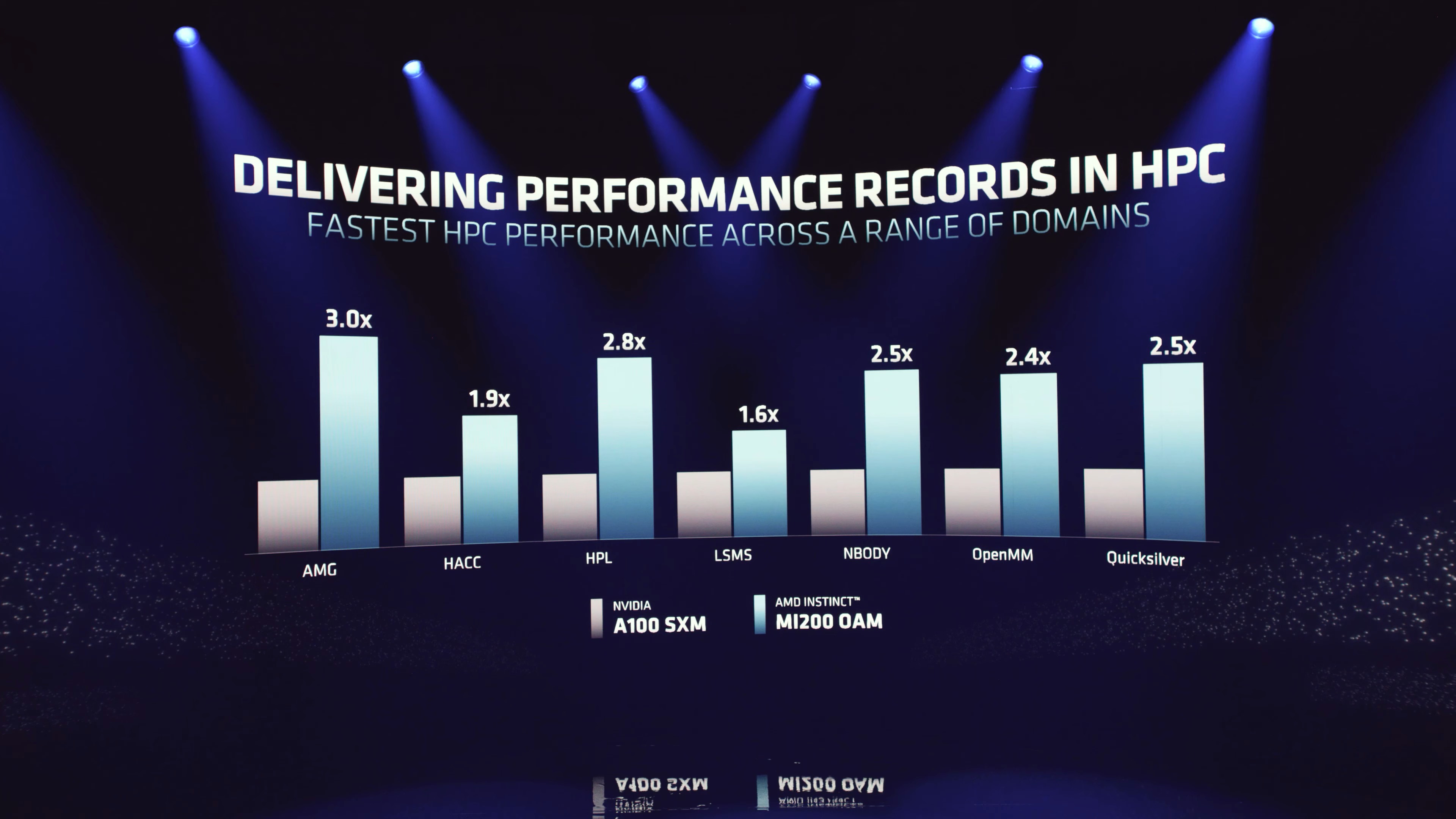
Teoretické a praktické rozdíly výkonu mezi Nvidia A100 a AMD Instinct MI250X
Mnoho se nemění na výkonnostních údajích. AMD oficiálně potvrdila ~5× vyšší vektorový výkon v FP64 oproti Nvidia (Ampere) A100 a kupodivu tato hodnota platí i pro tenzorový / maticový výkon v FP64. FP64 je nově nativní formát (pro CDNA 1 a starší byl nativním formátem FP32), což znamená, že FP32 je pro zcela neoptimalizovaný kód k dispozici ve stejném výkonu jako FP64 (tzn. 47,9 TFLOPS), ale podporován je tzv. packed formát (dosud používaný např. u přesnosti FP16), jehož využití (základní optimalizace kódu) umožňuje dosahovat dvojnásobného výkonu, tedy 95,7 TFLOPS FP32.
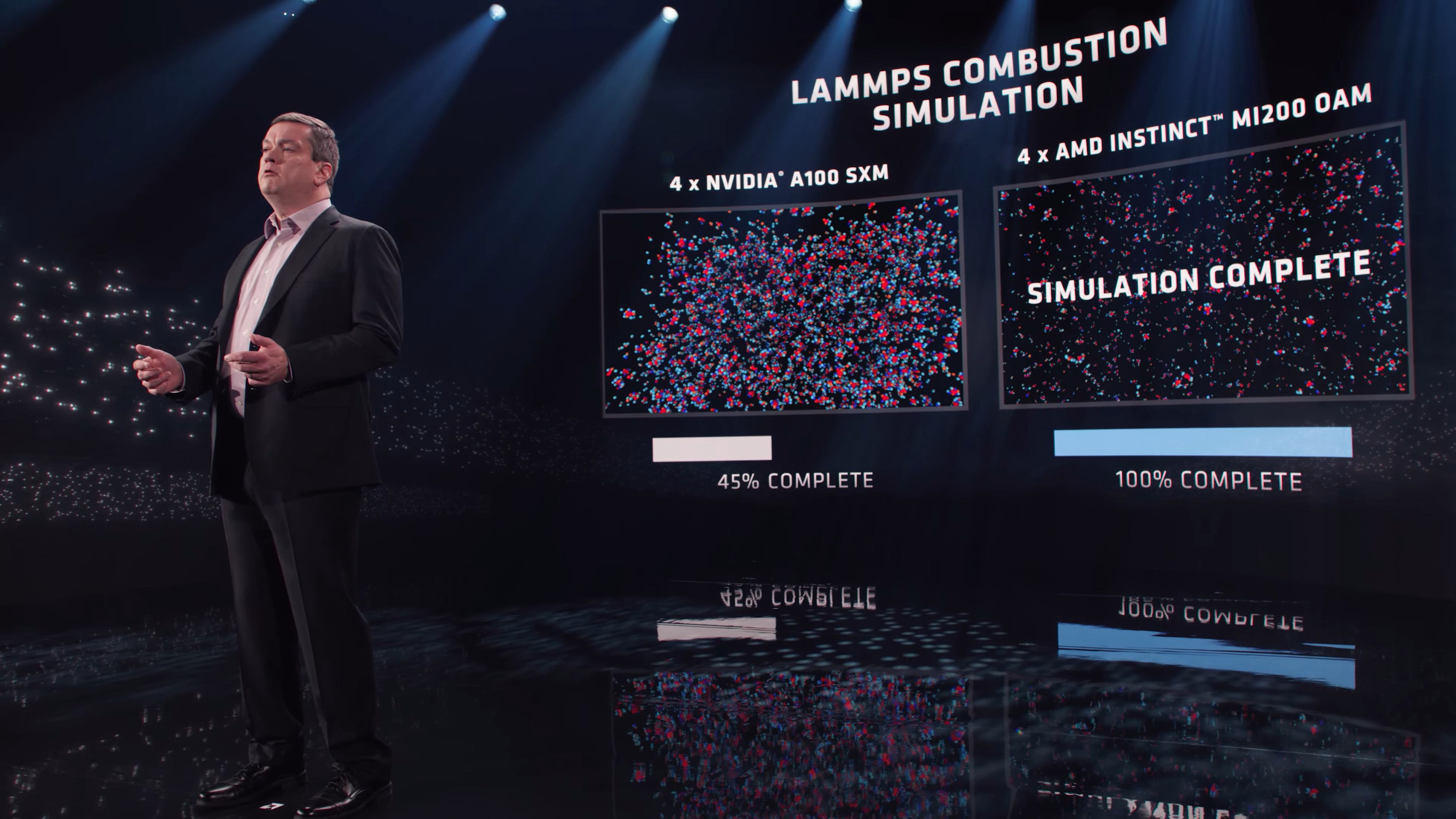

AMD vydala akcelerátory Instinct MI250X s 220 CU, 8 linkami Infinity Fabric a s podporou CPU koherence (specifikace v tabulce výše), dále Instinct MI250 s 208 CU, 6 linkami Infinity Fabric a bez podpory CPU koherence (jinak jsou specifikace totožné).


Kromě těchto dvou modelů v podobě OAM modulů se na začátek příštího roku chystá Instinct MI210 v provedení PCIe karty. Parametry zatím nebyly oznámeny, ale lze počítat se zhruba 300W TDP a tomu adekvátně nižším výkonem v trvalé zátěži.
Elevated Fanout Bridge 2.5D
Z technologického hlediska je Aldebaran zajímavý i metodou pouzdření a spojení jednotlivých čipletů vzájemně i čipletů s HBM2E.

AMD již k propojení nepoužívá ani podložku (interposer), ani můstky zapouštěné do substrátu, ale používá křemíkové můstky označované jako Elevated Fanout Bridge 2.5D. V jejich konceptu lze hledat paralely s technologiemi SPIL Fan-out Embedded Bridge (FOEB) a TSMC InFO-L, se kterými AMD nejspíš spolupracovala.
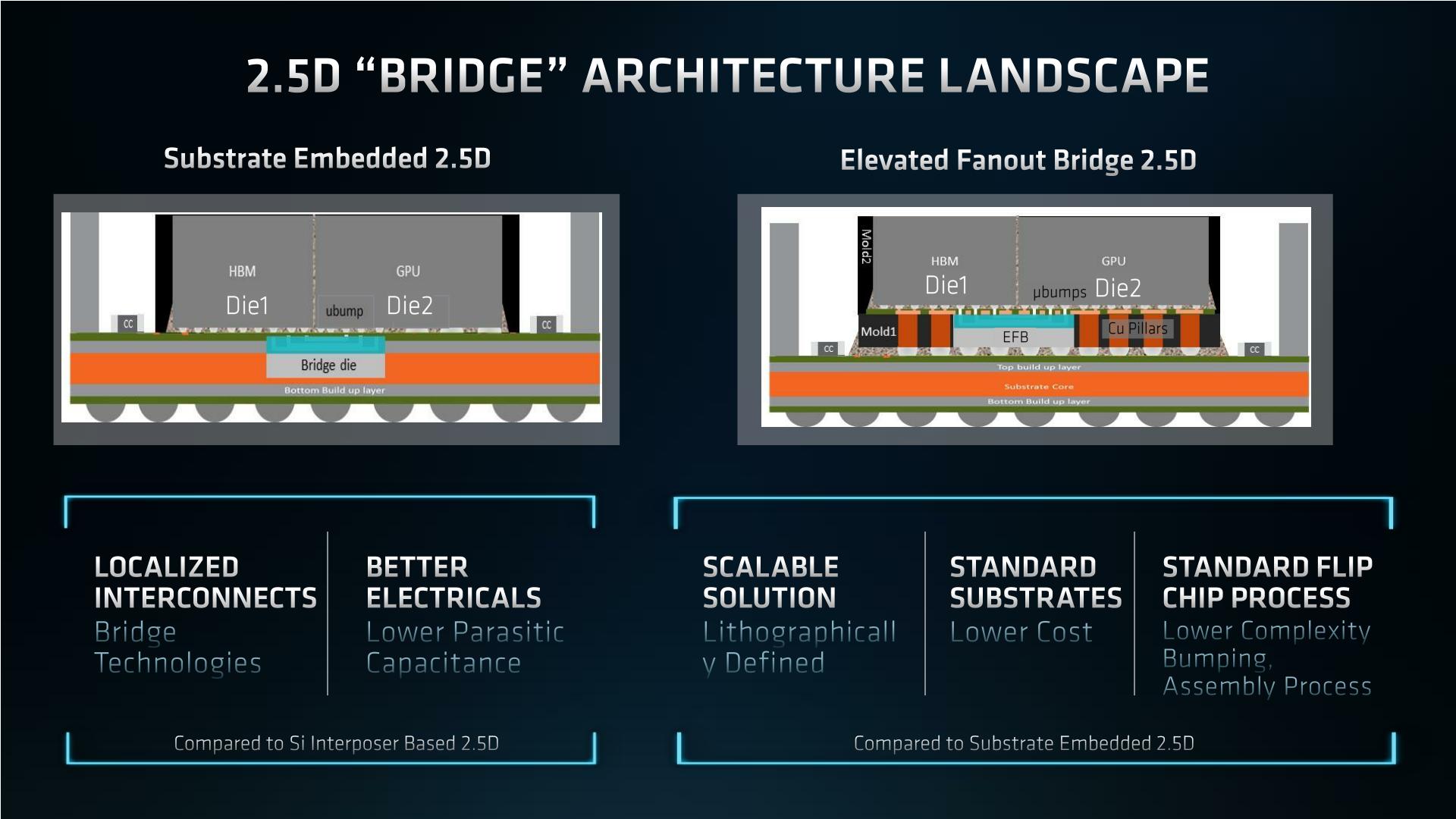
V čem je EFB řešení výhodné: Oproti použití monolitické křemíkové podložky (interposer) je levnější a energeticky výhodnější, oproti můstkům zapuštěným do substrátu odpadá zapouštění do substrátu, což zjednodušuje výrobu. Můstek sám o sobě tvoří jakési mezipatro mezi substrátem a samotným křemíkem spojovaných čipů. Díky tomu je možné na výrobu většiny prvků používat standardní nebo minimálně upravené metody polovodičové výroby, což usnadňuje a zlevňuje výrobu.
Superpočítač Frontier
O superpočítači Frontier (který stojí právě na akcelerátorech Instinct MI250X) bylo hovořeno jakožto o první EFLOPS systému v USA (nikoli na světě), což dává významný kredit zprávám o tom, že v Číně již existují dva systémy dosahující řádu EFLOPS, byť to vypadá, že jde o podstatně jednodušší stroje, které budou v reálných úlohách násobně pomalejší než systémy jako Frontier, Aurora nebo El Capitan.

8 OAM modulů Instinct MI250X (dva se sejmnutým chladičem)
Mimo obligátního srovnání ExaPindíků ještě stojí za zmínku, že instalace Frontier je téměř hotová a v nejblížší době se přejde ke spouštění. Začátkem roku bude systém předán k užívaní.
Epyc Milan-X / Zen 3 s V-cache
Milan-X byl produktem, o kterém začaly prosakovat první zmínky v souvislosti s V-cache, L3 cache navrstvenou na procesorovém čipletu.

Podle AMD toto řešení obsahuje celkem 804 MB cache. Toto číslo si můžeme rozepsat jako 512 MB (8 × 64) L3 V-cache, 256 MB (8 × 32) L3-cache, 32 MB (8 × 4) L2 cache a 4 MB (8 × 0,5) L1 cache.

Procesor je kompatibilní se stávajícími deskami pro Milan a kompatibilní je i softwarově - pro jeho nasazení je potřebná pouze aktualizace BIOSu. To ale nic nemění na faktu, že software optimalizovaný pro větší L3 cache může dosahovat vyšších výkonnostních nárůstů.


AMD uvádí, že u cílového softwaru lze pozorovat výkonnostní rozdíl oproti Epycům Milan i přes 50 %, což doložila testem srovnávajícím výkon Milan a Milan-X v Synopsys VCS používaném pro verifikaci návrhů čipů. Za jednotku času zpracoval Milan 24,4 úloh, zatímco Milan-X 40,6 úlohy, čímž dosáhl o 66 % vyššího výkonu.


Podle testů Microsoftu, v jehož Azure HBv3 již Milan-X běží, dosahuje o 80 % vyššího výkonu v leteckých simulacích a o 50 % vyššího výkon v automobilových crash-testech.

Milan-X bude dostupný v systémech Cisco, Dell, HPE, Lenovo a Supermicro.
Zen 4 a Zen 4c
AMD dále potvrdila přípravy 5nm Epyců s jádry Zen 4, jejichž výroba i vydání proběhne v roce 2022 (druhá polovina roku). Za pozornost stojí, že již nyní dodává AMD vzorky Epyců Genoa s jádry Zen 4 partnerům a podle Su se vyvíjejí velmi dobře.

Potvrzena byla plošně optimalizovaná verze jádra Zen 4, kterou AMD nakonec (naštěstí) nenazývá Zen 4D (což by se pletlo s 3D cache = V-cache), ale Zen 4c, kde „c“ nejspíš značí nasazení procesoru pro cloudové úlohy.

Zen 4c / Epyc Bergamo oproti Zen 4 přináší energetické optimalizace navíc, plošnou optimalizaci struktury cache, dosáhne až 128jádrové konfigurace, ale zůstane socketem-kompatibilní i ISA-kompatibilní s klasickým Zen 4 / Epyc Genoa.


Ve srovnání se současným 7nm Epyc Milan má Epyc Bergamo dosahovat 2× vyšší denzity, 2× vyšší energetické efektivity a >1,25× vyššího výkonu. Jinými slovy na plochu jednoho jádra Zen 3 se vejdou dvě jádra Zen 4c, která (obě) budou mít stejnou spotřebu (jako jedno jádro Zen 3) a každé o více než 25 % vyšší výkon. Tedy výkon na jednotku plochy bude minimálně 2,5× vyšší. K vydání dojde pravděpodobně koncem zimy nebo začátkem jara roku 2023.
| Zen | Zen 2 | Zen 3 | Zen 4 | Zen 4c | Zen 5 | |||
|---|---|---|---|---|---|---|---|---|
| řada | Naples | Rome | Milan | Trento | Genoa | Bergamo | Turin | ? |
| jader | 32 | 64 | 64 | 64 | 96 | 128 | 192 | 256 |
| PCIe | 3.0 | 4.0 | 4.0 | 4.0 | 5.0 | 5.0 | ? | ? |
| DDR | 4-2666 | 4-3200 | 4-3200 | 4 | 5-5200 | 5 | 5-6000 | 5 |
| TDP | 200W | 280W | 280W | ? | 400W | ? | ≤600W | |
| vs. | Intel | Intel | Intel | Intel | Intel | ARM | Intel | ARM |
| čas | 2017 | 2019 | Q1 2021 | Q4 2021 | H2 2022 | H1 2023 | ? | ? |
Různé
Poslední zásadní novinka - softwarová, ale zajišťující procesorům AMD další trhy - bylo ohlášení podpory SAP S/4HANA na procesorech Epyc.

Accelerated Data Center Premiere by se dala shrnout jako pro AMD historická událost. Poprvé za celou historii společnosti totiž vydala zároveň procesorové a grafické produkty, které jsou velmi silně konkurenceschopné a to ještě s dost podstatným náskokem.
Pokud jde o procesory, obstojí Xeony Ice Lake od Intelu oproti 32jádrovým Epycům Rome (Zen 2), ale na 64jádrové již nestačí, o Epyc Milan s jádry Zen 3 nemluvě. V této konkurenční pozici nyní AMD posiluje nabídku o Epyc Milan-X s jádry Zen 3 s V-cache, který v některých typech úloh přidává desítky procent výkonu. Nástupce Xeonů Ice Lake, odkládaný Sapphire Rapids, by podle dosavadních informací neměl být dostupný dříve než půl roku po Milan-X. Přinést může asi o 10-15 % vyšší IPC oproti standardnímu Zen 3, ale nejspíš při nižším počtu (56) jader.

V akcelerátorech se AMD ročním intervalem mezi první a druhou generací architektury CDNA podařilo předběhnout Nvidii výkonem v 10 ze 14 podporovaných formátů. Převážně jde o formáty s vyšší přesností. Náskoky se pohybují od nižších desítek procent až po více než dvojnásobek nebo téměř pětinásobek u FP64, tensor FP64 a packed FP32. Nová výpočetní architektura Nvidie - Hopper - se rovněž neočekává dříve než za půl roku.
Zdroje:























