Intel: Ponte Vecchio je ~2× rychlejší než Nvidia A100 / Ampere

Intel na HotChips zveřejnil další údaje o akcelerátorech Ponte Vecchio. Předložil teoretické výkonnostní hodnoty i výsledky benchmarků, podle nichž je akcelerátor 1,4-2,5× rychlejší než Nvidia A100.
O akcelerátoru Ponte Vecchio hovořil Intel veřejně poprvé v polovině listopadu 2019. V březnu 2021 jej představil se sloganem „From idea to silicon in less than 2 years“, tedy „Od myšlenky ke křemíku v méně než dvou letech“. Již v listopadu 2019 jej však Intel představil jako základní kámen superpočítače Aurora. Ten je v plánu již od roku 2015, ale všechny produkty (čipy či karty), které připadaly v úvahu jako výpočetní akcelerátory pro Auroru, skončily neslavně:
- Xeon Phi - Knights Hill: zpožděn v důsledku 10nm procesu, nepodporoval akceleraci AI
- Xeon Phi - Knights Mill: přesunut z 10nm procesu na 14nm výrobu, nepodporoval akceleraci FP64
- Nervana Lake Crest: AI akcelerátor získaný akvizicí společnosti Nervana, propadák
- Habana Goya / Gaudi: akvizice dalšího výrobce AI akcelerátorů, které dosud nejsou na trhu
- Xe-HP: modulární řešení, které dle JPR trpělo vysokou spotřebou, zrušeno
- Xe-HPC alias Ponte Vecchio
Ponte Vecchio je řešení složené ze 47 kousků křemíku, z nichž některé budou vyráběné Intel 7 procesem, některé pak 7nm a 5nm procesem TSMC.


Intel představil strukturu cache, která se jeví jako silná stránka produktu. Se strmě rostoucím výkonem výpočetních akcelerátorů přestávají paměťové technologie držet krok a ani HBM3 na 8192bit sběrnici ne vždy stíhají. I u výpočetních akcelerátorů proto začíná pomalu (ale jistě a výrazně) narůstat kapacita cache. Dále Intel zveřejnil teoretické výkonnostní charakteristiky pro některé datové formáty. Jde však o zlomek hodnot, které pro své produkty uvádějí AMD a Nvidia, což je ostatně patrné z naší tabulky:
| AMD MI250X | AMD MI300 | Nvidia A100 | Nvidia H100 | Intel P. Vecchio | ||
|---|---|---|---|---|---|---|
| GPU | Aldebaran | Rigel | GA100 | GH100 | Ponte Vecchio | |
| architektura | CDNA 2 | CDNA 3 | Ampere | Hopper | Xe-HPC | |
| formát | OAM | OAM | SXM4 | SXM5 | OAM | |
| CU/SM | 220 | ? | 108 | 132 | 128 | |
| FP32 jader | 14080 | ? | 6912 | 15872 16896 | 16384 | |
| FP64 jader | - | - | 3456 | 8448 | ? | |
| INT32 jader | - | - | 6912 | 8448 | ? | |
| Tensor Cores | 880 | ? | 432 | 528 | ? | |
| takt | 1700 MHz | ? | 1410 MHz | ? | ~1600 MHz | |
| ↓↓↓ T(FL)OPS ↓↓↓ | ||||||
| FP16 | 383 | ? | 78 | 120 | ? | |
| BF16 | 383 | ? | 39 | 120 | ? | |
| FP32 | 95,7 47,8 | ? | 19,5 | 60 | 52 | |
| FP64 | 47,8 | ? | 9,7 | 30 | 52 | |
| INT4 | 383 | ? | ? | ? | ? | |
| INT8 | 383 | ? | ? | ? | ? | |
| INT16 | ? | ? | ? | ? | ? | |
| INT32 | ? | ? | 19,5 | 30 | ? | |
| FP8 tensor | ? | 2000/4000* | ? | |||
| FP16 tensor | 383 | ? | 312/624* | 1000/2000* | 839 | |
| BF16 tensor | 383 | ? | 312/624* | 1000/2000* | 839 | |
| FP32 tensor | 95,7 | ? | 19,5 | 60? | ? | |
| TF32 tensor | ? | 156/312* | 500/1000* | 419 | ||
| FP64 tensor | 95,7 | ? | 19,5 | 60 | ? | |
| INT8 tensor | 383 | ? | 624/1248* | 2000/4000* | 1678 | |
| INT4 tensor | ? | ? | 1248/2496* | ? | ? | |
| ↑↑↑ T(FL)OPS ↑↑↑ | ||||||
| TMU | -? | ? | 432 | 528 | ? | |
| LLC | 16 MB | ? | 40 MB | 50 MB | 408 MB | |
| sběrnice | 8192bit | ? | 5120bit | 5120bit | 8192bit | |
| paměť | 128 GB | 128 GB | 40 GB | 80 GB | 80 GB | 128 GB |
| HBM | 3,2 GHz | HBM 3 | 2,43 GHz | 3,2 GHz | 4,8 GHz | HBM 3 |
| pam. prop. | 3277 GB/s | ? | 1555 GB/s | 2048 GB/s | 3072 GB/s | ? |
| TDP | 500 W 560 W | ? | 400 W | 700 W | ≥600 W | |
| transistorů | 58,2 mld. | ? | 54,2 mld. | 80 mld. | ? | |
| plocha GPU | 2× ? | 4× ? | 826 mm² | 814 mm² | 2× 640 mm² | |
| proces | 6 nm | 5nm | 7 nm | 4nm | Intel 7 TSMC N5 TSMC N7 | |
| datum | 11. 2021 | 2023 | 5. 2020 | 11. 2020 | 2022? | ? |
Z dostupných údajů se zdá, že zatímco AMD Instinct MI250X je zaměřen tak nějak univerzálně na klasické (vektorové) i maticové výpočty (AI) a Nvidia A100 spíš na maticové (AI), Intel Ponte Vecchio se snaží tak nějak vklínit mezi ně. V klasických FP32 / FP64 výpočtech je podstatně rychlejší než Nvidia A100, srovnatelný s Instinct MI250X, ale pokud bude kód optimalizován pro FP32-packed formát, může být Mi250X téměř 2× rychlejší. Naproti tomu tenzorové / maticové / AI výpočty jdou podle specifikací Ponte Vecchio skoro stejně rychle jako Nvidia A100 a přinejmenším některé až 2-4× rychleji než AMD Instinct MI250X.
Zdá se, že ambicí Intelu bylo nabídnout řešení, které bude na podobné úrovni jako silné stránky produktů AMD a Nvidie, ovšem bez slabých stránek. Což by mohlo vyjít, kdyby Intel vydal Ponte Vecchio před rokem. Nyní je srovnávání s tímto hardwarem spíše formalitou - Nvidia koncem roku vydává Hopper, AMD někdy po Novém roce CDNA 3 / Instinct MI300.
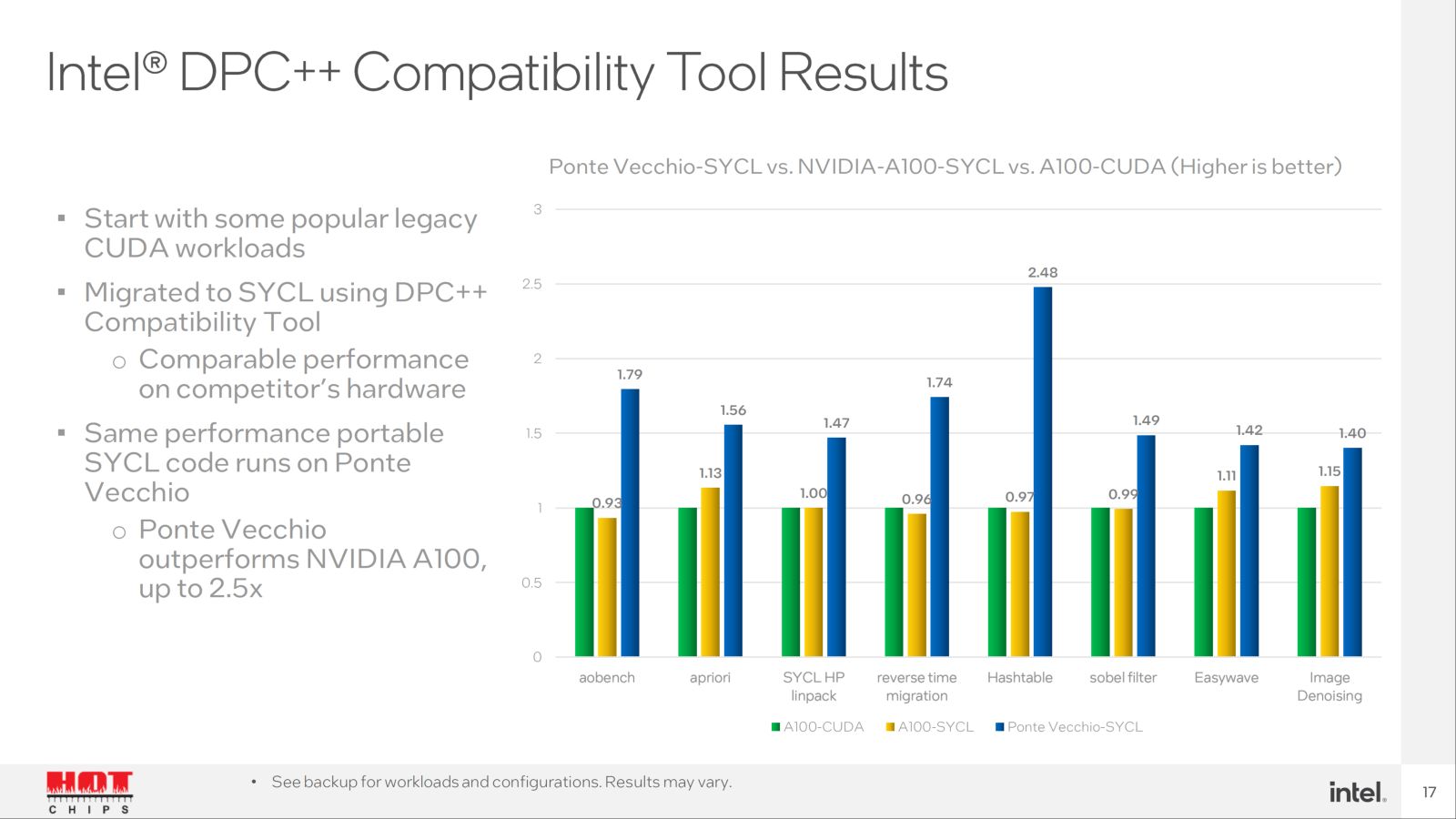
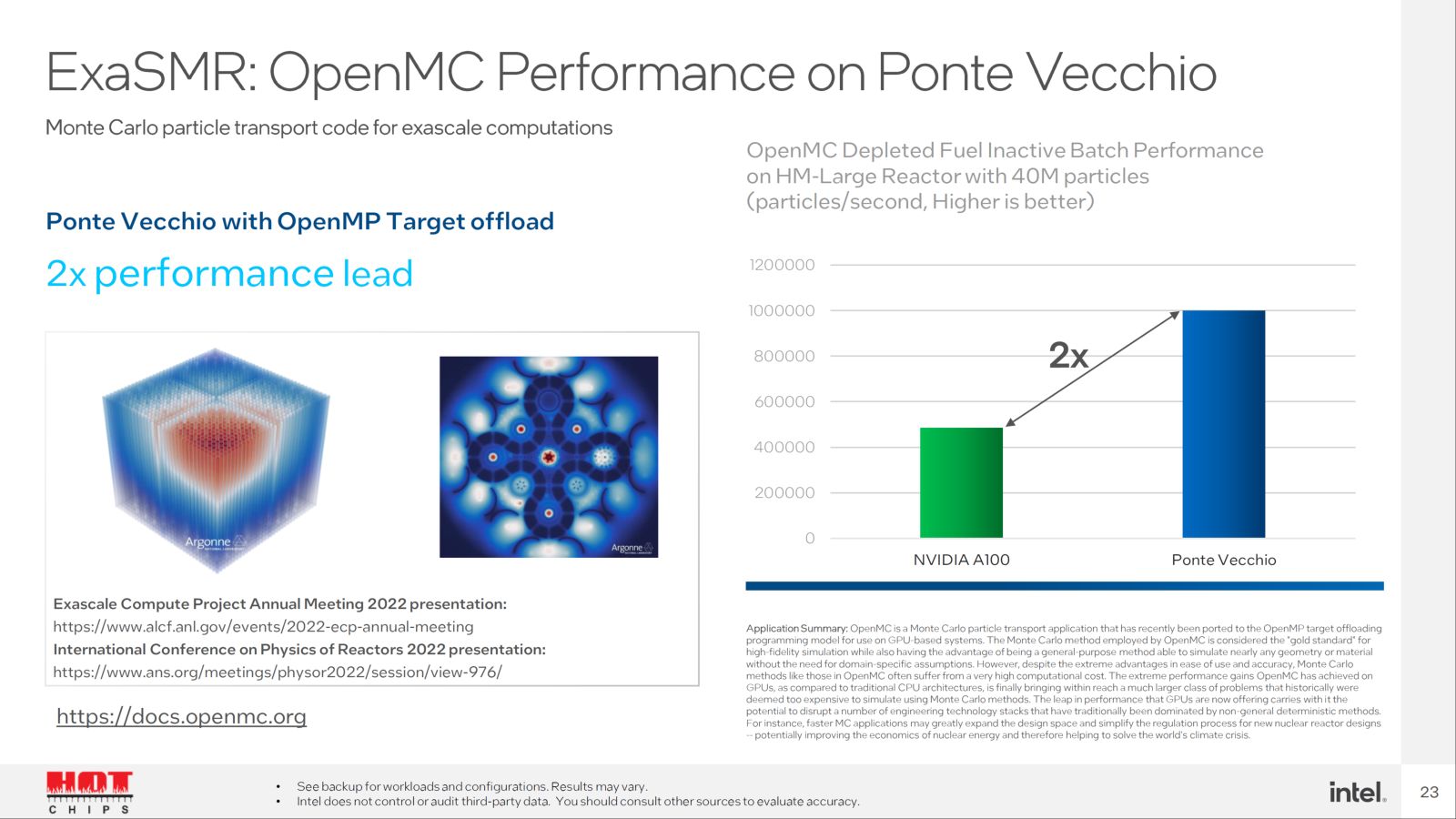
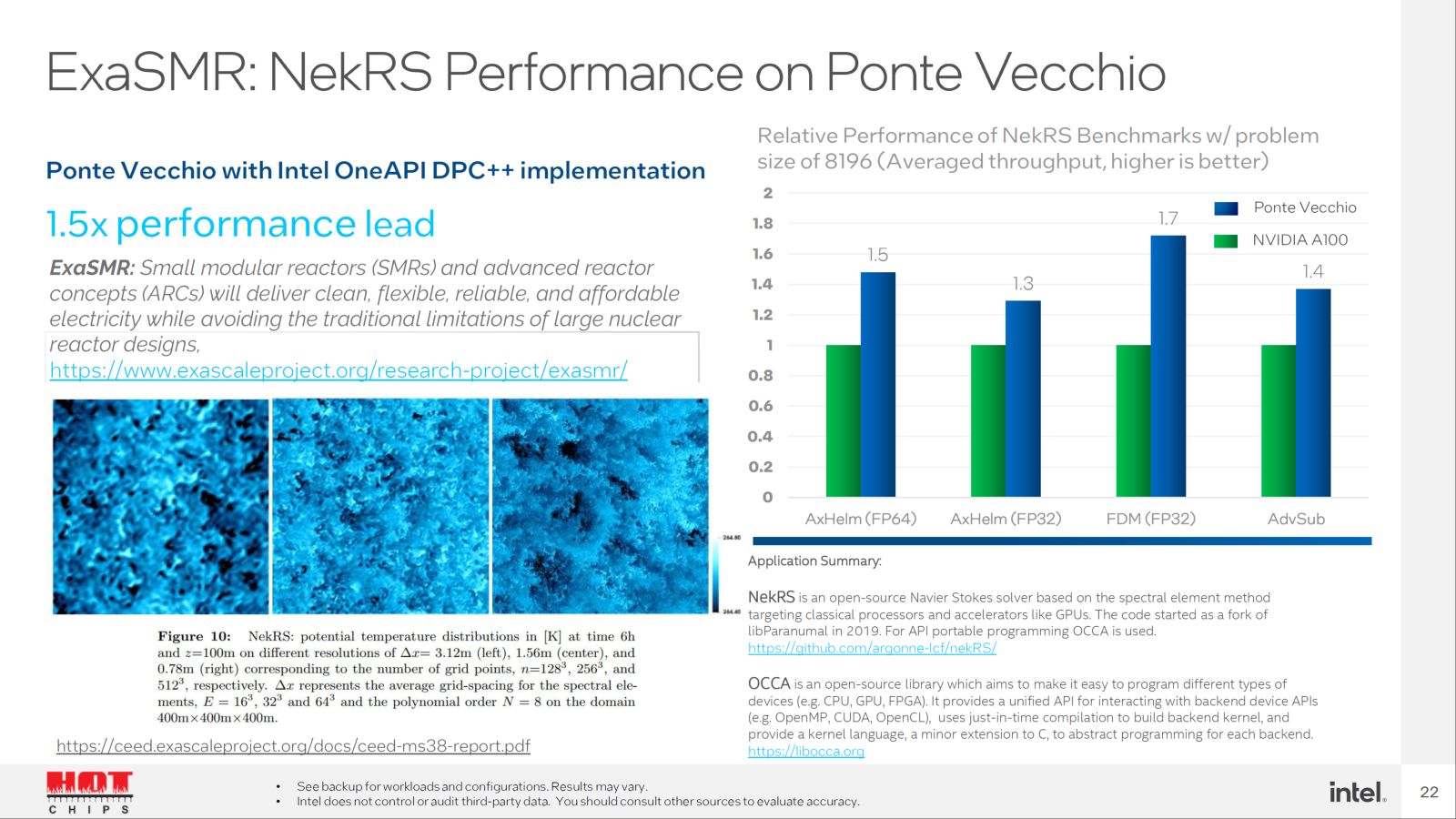

Výše vidíte Intelem zveřejněné výsledky benchmarků, které srovnávají Ponte Vecchio s Nvidia A100. K nim jen dvě poznámky: 1. Jak už bylo řečeno, tyto dva produkty proti sobě v praxi stát nebudou. Nelze však Intelu vytýkat, že nesrovnává s Hopper, která ještě není dostupná. 2. Testované zátěže jsou většinou univerzální výpočetní úlohy (vektorové výpočty), přičemž těžištěm Nvidia A100 jsou maticové výpočty (AI). Zájemce o vysoký univerzální výpočetní výkon by neváhal mezi Nvidia A100 a Intel Ponte Vecchio, ale mezi AMD Instinct MI250X a Ponte Vecchio. Jak ale naznačují čísla v tabulce, kdyby Intel v těchto typech zátěže porovnával Ponte Vecchio a Instinct, nemohl by se ve slajdech chlubit ~2× vyšším výkonem. Stejně tak by se jím nemohl chlubit, kdyby srovnával Ponte Vecchio a A100 v maticových výpočtech. Srovnání tedy příliš nereflektují obvyklé chování potenciálního zákazníka.
Zkrátka když zemědělec kupuje polní techniku, bude vybírat mezi dvěma traktory různých značek, nikoli mezi traktorem a motorkou. A stejně tak závodník bude vybírat mezi dvěma motorkami, nikoli mezi traktorem a motorkou. Intel zde ovšem předkládá srovnání svého traktoru oproti konkurenční motorce při orbě brambor.
Zdroje: