
AMD: Nejlepší jádra v Ryzen Master nemusejí být nejlepší pro scheduler Windows

AMD se vyjádřila k situaci, kolem které se točí online diskuze: Vysvětluje, proč jádra CPU, která jsou v softwaru Ryzen Master označena jako nejlepší, nemusejí být nejvhodnější pro scheduler Windows…
Ve článku, který se týkal profilu pro procesory Ryzen 3000, jsme se věnovali problematice scheduleru operačního systému Windows. Scheduler sám o sobě je poměrně hloupý, respektive zastaralý a přimět ho fungovat efektivně na nových architekturách nemusí být jednoduché. Důvodem je, že vznikl (a tudíž byl i pro ně optimalizován) na desktopových procesorech Intel, které měly několik jader a jednu společnou a jednotnou L3 cache. Aby u těchto procesorů nedocházelo k lokálnímu přehřívání při jednojádrové zátěži (kdy dochází k nejvyššímu boostu, tedy je dosahováno nejvyšší frekvence a tím i nejvyššímu zahřívání daného jádra), byl scheduler navržen tak, aby zátěž periodicky přesouval mezi dvěma jádry a tím dával střídavě jednomu a druhému čas na odpočinek (vychladnutí).
Jak rostl počet jader, stávala se maximální spotřeba jednoho jádra (i při maximálním boostu) pouhým zlomkem TDP celého procesoru. Zatímco u historického dvoujádrového procesu mohlo mít jedno boostující jádro podobnou spotřebu jako obě neboostující - což znamená že spotřeba blížící se TDP mohla být „koncentrována“ do jednoho jádra, dnes - kdy spotřeba jednoho jádra bývá kolem 10-15 wattů - to takový problém není. Zvlášť když ono boostující jádro u takového mnohojádrového procesoru obklopuje spousta nevyužitého („studeného“) křemíku, kam se může teplo rozlévat.
Scheduler Windows nicméně i na nových procesorech funguje stále stejně. Jenže za ta léta se nezměnil pouze počet jader, ale změnila se i architektura. Konkrétně jde o L3 cache. Zatímco u původních dvou či čtyřjádrových procesorů Intelu existovala jedna společná L3 cache, u mnohojádrových procesorů Intelu a AMD je v současnosti situace opačná. U Intelu se sice L3 cache tváří jako jednotná, ale ve skutečnosti je segmentovaná každé jádro má k dispozici vlastní segment. Pokud potřebuje sáhnout do segmentu náležejícímu jinému jádru, děje se tak přes sběrnici mezi jádry. To je mírně pomalejší. U AMD je situace odlišná. Aby mohla vytvářet procesory s vyšším počtem jader (architektura Intelu postavená na výše popsaném řešení končí na 28 jádrech), dostává u procesorů AMD každá čtveřice jader (CCX) vlastní segment L3 cache. Tato čtveřice má ke své L3 cache velmi rychlý přístup. Pokud jádro potřebuje data ze segmentu L3 cache nacházejícího se v jiném CCX, děje se přístup přes sběrnici Infinity Fabric mezi CCX a to je mírně pomalejší. Pokud jádro potřebuje přístup k datům v segmentu L3 cache, který se nachází na jiném křemíkovém modulu / čipletu, musí si pro ně sáhnout přes externí Infinity Fabric spojující jednotlivé kousky křemíku a to je výrazněji pomalejší.
Pokud tedy scheduler operačního systému Windows přehazuje zátěž mezi dvěma jádry, která se nacházejí v odlišném CCX nebo dokonce na odlišných kouscích křemíku, dochází ke snížení výkonu, neboť musejí být společně s tímto přehazováním zátěže přesouvána i data mezi jednotlivými CCX či čiplety. Což je samozřejmě nevýhodné.
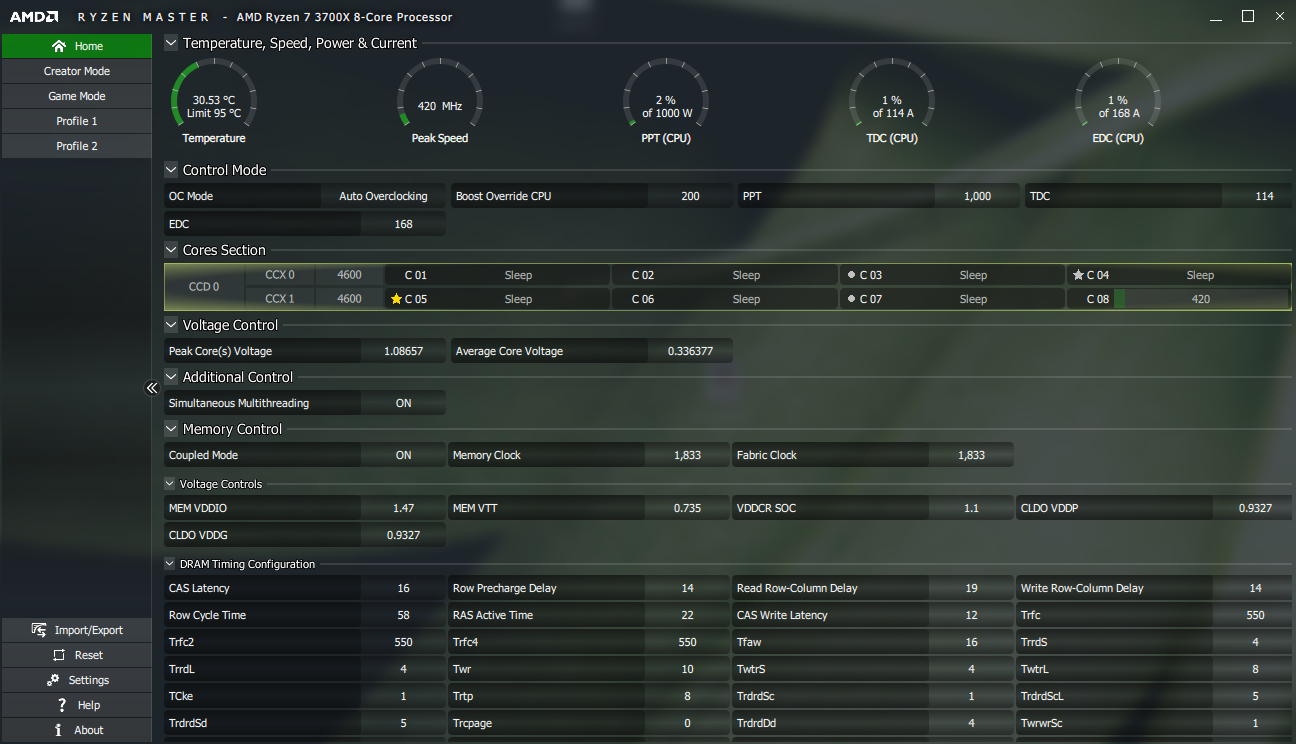
Tolik k úvodu, který je potřeba, abychom mohli vysvětlit, co nám vysvětluje AMD. V softwaru Ryzen Master jsou vyznačena tzv. nejlepší jádra. Pro každý CCX blok je jedno jádro označené hvězdičkou (to je nejlepší v daném CCX bloku) a jedno jádro označené puntíkem (to je druhé nejlepší v rámci CCX bloku). Jedna z hvězdiček je zlatá - ta značí nejlepší jádro v rámci celého křemíkového čipletu (u osmijádrového procesoru tedy nejlepší jádro vůbec). Objevovaly se otázky, proč AMD nezajistí, aby scheduler Windows přehazoval zátěž mezi dvěma nejlepšími jádry v celém procesoru.
AMD k tomu, aby scheduler Windows v rámci možností usměrnila, používá tzv. CPPC2, neboli Collaborative Power and Performance Control 2. Jde o middleware implementovaný prostřednictvím BIOSu a ovladačů čipsetu. CPPC2 využívá vlastní systém tzv. preferovaných jader. Snaží se s pomocí CPPC2 přimět scheduler Windows, aby zátěž procesoru oscilovala mezi těmito preferovanými jádry. Podle AMD nemusí a obvykle nejsou tzv. „preferovaná jádra“ (z pohledu CPPC2) být totožná s tzv. „nejlepšími jádry“ (z pohledu Ryzen Master).
Proč: Důvod je prostý. Nejlepší jádra vyznačená v Ryzen Master odpovídají skutečně nejlepším jádrům z hlediska elektrických vlastností procesoru. Jejich označením AMD ukazuje uživateli, která jádra mají teoreticky nejvyšší OC potenciál. Jenže to je pouze jeden z aspektů, které jsou vyhodnocené z pohledu CPPC2 pro preferovaná jádra. Pro AMD totiž nemusí být žádoucí, aby zátěž oscilovala za každou cenu mezi dvěma nejlepšími jádry. Pokud jsou tato dvě jádra v různých CCX nebo v různých kouscích křemíku, docházelo by při přehazování zátěže k výše popsanému přesouvání obsahu L3 cache mezi CCX bloky nebo mezi křemíky a to by mohlo u některých aplikací výkon degradovat více než o kolik by ho zlepšily mírně vyšší frekvence elektricky nejlepších jader (z pohledu Ryzen Master).
Logicky tedy vyplývá, že preferovanými jádry budou pravděpodobně (1) nejlepší jádro v rámci daného CCX a (2) druhé nejlepší jádro v tomto CCX. Prvním preferovaným jádrem ale nemusí být ani nejlepší jádro z celého procesoru (značené zlatou hvězdičkou v Ryzen Mater). Protože při jednojádrové zátěži dochází k přehazování zátěže mezi dvěma jádry, nemá z tohoto hlediska smysl hodnotit elektrické vlastnosti jednoho jádra - je potřeba hodnotit průměr dvou nejlepších jader v CCX. A může se zkrátka stát, že v průměru je lepší kombinace stříbrného jádra a druhého nejlepšího v jednom CCX, než zlatého a druhého nejlepší v druhém CCX. To druhé nejlepší, co sdílí CCX se zlatým jádrem, totiž může být výrazně horší než to druhé nejlepší, co sdílí CCX se stříbrným jádrem.
Protože je žádoucí držet zátěž v rámci jednoho CCX, dokud nejsou využita všechna jádra CCX (opět proto, aby nedocházelo ke zpomalujícím přesunům dat mezi L3 různých CCX), jsou jako další preferovaná jádra z hlediska CPPC2 označena zbývající dvě v rámci toho CCX (tzn. 3 a 4), kde již byla vybrána preferovaná jádra 1 a 2.
Zlaté jádro (nejlepší dle Ryzen Master) se tak teoreticky může dostat z hlediska CPPC2 dostat ke slovu až jako 5. v pořadí. Číslo 6 dostane jádro, které je ve stejném CCX jako zlaté a je v Ryzen Master označeno tečkou a 7. a 8. budou zbývající dvě jádra. Tento popis je příkladem jedné konkrétní modelové situace, která byla vybrána tak, aby se na ní dalo vysvětlit, proč ani zlaté jádro (dle Ryzen Master) nemusí být mezi prvními čtyřmi preferovanými (dle CPPC2). Samozřejmě může nastat situace, kdy zlaté jádro bude prvním preferovaným. Dále je potřeba říct, že tento ilustrační příklad je zjednodušen, neboť podle AMD existují ještě další vlastnosti, ke kterým je při výběru preferovaných jader (CPPC2) přihlíženo.
| příklad podle Anandtechu | ||||
|---|---|---|---|---|
| CCX | jádro číslo | CPPC2 data / pořadí | Ryzen Master | pořadí podle SMU / API |
| 0 | 0 | 148 / #3 | #6 | |
| 1 | 144 / #4 | #8 | ||
| 2 | 151 / #1/2 | puntík | #3 | |
| 3 | 151 / #1/2 | hvězda | #2 | |
| 1 | 4 | 140 / #5 | zlatá hvězda | #1 |
| 5 | 136 / #6 | #5 | ||
| 6 | 132 / #7 | puntík | #4 | |
| 7 | 128 / #8 | #7 | ||
Popisek tabulky aneb obsah článku extrémně stručně: Z důvodu přehazování jednojádrové zátěže schedulerem Windows musí AMD zajistit, aby byla zátěž přehazována mezi jádry v rámci jednoho CCX. Jinak by hrozil pokles výkonu daný zbytečnými přesuny dat (L3 cache) způsobenými schedulerem. Přehazování zátěže vytvářené schedulerem Windows se děje mezi dvojicí jader, tudíž pro AMD při rozhodnutí, mezi kterými jádry se bude přehazovat, není klíčové, které jádro je nejlepší (zde by to bylo jádro č. 4, tedy zlatá hvězda), ale která dvojice jader je v průměru nejlepší (zde dvojice jader číslo 2 a 3 aneb puntík a hvězda). Aby AMD přiměla scheduler Windows přehazovat výkon mezi těmito dvěma jádry, falešně prostřednictvím CPPC2 reportuje scheduleru, že umějí vyšší frekvenci než ostatní jádra („151“ [MHz]), čímž tuto dvojici dostane na první místo v preferenci scheduleru („#1/2“).
V Linuxu, kde ke zbytečnému přehazování jednojádrové zátěže nedochází, využívá scheduler jádra čistě podle jejich kvality (pořadí v posledním sloupci podle API), což má za následek dosažení vyššího výkonu.
Nakonec si ještě můžeme vysvětlit, jak AMD prostřednictvím CPPC2 manipuluje se schedulerem Windows, aby ho alespoň v rámci jeho omezených možností přiměla k alespoň částečně optimálnímu fungování. Scheduler byl vyvinut tak, že je schopný pouze velmi jednoduchého rozlišení mezi jádry podle uvedené taktovací frekvence. Pro každé jádro může být hlášen jeden číselný údaj, který scheduler chápe jako frekvenci, které je toto jádro schopné dosáhnout a při přehazování výkonu může upřednostňovat jádra s uvedenou vyšší frekvencí. To opět mohlo být přínosné u starších generací procesorů, ale dnes to působí problémy, především Ryzenům. AMD proto prostřednictvím CPPC2 nehlásí scheduleru Windows skutečné frekvence, kterých jsou jádra schopná dosahovat, ale hlásí de facto falešné hodnoty (trojciferné údaje), které jsou vygenerovány tak, aby nejvyšší odpovídala prvnímu tzv. preferovanému jádru, druhá nejvyšší aby odpovídala druhému tzv. preferovanému jádru a tak dále. Pouze tímto způsobem totiž může AMD přimět scheduler Windows k tomu, aby v rámci možností využíval primárně jádra v jednom CCX (aby nedocházelo ke ztrátě výkonu v důsledku přesouvání dat mezi jádrem v jednom CCX a segmentem L3 v jiném CCX). To totiž z důvodu přehazování zátěže schedulerem Windows musí mít vyšší prioritu než použití skutečně nejlepšího jádra.
Scheduler Linuxu zátěž nepřehazuje (pokud o to vysloveně není požádán), takže žádné z výše popsaných krkolomností není potřeba provádět a při jednojádrové zátěži lze kontinuálně využívat skutečně nejlepší jádro v procesoru a výkonnostně a/nebo energeticky z toho profitovat.
Co stálo za nižším boostem Ryzenů 3000?
Pokud se nad celou situací trochu zamyslíme, pak vyplývá na povrch jedna věc. Celý tento mechanizmus potřebný pro oblbnutí scheduleru Windows totiž může být jedním z důvodů, které stály za nedosahováním plného jednojádrového boostu procesorů Ryzen 3000. Pokud totiž kvůli hloupému scheduleru Windows nemohlo být v jednojádrové zátěži využíváno primárně jádro, které dosahuje nejvyšší (boostové) frekvence, pak logicky uživatel může pozorovat, že není dosahováno maximálního boostu (protože zátěž běží na jiném než na elektricky nejlepším jádru).
Na jeden z dalších důvodů, proč se problém nižšího boostu objevoval, upozornil tuner 1usmus, který experimentuje s preferovaným využitím jader scheduleru Windows. Zjistil, že některé modely základních desek měly v BIOSu ve výchozím stavu vypnuté funkce C-Global State a AMD Cool & Quiet (a ani nenabízely možnost jejich manuální aktivace). Tyto funkce jsou bezpodmínečně nutné pro fungování CPPC2. Jinými slovy: desky, které je měly vypnuté (až do vydání posledního BIOSu to byla např. MSI Godlike X570, opravu přinesla v170), způsobily, že v systému nefungovalo CPPC2, takže scheduler Windows přehazoval zátěž mezi jádry zcela chaoticky. To znamená, že nebylo (ani částečně) zohledňováno, která jádra mají jaké elektrické vlastnosti, ani ve kterém CCX bloku se nacházejí. Scheduler tak mohl při jednojádrovém boostu klidně zátěž přehazovat mezi dvěma vůbec nejhoršími v procesoru, přičemž každé jádro mohlo být i v jiném CCX nebo dokonce na různých kouscích křemíku. Těžko se pak divit, že frekvence při boostu byla na některých deskách i o >100 MHz níže než by odpovídalo specifikacím procesoru a jeho reálným možnostem.
Závěrem si nelze odpustit jednu poznámku na adresu Microsoftu. Když při jedné z minulých kauz (dá-li se to tak říct) kolem neefektivního nakládání scheduleru Windows s procesory AMD došlo vyřčení nelichotivé narážky ze strany AMD na adresu Microsoftu, bránil se Microsoft tvrzením, že AMD mu neposkytla s dostatečným předstihem vzorky procesorů, aby jim mohla scheduler přizpůsobit. Když nyní vychází najevo, jak scheduler Windows ve skutečnosti funguje a že nedochází k žádným reálným úpravám pro nové procesorové architektury, ale naopak že je AMD nucena zastaralý scheduler oblbovat hlášením falešných údajů o procesoru, aby jej přiměla alespoň k částečně efektivnějšímu fungování, vypovídá to leccos o tom, co pravdy bylo na tehdejší mediální reakci Microsoftu.























