
Výpočetní APU Instinct MI300A dosahuje až 4× vyššího výkonu oproti akcelerátorům

Zdroj: AMD
Platforma arXiv Cornellovy univerzity zveřejnila publikaci, podle které je díky sdílené paměti a unifikovanému adresnímu prostoru na Instinct MI300A možné dosáhnout násobků výkonu oproti odděleným řešením…
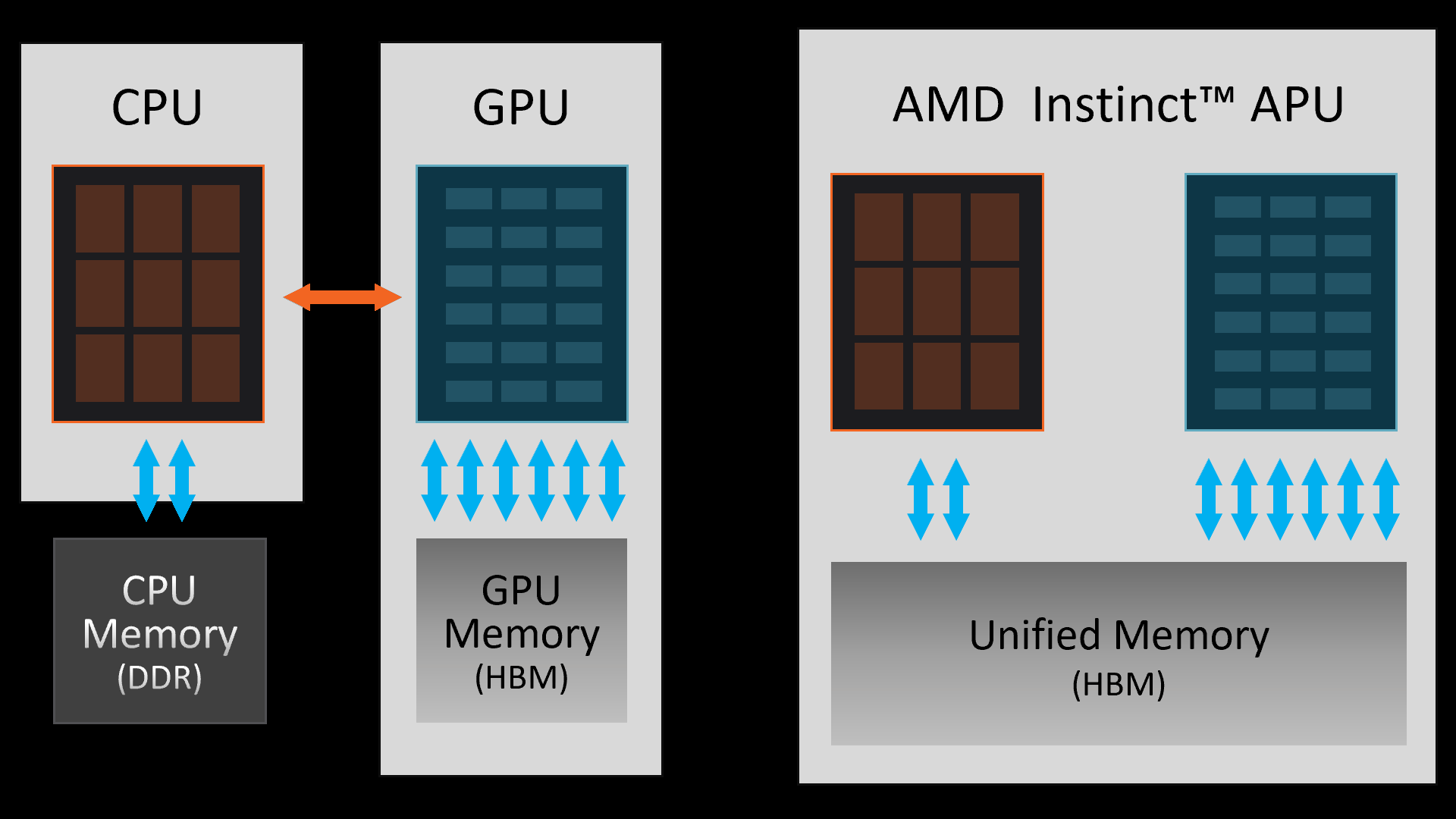
Existují zátěže, které jsou na současném hardwaru limitované jeho výpočetním výkonem. Stejně tak ale existují zátěže, u kterých není na současných akcelerátorech limit na straně výpočetního výkonu, ale datových přenosů. V situaci, kde jsou procesor a akcelerátor oddělené a každý má vlastní paměť, může dojít k situaci, kdy přesuny dat mezi pamětí procesoru a pamětí akcelerátoru vyžadují víc času než samotné výpočty.
Zdroj: DIIT
Právě Instinct MI300A od AMD je prvním výkonným řešením, které překonává klasický koncept CPU s vlastní pamětí a GPU s vlastní pamětí, která jsou vzájemně propojena poměrně pomalým rozhraním PCIe. S MI300A je paměť jednotná, sdílená a CPU i GPU část k ní mají rovnocenný přístup díky unifikovanému adresnímu prostoru. Pokud tedy má GPU pracovat s daty, nemusí docházet k jejich přesunu z jedné paměti do druhé (a pak případně výsledku zpět), ale vše se odehrává na jedné úrovni.

Zdroj: DIIT
V případě úloh, které jsou limitované právě datovými přesuny, je výkonnostní posun MI300A obrovský a může dosahovat až čtyřnásobku výkonu klasického řešení na bázi procesor / akcelerátor.

Zdroj: DIIT
Další graf ukazuje, kolik z času na zpracování úlohy jednotlivá hardwarová řešení spotřebují na samotné výpočty (tmavě) a kolik na datové přesuny (světle). Tento poměr zároveň vysvětluje, proč u tohoto typu úloh má na celkový výkon akcelerátorů navyšování výpočetního výkonu už jen minimální vliv.
Instinct MI300A je řešením, které vzešlo z původního projektu Exascale Heterogeneous Processor (EHP) alias Exascale APU, o kterém se mluvilo (již) v roce 2017. Retrospektivně je zajímavé, jak se AMD musela vypořádat se změnami ve vývoji technologií. Například původní předpoklad byl, že dojde k použití dvou čtyřjádrových procesorových čipletů, tedy celkem 8 jader na APU. Těch je nakonec 24 na APU (tři čiplety po osmi).

Zdroj: DIIT
Na druhé straně vývoj paměti HBM šel pomaleji, než se původně očekávalo. Což je důsledkem skutečnosti, že se výrobci paměti rozhodli udělat z tohoto řešení high-end, který se zaplatí jen na nejvýkonnějších akcelerátorech (namísto původně zamýšleného široce uplatnitelného produktu). Namísto původně zvažovaných HBM4, které měly být navrstvené na nízce taktovaných grafických čipletech (aby HBM neupekly) muselo dojít na HBM3, které nakonec byly umístěny klasicky „vedle“. Tím padla nutnost držet grafické čiplety na nízkých taktech (~1 GHz) a AMD si mohla dovolit takty lehce přes 2 GHz.
| Instinct MI100 | Instinct MI210 | Instinct MI250X | Instinct MI300A | Instinct MI300X | |
|---|---|---|---|---|---|
| označení | Arcturus | Aldebaran | Rigel | ||
| architektura | CDNA | CDNA 2 | CDNA 3 | ||
| CPU | 24× Zen 4 | ||||
| formát | PCIe | PCIe | OAM | socket SH5 | OAM |
| CU/SM | 120 | 104 (128) | 220 (256) | 228 | 304 |
| FP32 jader | 7680 | 6656 (8192) | 14080 (16384) | 14592 | 19456 |
| FP64 jader | - | - | - | - | - |
| INT32 jader | - | - | - | - | - |
| Tens. Cores | 440? | 416 | 880 | ? | ? |
| takt (max.) | 1502 MHz | 1700 MHz | 2100 MHz | ||
| ↓↓↓ T(FL)OPS ↓↓↓ | |||||
| FP16 | 184,6 | 181 | 383 | 980,6 | 1300 |
| BF16 | 92,3 | 181 | 383 | 980,6 | 1300 |
| FP32 | 23,5 | 45,3 22,6 | 95,7 47,9 | 122,6 | 163,4 |
| FP64 | 11,5 | 22,6 | 47,9 | 61,3 | 81,7 |
| INT4 | 184,6 | 181 | 383 | ? | ? |
| INT8 | 184,6 | 181 | 383 | 1960 | 2600 |
| INT16 | ? | ? | ? | ? | ? |
| INT32 | ? | ? | ? | ? | ? |
| FP8 tensor | 3922,4* 1961,2 | 5229,8* 2614,9 | |||
| FP16 tensor | 184,6 | 181 | 383 | 1961,2* 980,6 | 2614,9* 1307,5 |
| BF16 tensor | 92,3 | 181 | 383 | 1961,2* 980,6 | 2614,9* 1307,5 |
| FP32 tensor | 46,1 | 45,3 | 95,7 | 122,6 | 163,4 |
| TF32 tensor | 980,6* 490,3 | 1307,4* 653,7 | |||
| FP64 tensor | 45,3 | 95,7 | 122,6 | 163,4 | |
| INT4 tensor | |||||
| INT8 tensor | 184,6 | 181 | 383 | 3922,4* 1961,2 | 5229,8* 2614,9 |
| ↑↑↑ T(FL)OPS ↑↑↑ | |||||
| TMU | 480? | - | - | - | |
| cache | ? | ? | 16 MB | 256 MB Infinity Cache | |
| sběrnice | 4096bit | 4096bit | 8192bit | 8192bit | |
| kapacita paměti | 32 GB | 64 GB | 128 GB | 128 GB | 192 GB |
| HBM | 2,4 GHz | 3,2 GHz | 3,2 GHz | HBM3 >5 GHz | |
| paměť. propustn. | 1229 GB/s | 1639 GB/s | 3277 GB/s | 5,3 TB/s | |
| TDP | 300 W | 300 W | 500W 560W | 550-760W | 750W |
| transistorů | 50 mld. 25,6 mld. | 29,1 mld. | 58,2 mld. | 146 mld. | 153 mld. |
| plocha GPU | 750 mm² | 362 mm² | 724 mm² | 660 mm²? | |
| proces | 7 nm | 6nm | 6nm | 5nm+6nm | |
| datum | 2020 | 2022 | 2021 | 2023 | 2023 |
Navzdory tomu byla překonána původně cílená hladina energetická efektivity. Namísto cílených 50 GFLOPS na watt dosahuje Instinct MI300A 80-111 GFLOPS na watt (obojí univerzální výpočetní výkon v double-precision). Co se podstatně nezměnilo, je počet stream-procesorů, který se původně plánoval na 16 384 a nakonec dosahuje hodnoty 14 592.
O čem se v roce 2017 ovšem nemluvilo vůbec a co nakonec MI300A zvládá velmi obstojně, je AI akcelerace. Pokud jde o AI výpočty v double-precision, je efektivita oproti původnímu plánu ještě 2× vyšší než hodnoty uvedené v předchozím odstavci.
Zdroje:























