
Genoa (Zen 4) má 3× rychlejší L3 cache než Milan (Zen 3)

První uniklý test paměťového subsystému Epycu Genoa (Zen 4) ukazuje obrovský posun v datové propustnosti cache. Propustnost L3 cache i RAM stoupla na ~3,3násobek, u L1 a L2 cache na dvojnásobek…
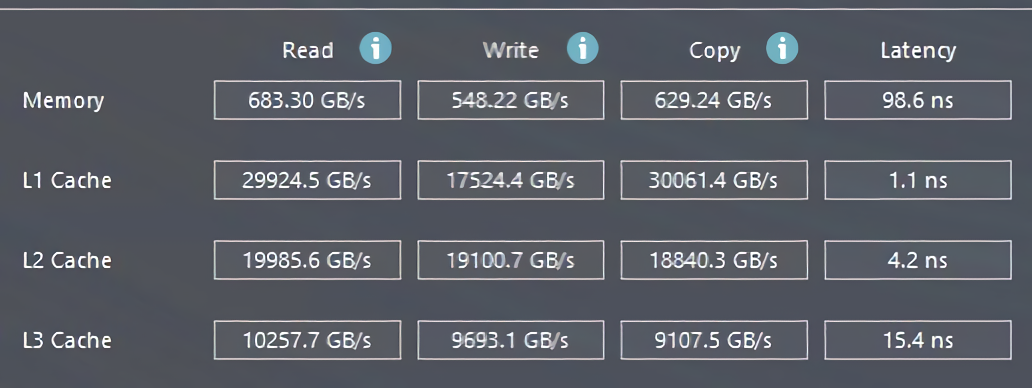
S přelomem léta a podzimu vydá AMD architekturu Zen 4 v podobě desktopových procesorů Ryzen 7xxx (Raphael). Ve čtvrtém kvartálu pak bude následovat jejich profesionální verze v podobě procesorů Epyc xxx4 (Genoa). Právě vzorek Epycu Genoa byl otestován v AIDA64 a výsledky cache a RAM vidíte níže:
Pro lepší představu jsem výsledky překlopil do grafu a doplnil o hodnoty pro nadcházející Xeony Sapphire Rapids, stávající Xeony Ice Lake a současný top AMD, Epyc Milan-X s V-cache. Pro úplnost je potřeba podotknout, že o podobné grafy se pokusila redakce webu WCCFTech, ale pomíchala hodnoty latencí a s hodnotami propustnostmi, takže část grafů vychází nesmyslně.
Datová propustnost - více je lépe
Začněme datovou propustností operační paměti. Zde se projevuje (oproti generaci Milan) podpora DDR5, které jsou významně rychlejší než DDR4 a k tomu navrch dvanáctikanálový řadič:
graph-1
Datová propustnost RAM je 2,4× vyšší oproti Epycům Milan-X, o 32-57 % vyšší oproti chystanému Xeonu Sapphire Rapids, proti němuž bude novinka od AMD stát a 2× vyšší oproti Xeonu Ice Lake, což je stávající nejvýkonnější řada Intelu.
graph-2
Datová propustnost cache je na tom podobně. Oproti Epycům Milan-X stoupla propustnost L1 cache 2,2×, L2 cache 1,9× a L3 cache dokonce 3,3×. Všimněte si, že datová propustnost L3 cache Epycu Genoa je dokonce o desítky procent vyšší než datová propustnost L2 cache Xeonu Sapphire Rapids.
Latence - méně je lépe
Následují latence vyjádřené v nanosekundách, tzn. nižší hodnota = lepší výsledek (kratší odezvy).
graph-3
AMD se navzdory čipletové architektuře (kdy data z jádra musí projít nejprve z jednoho čipletu do druhého a teprve odtud po paměťové sběrnici do modulů - nebo opačně) dokázala snížit latenci pamětí na úroveň monolitů od Intelu.
graph-4
Latence cache jsou také zajímavé. Latence L1 a L3 byly snížené, latence L2 cache mírně stoupla. To souvisí s faktem, že kapacita L2 cache byla u Zen 4 zdvojnásobena a právě zvyšování kapacity je jedním z prvků který má negativní vliv na latence. O 20 % vyšší latence při 2× vyšší kapacitě a ~2× vyšší propustnosti však není špatný výsledek. Latence je totiž stále nižší než u nadcházejících Xeonů Sapphire Rapids. Za pozornost pak stojí ~15ns latence L3 cache, která je v absolutních číslech bližší latencím L2 cache než L3 cache Sapphire Rapids.
Tyto výsledky potvrzují několik měsíců staré zprávy o trochu odlišné filozofii, kterou si AMD nastavila pro vývoj Zen 4 oproti generaci Zen 3. Nezaměřila se tentokrát tolik na IPC samotného x86, ale na řešení limitů architektury - tedy situací, kdy samotné x86 jádro nemůže být plně využito z důvodu nedostatečného zásobování daty. To byl zároveň důvod, proč se u Zen 3 AMD nehnala do vyšších frekvencí (kolem 5GHz už výkon neškáloval úplně dobře s takty) a naopak si zvýšení taktovacích frekvencí nechala na generaci Zen 4, která odstraněním tohoto limitu umožní lepší škálování výkonu s frekvencí.
Zdroje:























