RDNA 3 vypadá na největší architektonickou změnu od GCN

Pokud se potvrdí aktuální zprávy, vypadá to, že RDNA 3 přinese nejen větší architektonické změny než RDNA 2, ale i větší než RDNA. Patrně tak půjde o největší posun od nástupu GCN v roce 2011…
Když v létě 2019 vydala AMD architekturu RDNA a Radeony RX 5000, vypadalo to, že po osmi letech došlo na větší změny, je alespoň na pětiletku vystaráno a nové generace budou přidávat CU / SP (Compute Units / Stream Processors) a přinášet drobná vylepšení, optimalizace pro výkon na watt a podporu nových technologií.
Tuto vcelku očekávatelnou představu nabouralo již vydání Radeonů RX 6000 s architekturou RDNA 2. Přinesly tzv. Infinity Cache, velkou last-level cache, která redukuje přístupy do grafické paměti, což AMD umožňuje osadit úplný high-end 256bit sběrnicí v kombinaci s pamětmi minulé generace (GDDR6) a ve výsledku dosahovat výkonu, pro který konkurence potřebuje 384bit sběrnici a dražší / energeticky náročnější GDDR6X. AMD se tím po dlouhých letech podařilo trochu zaskočit Nvidii, která poprvé na karty řady GeForce x800 použila namísto druhého nejvýkonnějšího GPU (Gx104) nejvýkonnější GPU dané generace (Gx102).
Zdálo se, že AMD s RDNA řešila primárně energetickou efektivitu, s RDNA 2 se rozhodla vyřešit paměťovou propustnost a s RDNA 3 se chystá vyřešit potíže související s velkými monolitickými GPU pomocí rozdělení na čiplety. Aktuální zvěsti ale nastiňují, že takový pohled na RDNA 3 by byl značně zužující.
Poměrně spolehliví leakeři jako Greymon55 a Yuko Yoshida naznačují, že RDNA 3 přinese významné změny na úrovni front-endu i back-endu grafické čipu a krom toho dojde i k celkovému přepracování struktury funkčních bloků grafického jádra. Tato slova většina zdrojů chápala tak, že budou odlišným způsobem uspořádány CU (výpočetní bloky), konkrétně se mluvilo 3 CU (se 32 stream-procesory jako u RDNA 2) na WGP, což však asi není přesné. Leaker Bondrewd totiž naznačil, že RDNA 3 už CU v podstatě nemá. To by znamenalo, že uspořádání stream-procesorů v (do určité míry) samostatných blocích po 64 (GCN) respektive 32 (RDNA) je minulostí. Pokud lze číst mezi řádky, vypadá to, že WGP (Work Group Processor) architektury RDNA 3 bude tvořem osmi SIMD jednotkami o šířce 32 a neznámým množstvím texturovacích jednotek. To by snad mohlo být co do poměru ku stream-procesorům nižší (poloviční?) než u současných architektur.
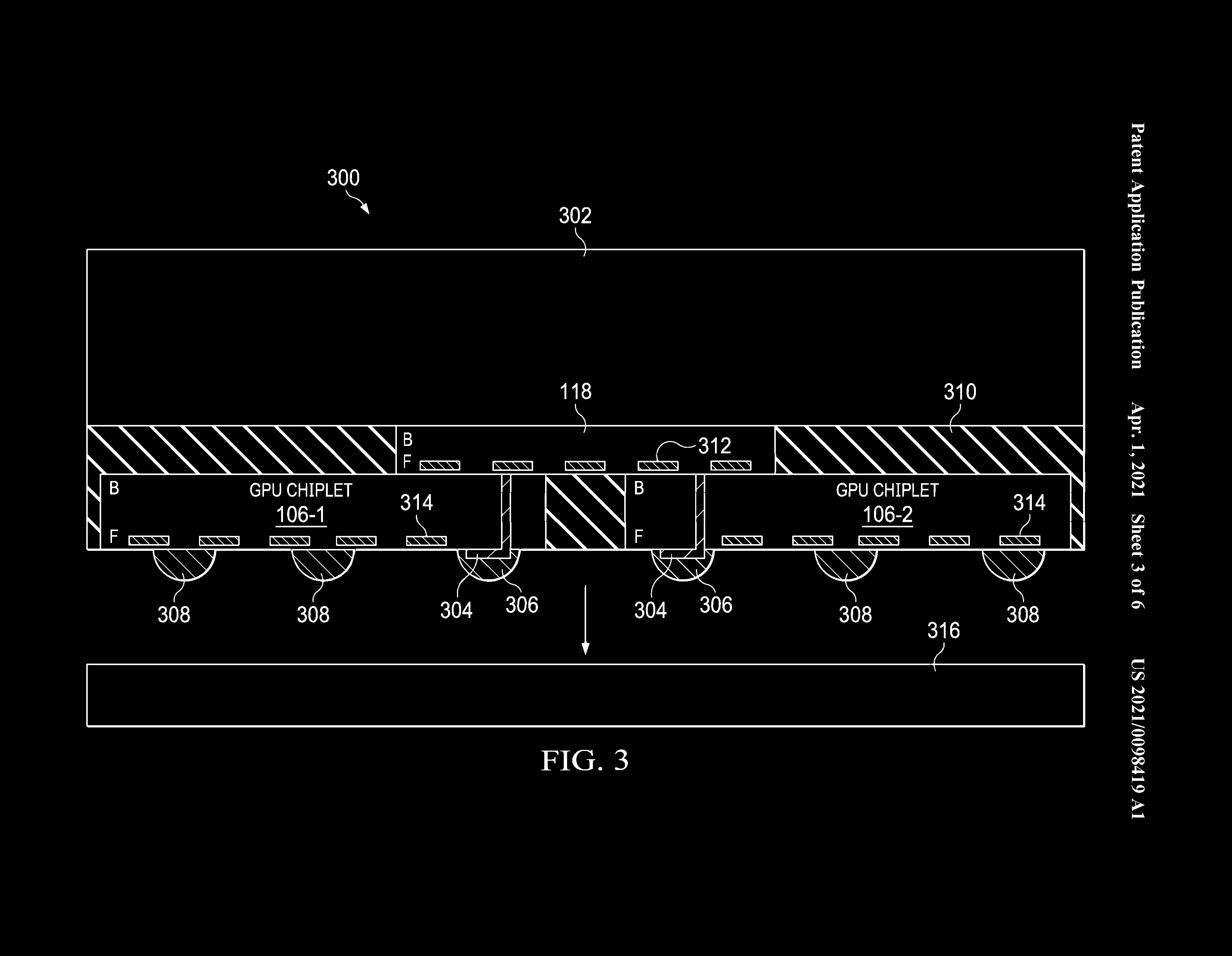
Bez dalších informací nelze s jistotou říct, kam tím AMD míří, ale může jít o snahu o další snížení latencí, případně (navzdory složitějšímu schedulingu) o další zvýšení celkové efektivity (které převáží náklady na tranzistory zajišťující komplexnější scheduling). Dále je možné, že některé z těchto změn budou důsledkem rozdělení GPU na čiplety, takže lze předpokládat, že budou přítomné pouze v čipech Navi 31 a Navi 32, které jsou čipletové, a nikoli v Navi 33 a Navi 34, které jsou monolitické.
AMD s touto generací mění prakticky všechny architektonické aspekty od fyzického rozdělení křemíku na čiplety přes reorganizaci funkčních bloků v čipletech po řízení a rozložení zátěže v rámci čip(let)u. K tomu máme očekávat i významný posun v efektivitě výkon na watt, bez kterého by výkonnostní cíle AMD nebyly možné a nasazení dvou nových výrobních procesů (5nm a 6nm TSMC).

Je-li řeč o výkonnostních cílích, zdá se že taková porce změn není důsledkem ničeho jiného, než proslýchaného cíle zvýšit mezigeneračně výkon high-endu až 2,5-2,7×. Popsané změny do jisté míry usnadňují pochopit, jak by do GPU mohlo být integrováno 15360 stream-procesorů namísto dříve očekávaných 10240 (je tu např. určitá šance, že WGP ponese poloviční počet texturovacích jednotek, než by odpovídalo poměru současných architektur, čímž by došlo k určité úspoře tranzistorů a plochy). Zároveň by přítomnost 15360 stream-procesorů lépe vysvětlovala výkonnostní cíl blízký trojnásobku 5120 stream-procesorů Navi 21, navzdory tomu, že 5nm proces oproti 7nm snižuje spotřebu pouze o 30 % (při stejných taktech), tudíž by asi nebyl prostor pro takové zvýšení taktů, aby s 2× více stream-procesory mohlo být dosahování 2,5× více výkonu. Pokud ovšem má být s 3× více stream-procesory dosahováno 2,5-2,7× více výkonu, je tu prostor i pro snížení taktovacích frekvencí, které by umožnilo dosažení ambiciózního cíle i s 5nm procesem, který spotřebě sám o sobě příliš nepomáhá.
Možná ještě kurióznější jsou zvěsti o tom, že AMD tohoto cíle plánuje dosáhnout stále s 256bit sběrnicí, přičemž požadavky na přístup k pamětem bude redukován 512MB Infinity Cache (tedy 4× vyšší kapacitou oproti RDNA 2 / Navi 21 / Radeonům RX 6800/RX 6900). U této zprávy však zatím chybí potvrzení z více nezávislých zdrojů.