
RECENZE: Framework Laptop 16, je libo modulární klávesnici a vyměnitelné GPU?

Zdroj: Karel Svoboda - diit.cz
Společnost Framework nabízí kromě malého 13" notebooku i větší a ještě více modulární model. A na ten se dnes podíváme.
Kapitoly článků
3. Paměťový subsystém - propustnost a latence RAM - Microbenchmark
Tato kapitola je aktuálně novinkou, chtěl jsem totiž nějak lépe testovat paměťovou propustnost a také latence pamětí. To se všeobecně netestuje zrovna snadno a test v AIDA64 je takový velmi rychlý, nicméně na rychlé ověření, že jsou paměti nastavené správně postačí. Využívám tak programu Microbenchmark v GUI variantě, která kreslí i veselé grafy. Program umí testovat čtení i zápis do paměti mnoha způsoby, nechybí i testování latencí RAM.
Kapitola vznikla tak trochu na poslední chvíli někdy ve tři ráno v den vydání recenze Ryzenu 7 9800X3D(tedy její sepsání a zpracování dat pro grafy, ne samotné testování). Mám v plánu vybalit ještě některé Intel Core Ultra procesory, které jsem zatím nevrátil a otestovat je, zatím jsou v testu platformy, které bych označil jako "co dům dal". Program podporuje i testování za pomoci AVX-512 instrukcí, ale zatím jsem zvládl jen několik málo procesorů.
Nejprve se podíváme na rychlost čtení paměti, pokud se použije pouze jedno CPU jádro/vlákno. Do srovnávacího grafu uvádím hodnotu u "nejvzdálenějšího" množství paměti, čímž se eliminuje vysoká propustnost L1/L2/L3 cache. Na screenshotu ale můžete vidět i jednotlivé kroky, jak nám propustnost postupně klesá.
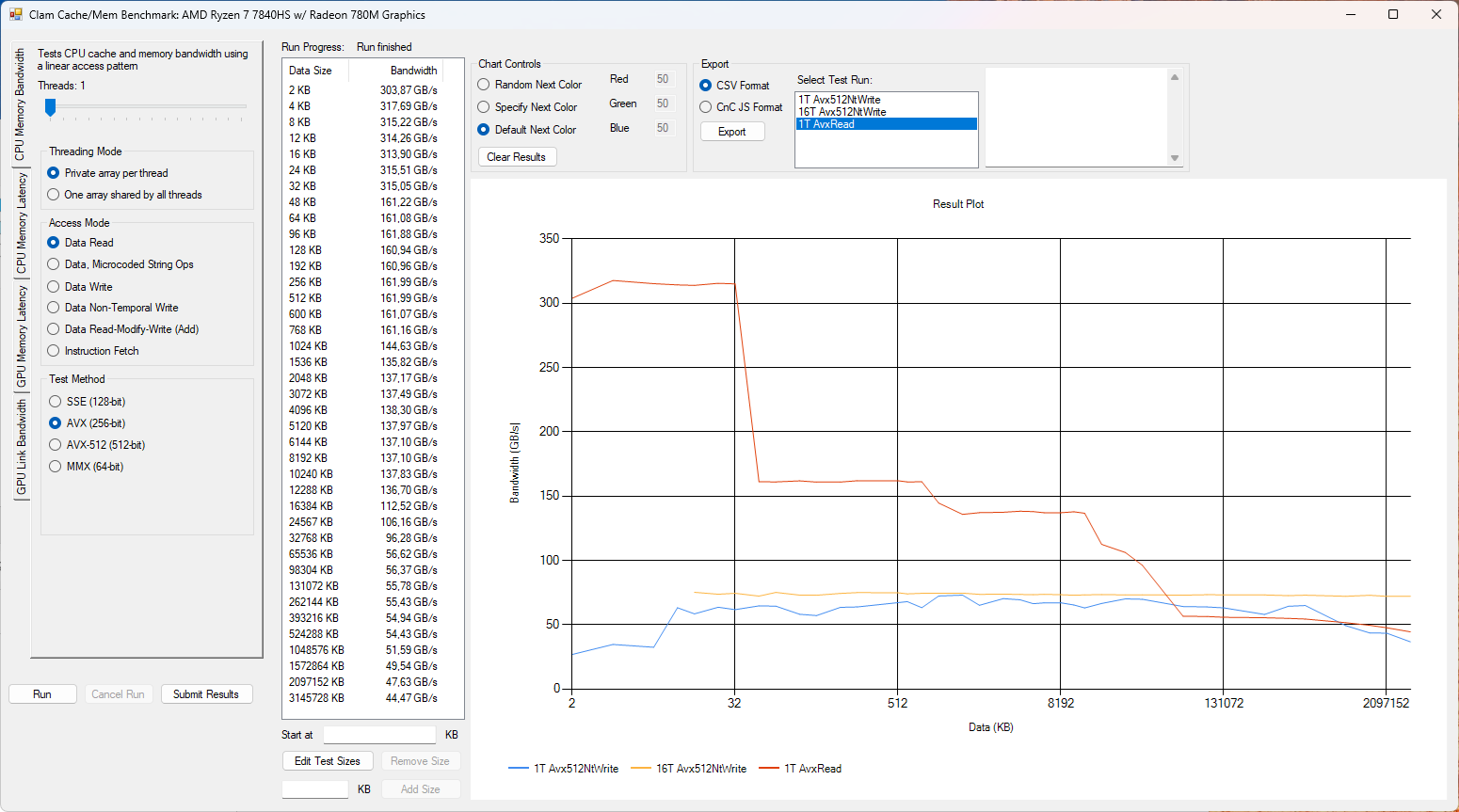
Franework Laptop 16 si vede překvapivě dobře a při čtení jedním jádrem je aktuálně nejrychlejší.
graph-1
Situace se mění při využití všech dostupných CPU vláken, u vše počítačů jsem vždy nastavil jejich maximální počet dostupných vláken, zde by tedy mělo dojít na nějaké škálování a potenciálně vyšší rychlosti. Ale také dojde na snížení propustnosti RAM pro jednotlivá jádra, což je poměrně zajímavé.
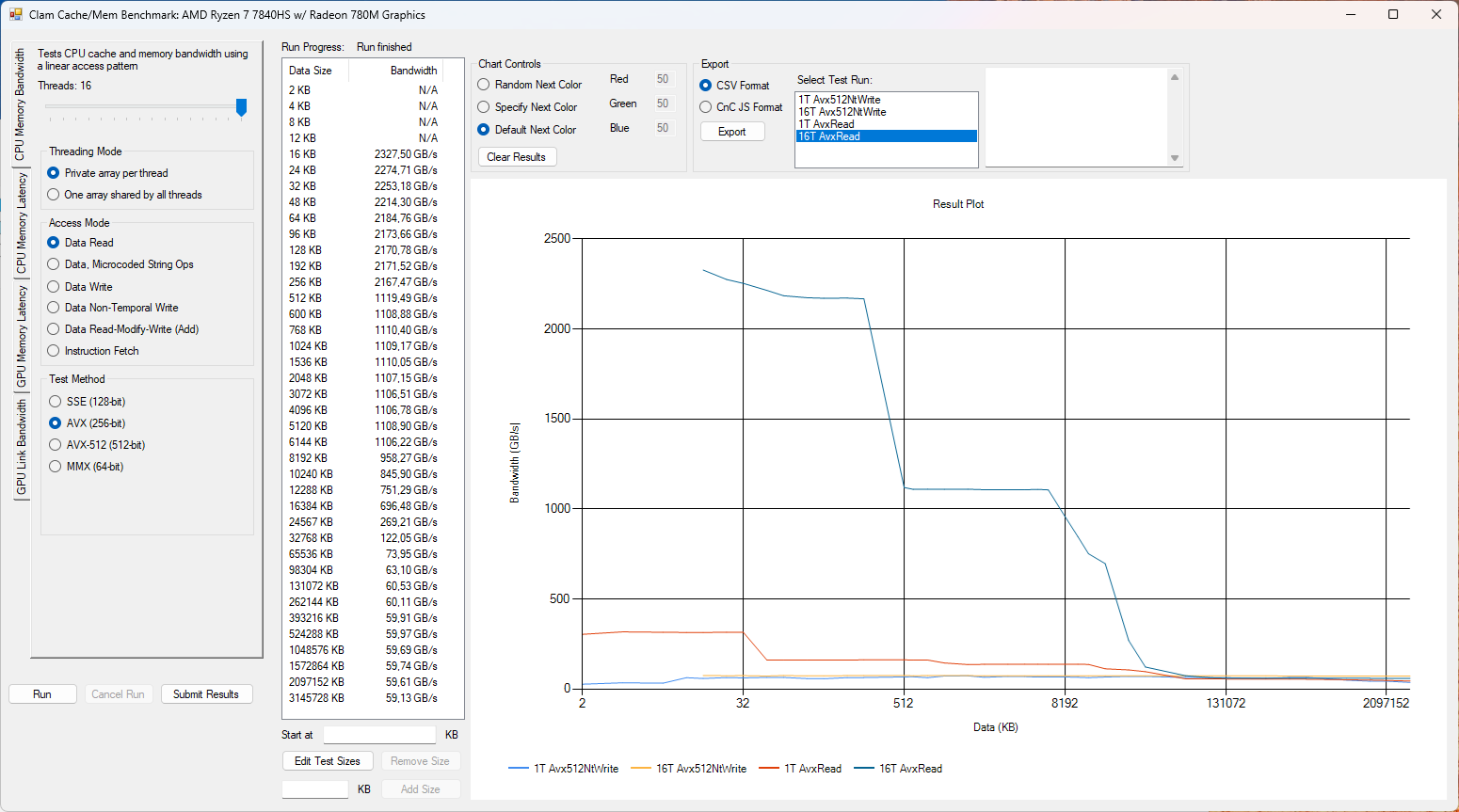
Při použití všech jader se dostáváme na rychlost čtení spíše nižší, což dává smysl vzhledem k pomalejším 5600 MT/s pamětem.
graph-2
Dále zkouším testy propustnosti s AVX-512 instrukční sadou.
Framework Laptop 16 je zde logicky pomalejší, než modernější Strix Halo.
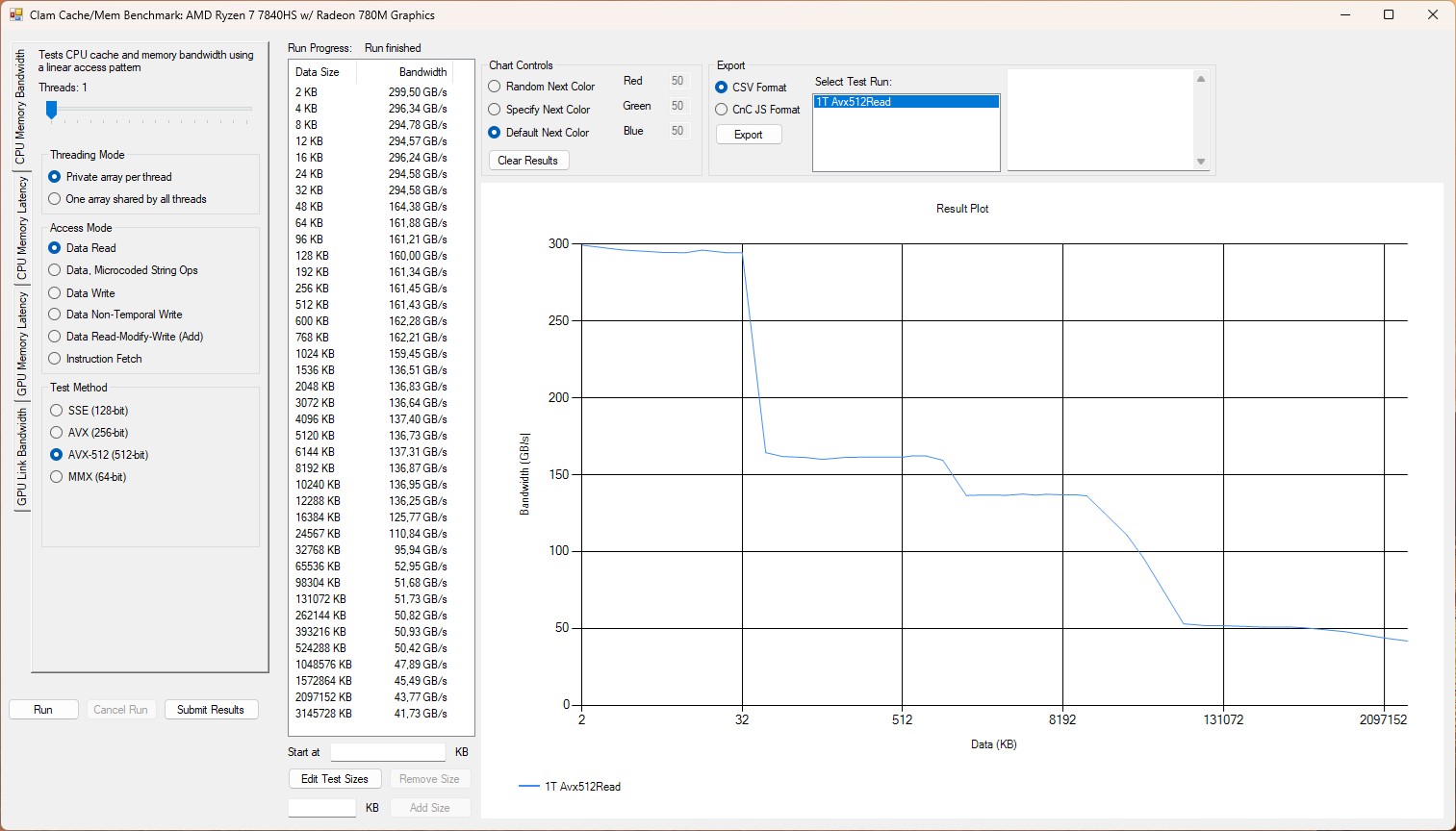
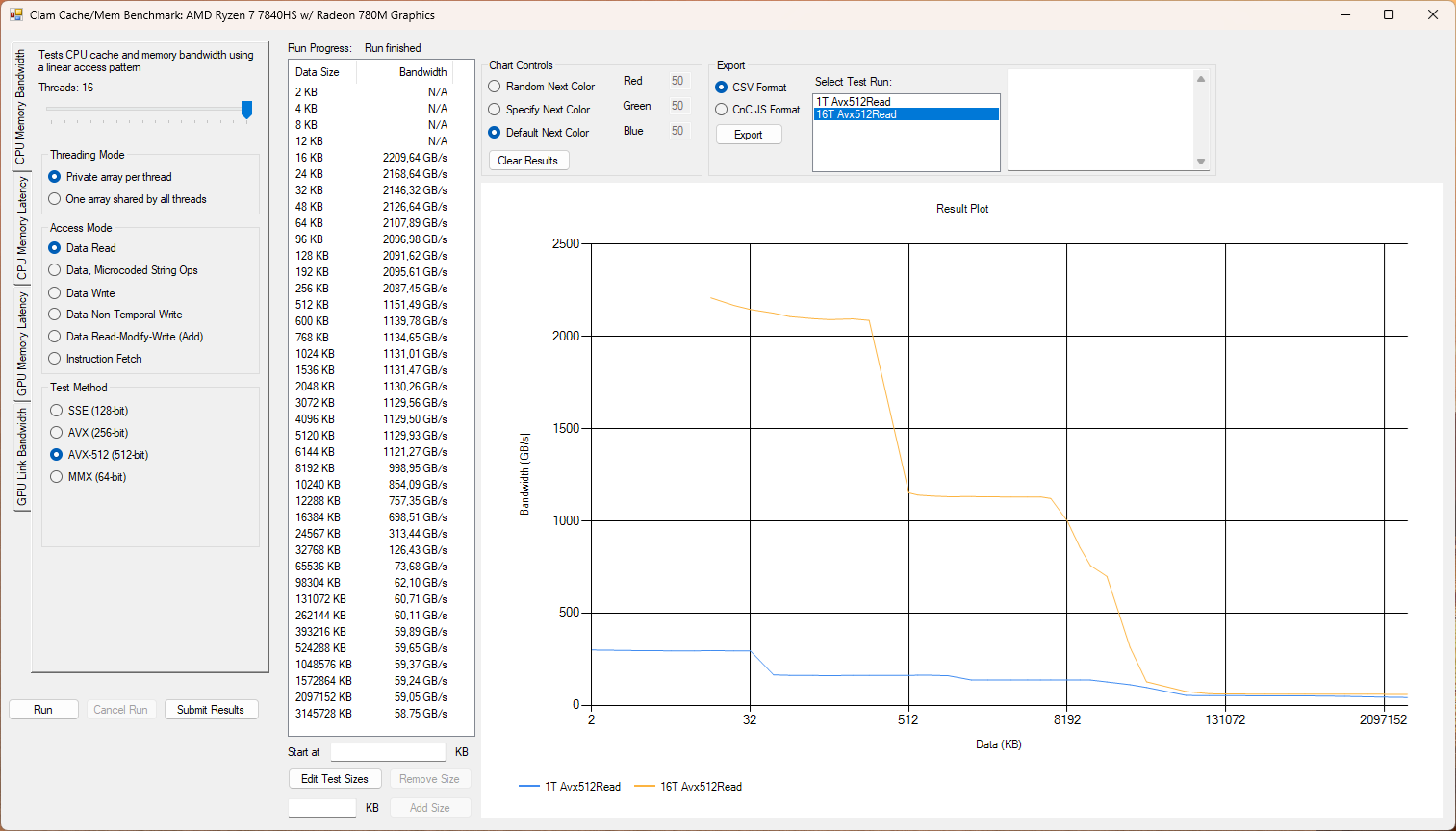
graph-3
graph-4
Důležitá je samozřejmě i rychlost zápisu do paměti. Opět zkouším nejprve jedno CPU jádro/vlákno s AVX instrukcemi a očekávám nižší propustnost oproti všem dostupným vláknům.
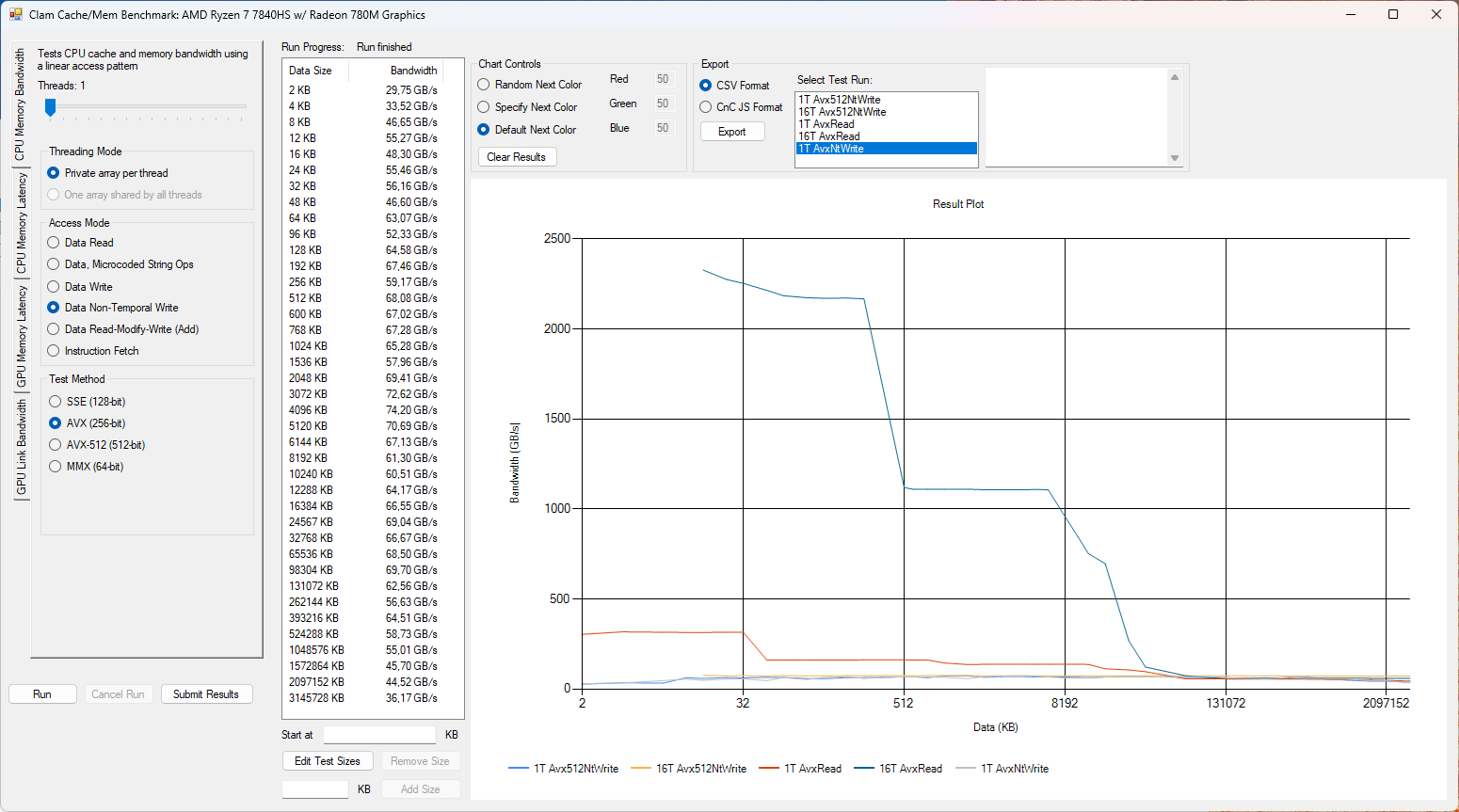
Zde i s jedním vláknem kraluje Strix Halo, Franework Laptop 16 je až na čtvrtém místě.
graph-5
Při využití všech dostupných CPU vláken si Strix Halo maže ostatní procesory na chleba. Franework Laptop 16 je zde až na třetím místě.
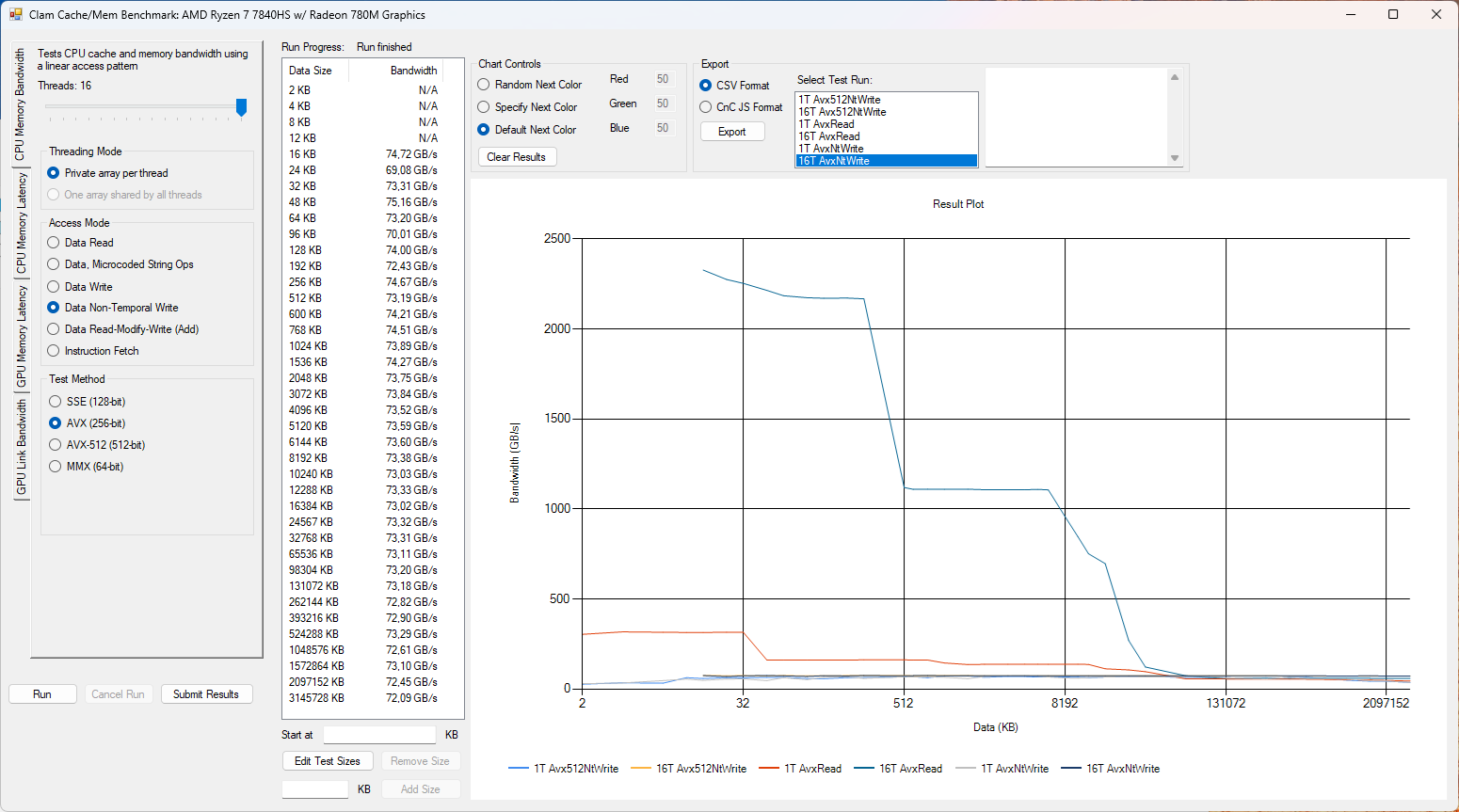
graph-6
Při použití AVX-512 instrukcí je v zápisu Strix Halo zatím nejrychlejší.
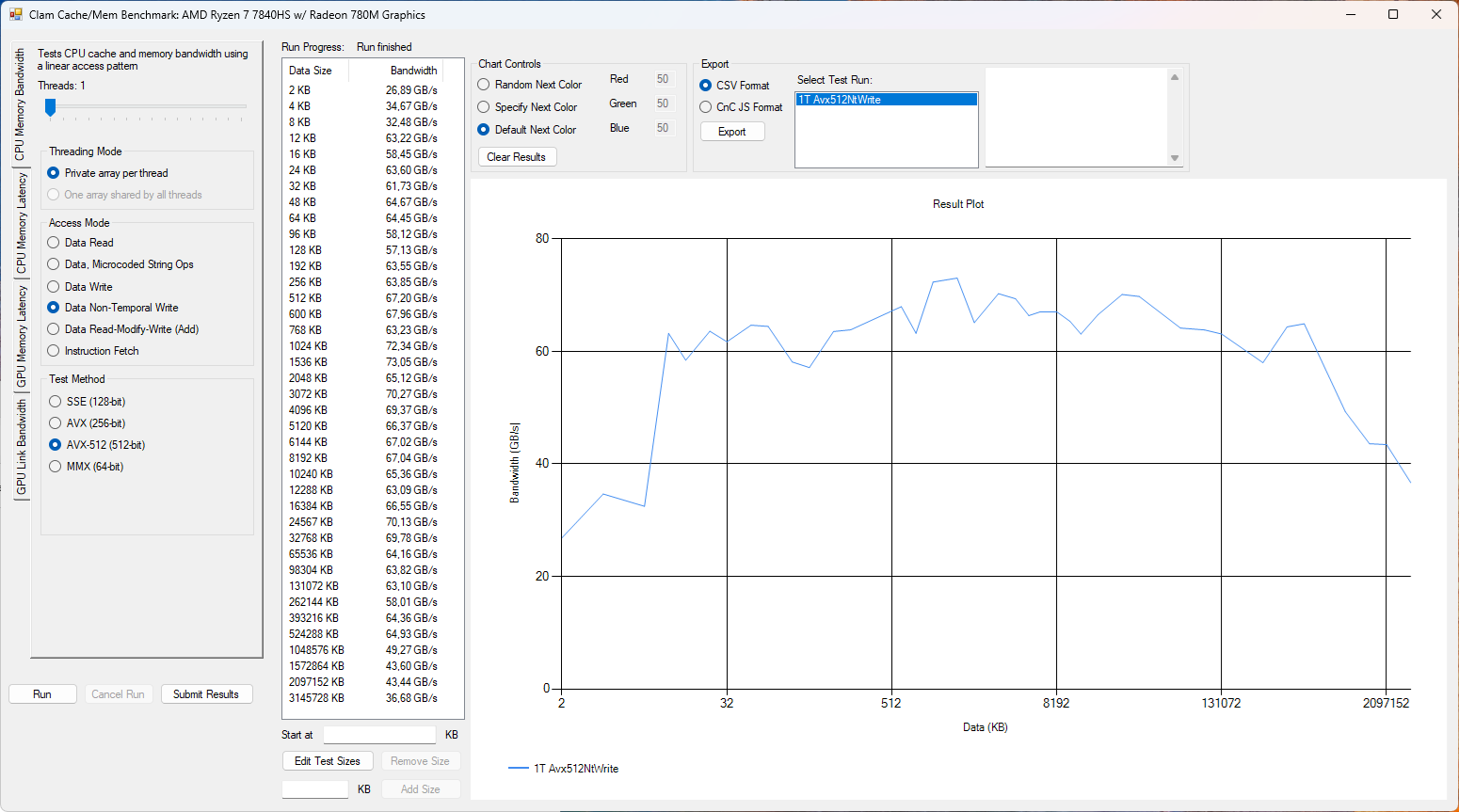
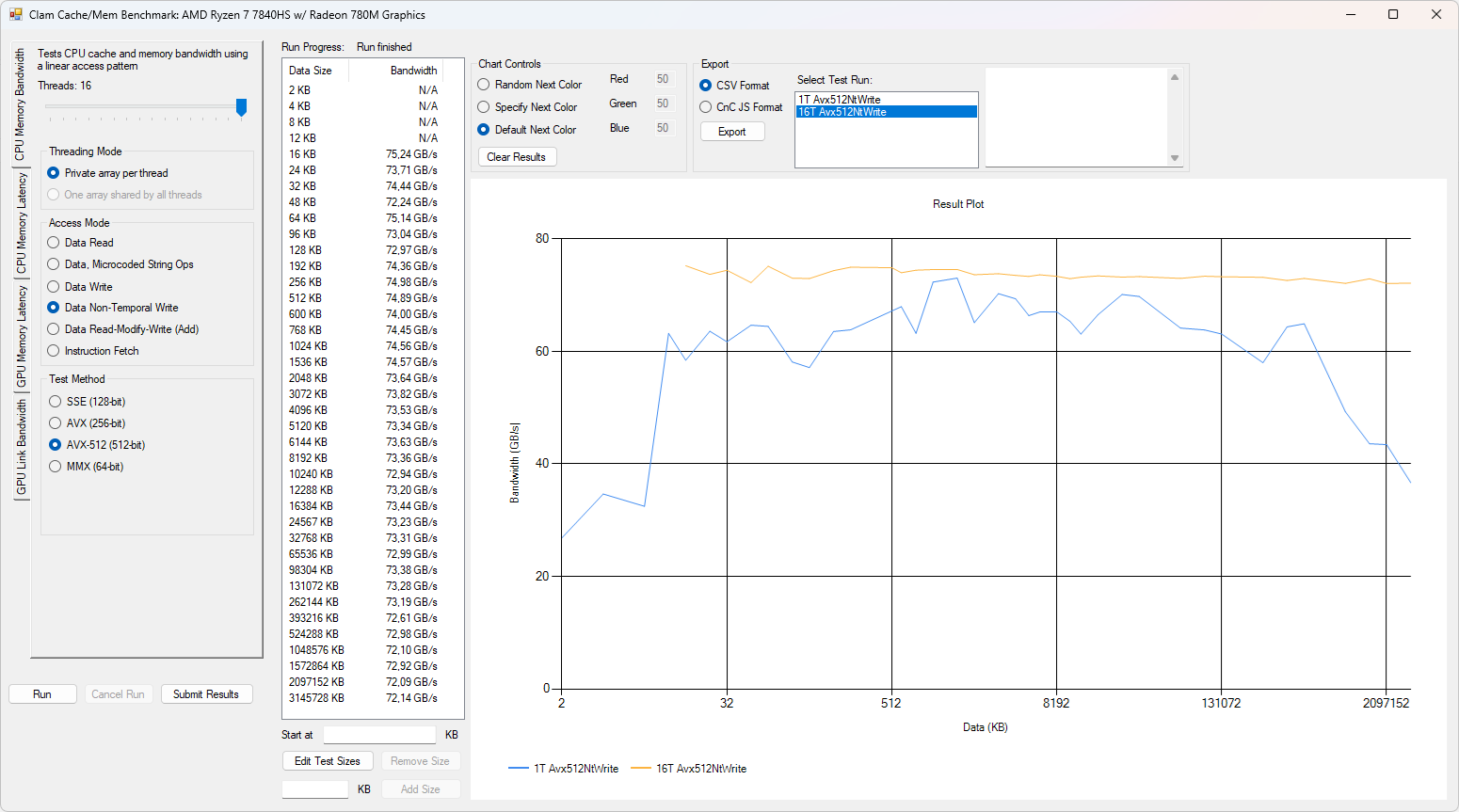
graph-7
graph-8
Dále jsem provedl několik testů latence paměti, program podporuje jednoduché adresování a indexované adresování. Pro zajímavost uvádím do grafů dvě hodnoty a to sice latence při 64MB využití a posléze při 1GB využití. Procesory co mají více než 64MB cache zde budou mít výhodu.
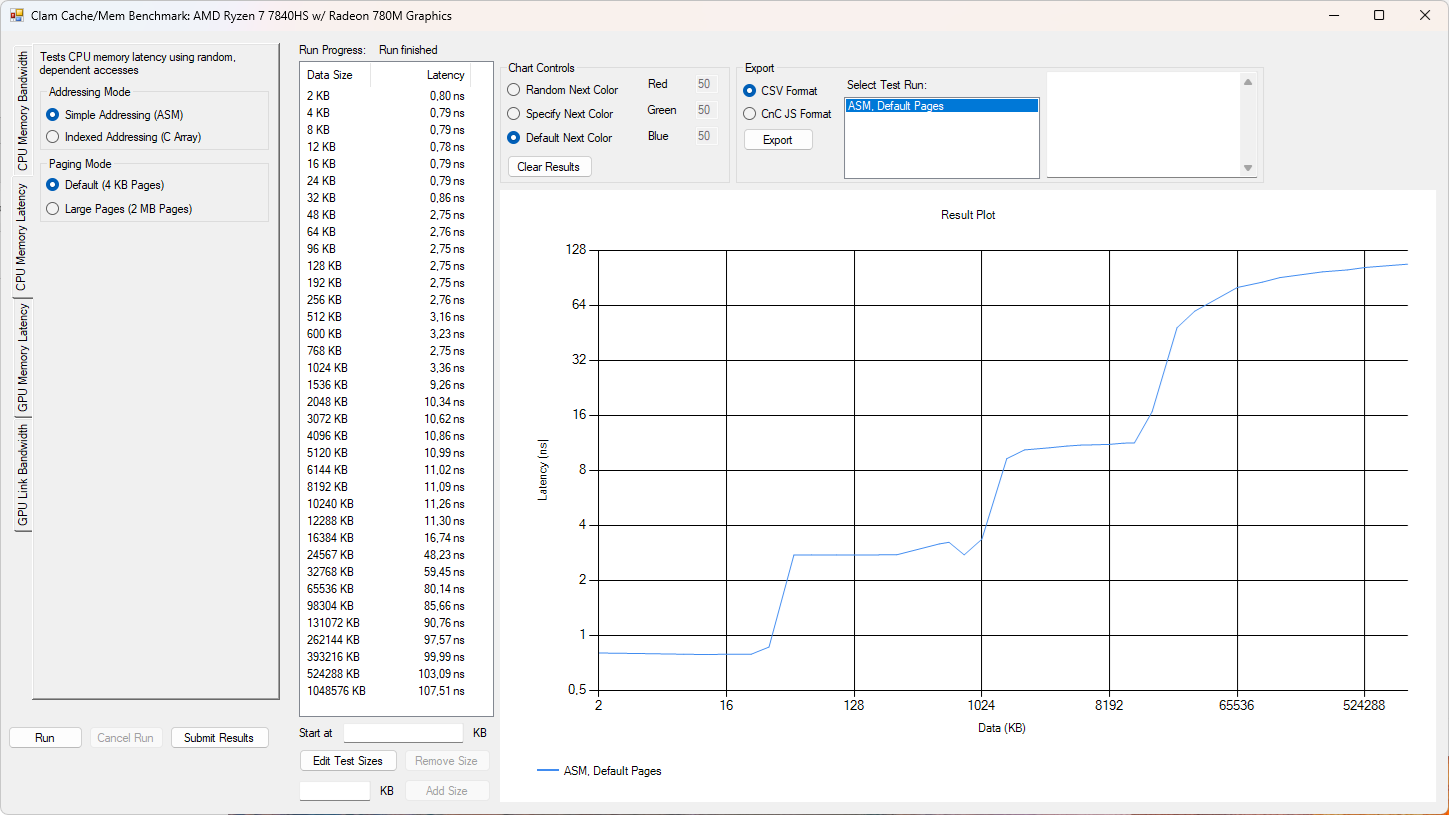
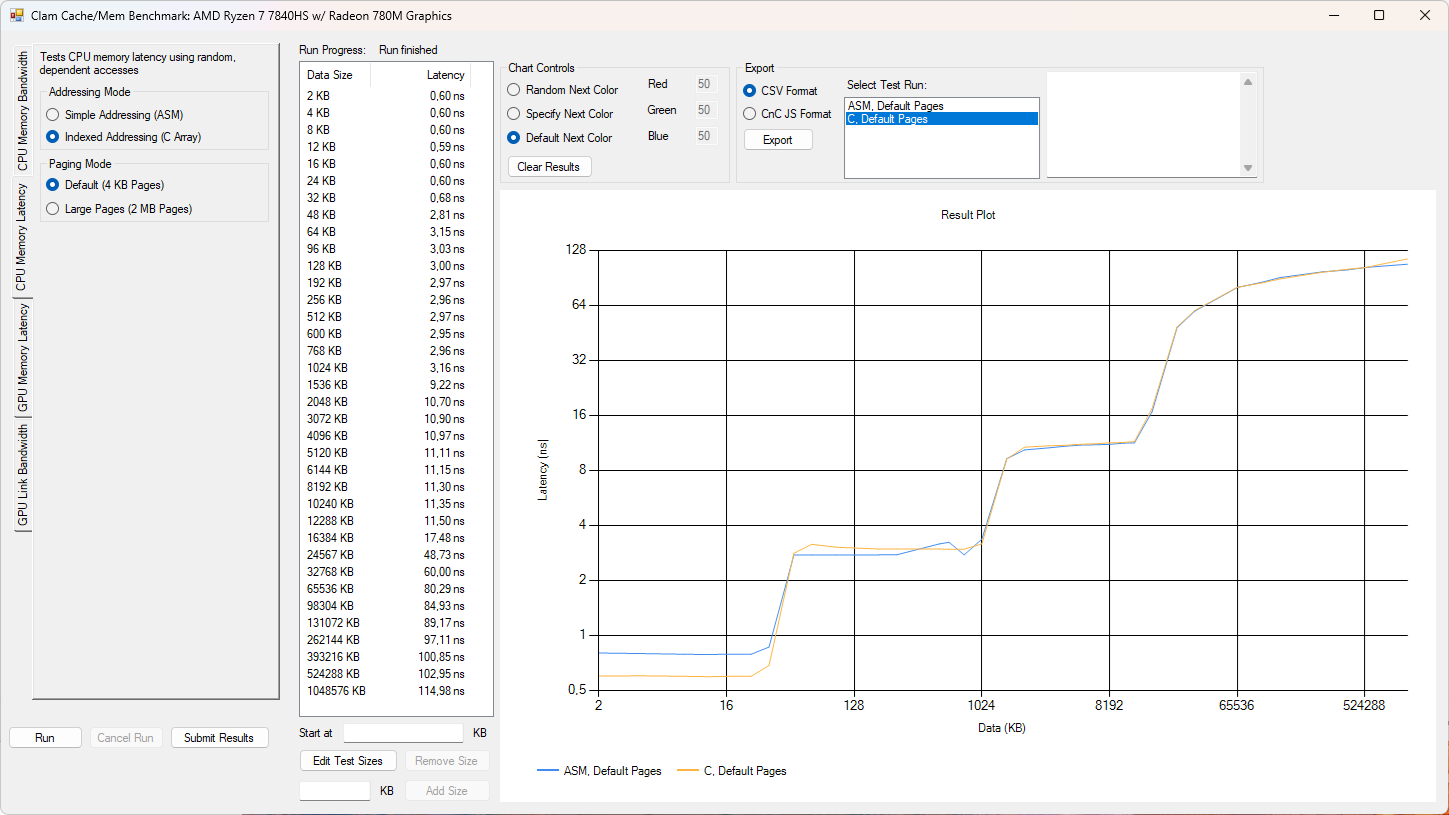
Při jednoduchém adresování můžeme vidět, že Franework Laptop 16 dosahuje relativně nízkých latencí díky XMP profilu, je zde celkem slušný skok proti Frameworku 13.
graph-9
Jakmile se zvětší množství dat, situace se mění, Framework 16 je nadále na třetím místě a vítězí zde staré Intel procesory.
graph-10
Indexované adresování trochu pozměňuje výsledky některých procesorů, Framework Laptop 16 je nadále třetí nejlepší.
graph-11
Při použití více paměti jsou latence samozřejmě značně vyšší, Framework Laptop 16 je nadále na třetím místě.
graph-12
předchozí kapitola
následující kapitola
Kapitoly článků
3. Paměťový subsystém - propustnost a latence RAM - Microbenchmark

Karel "Karáš Svorka" Svoboda (Google+)
Pesíci dělají chro. Je potřeba vysumýšovat chrochták.


















