Rozhraní na Zen 3 pro V-cache má kolem 23 tisíc kontaktů

Zdroj: AMD
Na konec letošního roku připravuje AMD vydání Zen 3 obohaceného o V-cache, navrstvenou paměť rozšiřující L3 cache o kapacitu 64 MB. V-cache disponuje velmi širokou sběrnicí…
Kráce po vydání Zen 3, když se objevily první snímky jádra, si první pozorné osoby všimly, že na povrchu čipletu je umístěno tzv. TSV (=through silicon vias, cesty či spoje skrze křemík). Tehdy ovšem nikdo nevěděl, k čemu bude sloužit. Mohlo jít o experimentální prvek, na kterém by si AMD mohla testovat nasazení případných budoucích technologií chystaných pro další generace procesorů. Mohlo sloužit k navrstvení křemíku s dalšími procesorovými jádry. Nikdo však v té době veřejně neprezentoval nápad, že by navrstveným prvkem mohla být cache (pokud někdo náhodou takový nápad veřejně prezentoval, pak nejspíš málo důrazně, protože to zůstalo bez povšimnutí).
|
Nyní se na rozhraní zaměřil Yuzo Fukuzaki z webu TechInsights, který spočítal, že spoje mají rozteč asi 17 μm a celé rozhraní jich nese kolem 23 tisíc. Samozřejmě to neznamená, že jde o 23000bit sběrnici. Část spojů bude řešit napájení, část řízení. Třeba u GDDR6 čipu, který má šířku datové sběrnice 32 bitů, nese celé BGA rozhraní 180 spojů. Poměr spojů a šířky sběrnice v jejich případě odpovídá zhruba 5,6:1. V případě TSV patrně bude výrazně nižší, neboť cache bude podstatně méně energeticky náročná (neřeší se žádné dlouhé spoje vedoucí skrze PCB a poměr šířky sběrnice k fyzické frekvenci je vyvážen odlišně). I kdybychom však vycházeli z poměru platného pro GDDR6, znamená to, že by čistě datové sběrnice této cache byla ~4096bitová. Může však být podstatně širší.
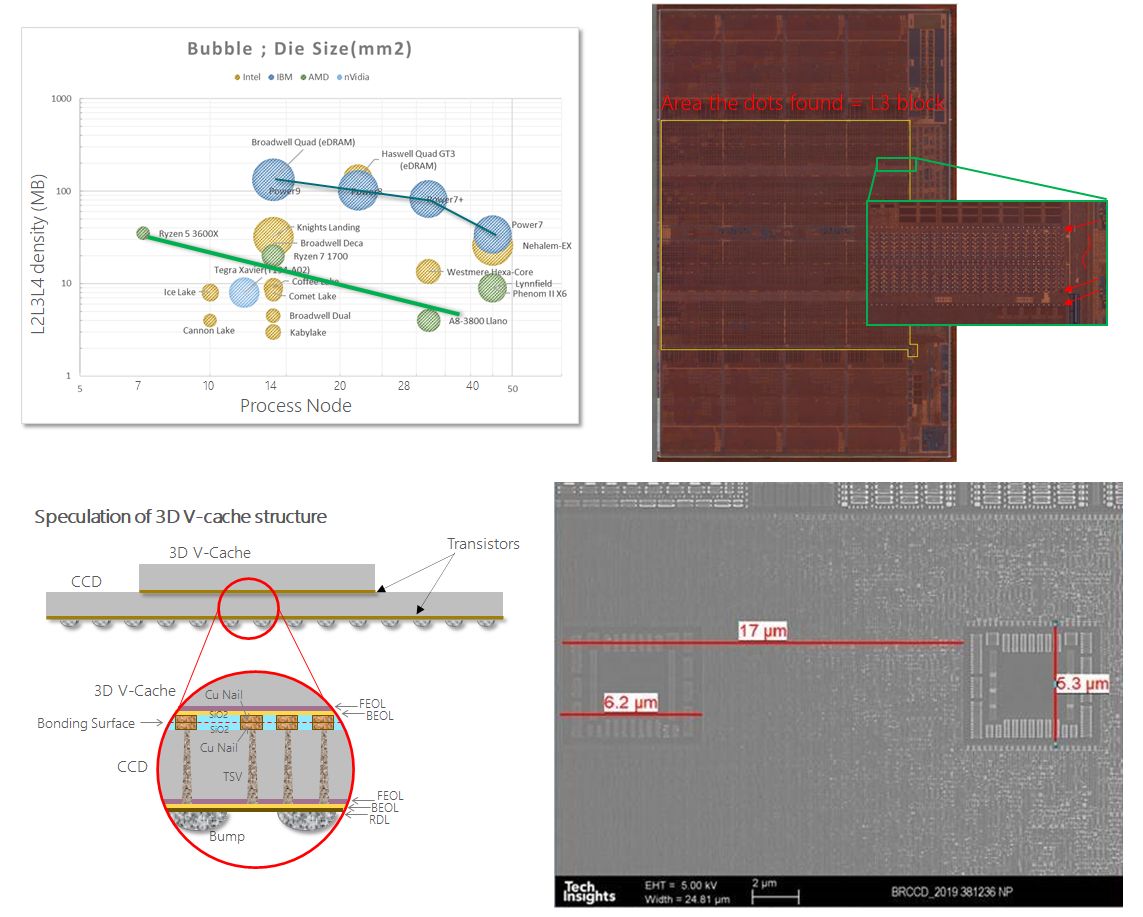
Už v našem předchozím článku jsme přinesli ilustraci znázorňující, v jaké části čipu by měla být V-cache připojena (na snímku jádra v této části jsou dobře vidět dva pásy TSV rozhraní), což schemata Yuzo Fukuzaki potvrzují.
Jak už AMD avizovala dříve, propustnost celé 192MB L3 cache (tzn. dva 32MB oddílů v obou čipletech a dvou 64MB oddílů navrstvených na obou čipletech) má být dohromady přes 2 TB/s. Pro jeden čiplet tedy 1 TB/s. Jeden čiplet má tedy k dispozici datovou propustnost jako celé GPU akcelerátoru Radeon Instinct MI60 / MI100 nesoucí 4096bit sběrnici osazenou čtyřmi štůčky ~2GHz HBM2. Celý šestnáctijádrový Ryzen pak s více než 2 TB/s překonává datovou propustnost sběrnice poslední verze akcelerátoru Nvidia A100 s 5120bit sběrnicí a 3,2GHz HBM2E. Celková datová propustnost L3 cache je tak vyšší než datová propustnost L1 cache.
Lze očekávat, že zvýšení kapacity a datové propustnosti (latence se oproti současné L3 cache nijak podstatně nezmění) přinese pozitivní dopad na herní výkon (samozřejmě v situaci, kdy je herní výkon limitovaný procesorem a nikoli výkonem grafické karty) a některé profesionální aplikace (takže se nasazení V-cache očekává - byť ze strany AMD zatím potvrzeno nebylo - i v serverech). V běžných aplikacích se ale V-cache nejspíš nijak zásadně neprojeví.
Pro AMD znamená její použití poněkud elegantnější půlgenerační řešení než by odpovídalo jen 100-200MHz přetaktování. AMD tím sice zdaleka nevykompenzuje generační náskok konkurenční architektury Alder Lake / Golden Cove, kterou chystá Intel na konec roku. Ta ale nebude v grafech čnít o ~25 % nad top modelem AMD, jak by tomu bylo v případě srovnání se současnými modely Ryzen 5000.
Zdroje: