
Co je SLC a jaký má význam ve světě x86 desktopu

V posledních letech se čím dál častěji setkáváme se zkratkou SLC v kontextu cache. Protože ji časem budeme slýchat zcela běžně, nebude od věci se podívat, kde se SLC vzala a k čemu je nebo není dobrá…
Zkratku SLC můžeme číst ve dvou různých kontextech. Donedávna se objevovala především v souvislosti NAND flash, kde označovala typ Single-Level Cell. Nás však bude zajímat kontext procesorů, především SoC (System on Chip, procesor s integrovaným čipsetem, GPU…), kde SLC označuje tzv. System Level Cache.
Co je vlastně System Level Cache: Dá se říct, že neexistuje zcela jednotná kodifikované definice a názory se mohou v nuancích lišit, ale v zásadě jde o cache, která slouží celému systému (míněno SoC), tedy jak procesorovým, tak grafickým jádrům.
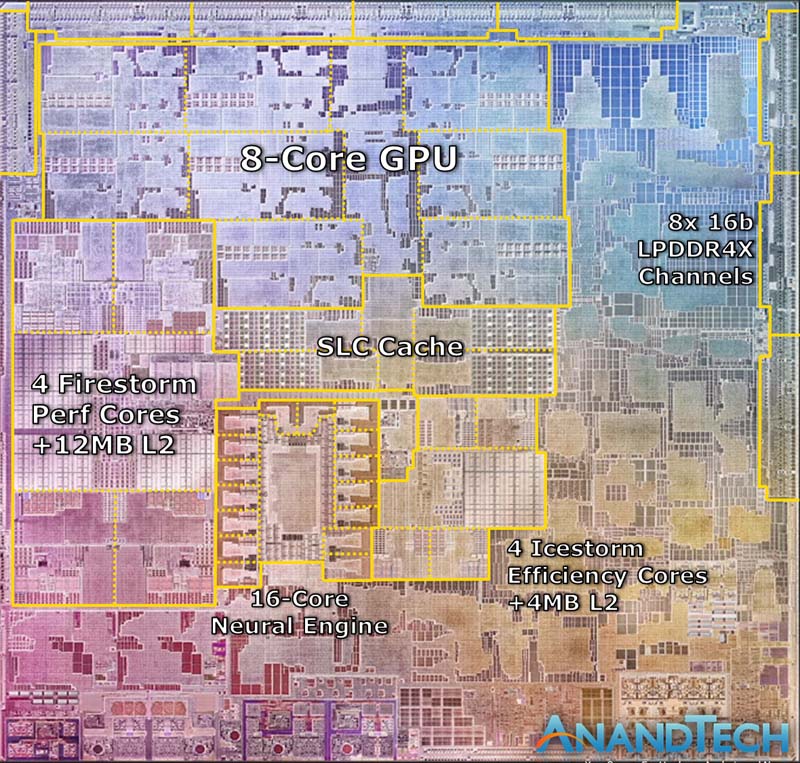
snímek jádra Apple M1: popisky Anandtech
Se zkratkou SLC jsme se začali setkávat především v kontextu SoC společnosti Apple, byť i ten zkratkou začal operovat později, než koncept sdílené cache u svých ARM SoC zavedl. Dá se říct, že ji ve svých prezentacích začal uvádět ve chvíli, kdy se začal projevovat významnější přínos této cache.
Z toho (zcela obecně) vyplývá, že SLC sama o sobě nemusí vždy znamenat strategickou výhodu. Skutečně - jako u většiny případů unifikace - mohou být situace, kdy je výhodné unifikovat a kdy to vhodné není. Příkladem může být hned následující odstavec.
Sandy Bridge, první SLC v x86 desktopu?
Ve světě x86 desktopu jsme se s něčím, co by se retrospektivně dalo označit za SLC, setkali dávno před tím, než se zkratka začala široce používat. Šlo o generaci procesorů Intel Sandy Bridge, která byla veřejně demonstrovaná v roce 2009, architektonicky představená v roce 2010 a vydaná roku 2011. Sandy Bridge oproti svým předchůdcům sloučil x86 procesor a grafické jádro do jednoho kusu křemíku. Intel tehdy hledal cesty k úspoře rozpočtu tranzistorů, čímž se řídily četné architektonické změny. Především ty, které se týkaly paměťového subsystému.
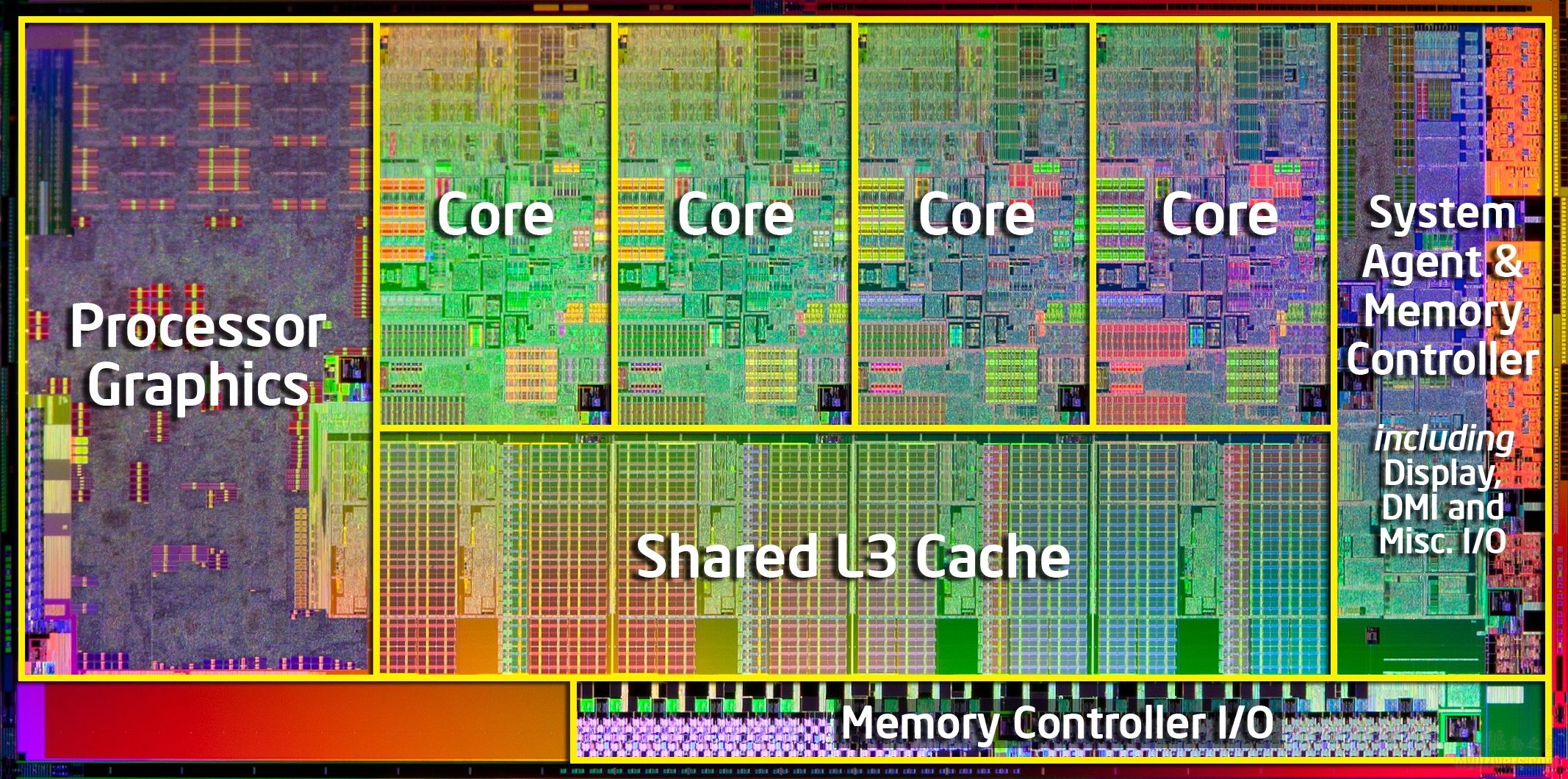
Snímek jádra Intel Sandy Bridge se sdílenou L3 cache spojenou s jádry a GPU pomocí sběrnice ring-bus; zdroj: Intel
Musíme si uvědomit, že starší generace (Nehalem, Westmere) byly vybaveny privátní sběrnicí spojující každé x86 jádro s L3 cache a tato sběrnice znamenala tisícovku spojů mezi každým jádrem a zmíněnou cache. Jenže integrace dalších prvků do křemíku by znamenala potřebu dalších tisíců spojů, které by na danou dobu neúnosně zvyšovaly komplexnost a výrobní náklady. Intel se proto rozhodl implementovat ring-bus, prstencovou sběrnici. Tím se naskytla možnost připojit grafické jádro na ring-bus stejně jako jádra procesorová a takto je spojit s L3 cache. Namísto samostatné cache pro CPU a samostatné cache pro GPU tak vznikla jedna společná.
Šlo však spíše o kompromis z hlediska výrobních nákladů, než že by tato SLC přinesla něco, co by bez ní nebylo možné. Proč: V první řadě bylo toto řešení koncipováno jako procesorová cache a z hlediska grafického jádra šlo o značně kompromisní řešení. Sběrnice ring-bus, která definovala rychlost spojení mezi grafickým jádrem a cache, byla z důvodu snahy o úsporu energie taktována podle procesorových jader (aby nespotřebovávala energii, když jsou procesorová jádra nevyužitá). Pokud tedy došlo na zátěž, kdy procesorová jádra neměla skoro co dělat, ale integrované GPU bylo vytížené, běžela sběrnice mezi GPU a L3 cache na nízké frekvenci a datové spojení mezi grafikou a cache bylo pomalé. Pokud byla procesorová jádra využitá, zase byla sběrnice vytížená jimi a navíc řízení spotřeby prioritizovalo CPU část, takže GPU mohlo být energeticky limitováno a nemělo příliš prostoru k rozletu.
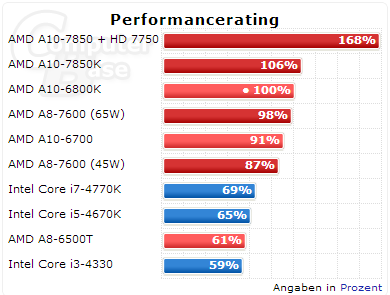
Dobový test iGPU Richland (A10-6800K) a Kaveri (A10-7850K); zdroj: ComputerBase
Výsledek byl ten, že integrované grafiky 32-28nm APU od AMD vybavené vlastní cache dosahovaly téměř dvojnásobného výkonu než integrované grafiky 22nm CPU Intelu se sdílenou L3 cache (SLC). Samozřejmě to nelze svalovat pouze na SLC, samotná cache byla jen jedním z důvodů této skutečnosti.
Popsaná situace ale dobře ilustruje fakt, že SLC sama o sobě nemusí uživateli přinášet něco klíčového. Nelze tedy předpokládat, že řešení postavené na SLC musí vždy dosahovat vyššího grafického výkonu než řešení bez SLC.
Intel L4 / eDRAM aneb první velká SLC v x86 desktopu
Éru odstartovanou procesory Sandy Bridge lze vnímat jako jednu ze snah Intelu výrazněji prorazit na poli grafických jader. V tomto případě integrovaných, ale GPU. Intel začal mezigeneračně výrazněji zvyšovat rozpočet tranzistorů na integrované grafické jádro, které zabíralo i přes polovinu plochy křemíku. Navzdory tomu však APU od AMD vyráběná zpravidla na starších procesech dosahovala o desítky procent až násobně) vyššího grafického výkonu.
Intel se proto (a možná i z jiných důvodů) rozhodl podpořit výkon použitím L4 cache postavené na bázi eDRAM. Ta byla opět koncipovaná způsobem, který bychom mohli považovat za SLC: Mohla ji využít grafická i procesorová jádra.

zdroj: Intel
Z hlediska implementace šlo o samostatný kousek křemíku umístěný v rámci pouzdra vedle hlavního křemíku s procesorovými a grafickými jádry. Komunikace tedy probíhala po sběrnici přes substrát pouzdra. Už to naznačuje, že samotná eDRAM nemohla být příliš rychlá, jinak by ji podobný způsob spojení musel omezovat. Křemík se 128 MB eDRAM dosahoval 77 mm². Na tyto údaje lze nahlížet dvěma způsoby: 128 MB za 77 mm² křemíku je výhodný obchod, je to (na plochu křemíku) levné, respektive podstatně levnější než jiné implementace cache v té době. Na druhé straně je nutné kriticky hodnotit, jaký reálný přínos těchto 77 mm² křemíku má a zda za to tento přínos stojí.
L4 na bázi eDRAM Intel využíval u vybraných produktů generací Haswell, Broadwell, Skylake a Coffee Lake. Haswell (2013) byl začátek, se Skylake už bylo cítit, že tudy cesta nevede a Coffee Lake už byla jen labutí píseň. Vrcholným bodem éry L4 / eDRAM Intelu se stal Broadwell. Tato generace měla několik specifik, která funkčně i marketingově přispěla k zacílení mediální pozornosti právě k integrované grafice a L4 cache. Patřil k nim přechod na 14nm proces (výrazný pokles spotřeby, který umožnil procesor a integrovanou grafiku tohoto výkonu vtěsnat do různých mini-PC), dále těžiště na BGA (procesory připájené k desce) a mimo jiné i fakt, že právě s Broadwell se Intelu podařilo (díky kombinaci opravdu velké integrované grafiky, 14nm procesu a 128MB eDRAM) poprvé o něco překonat výkon 28nm APU od AMD, tehdejší řady produktů postavené na jádru Kaveri.

Broadwell (světle modře) v okamžiku, kdy se Intelu podařilo poprvé a nakrátko překonat grafický výkon APU od AMD
zdroj: Anandtech
Druhou stranou mince však bylo, že šlo v podstatě o Pyrrhovo vítězství. Oproti tehdy mainstreamovému APU A8-7650K nabízel Broadwell s eDRAM o ~20 % vyšší herní výkon. 20 % by nebyl marný bonus, pokud by jmenované APU tehdy nebylo k dostání za částku pod $100 a Broadwell se neblížil $300. Téměř 2,5× horší poměr cena / výkon integrované grafiky při nepřesvědčivém výkonu procesorové části (IPC a eDRAM Broadwellu sotva vykompenzovala nižší takty oproti předchůdci Haswell-refresh alias Devil's Canyon). Komu šlo čistě o rychlou integrovanou grafiku, dostal podobný výkon s násobně levnějším APU od AMD (následně vydané zrychlené modely v kombinaci s dostupností rychlejších pamětí pak mírný náskok Broadwellu téměř vymazaly). Komu šlo o procesorový výkon, volil Haswell-refresh s lepším aplikačním výkonem i poměrem cena / výkon. Hráče využívající samostatnou grafiku mohl upoutat herní výkon, který byl u některých titulů s Broadwellem vyšší (díky eDRAM, paralela se současnou V-cache AMD), ale finančně vycházelo výhodněji vzít mainstreamový Haswell-refresh a ušetřené prostředky použít k nákupu o stupeň vyšší samostatné grafiky (než na jakou by zbylo s drahým Broadwellem). Výsledný herní výkon byl vyšší.
Proč L4 / eDRAM / SLC Broadwellu „nefungovala“? Z hlediska grafického výkonu může cache přinést výkonnostní bonus po splnění dvou podmínek: Za prvé musí být grafické jádro tak výkonné, aby bylo omezené stávající datovou propustností operačních pamětí. Vhodně koncipovaná cache toto omezení odstraní (nebo podstatně zmírní), což zpřístupní výkon navíc (výkon, který GPU již má, ale který byl bez cache omezen). Za druhé musí cache přinést podstatný nárůst paměťové propustnosti.
První podmínka byl zásadní problém. Integrované grafiky Intelu nebyly pomalé proto, že by byly limitované datovou propustností, ale proto, že samy o sobě nedosahovaly vysokého výkonu. SLC - ať už v podobě sdílené L3 nebo v podobě eDRAM (L4) - jim nemohla zásadně pomoci.
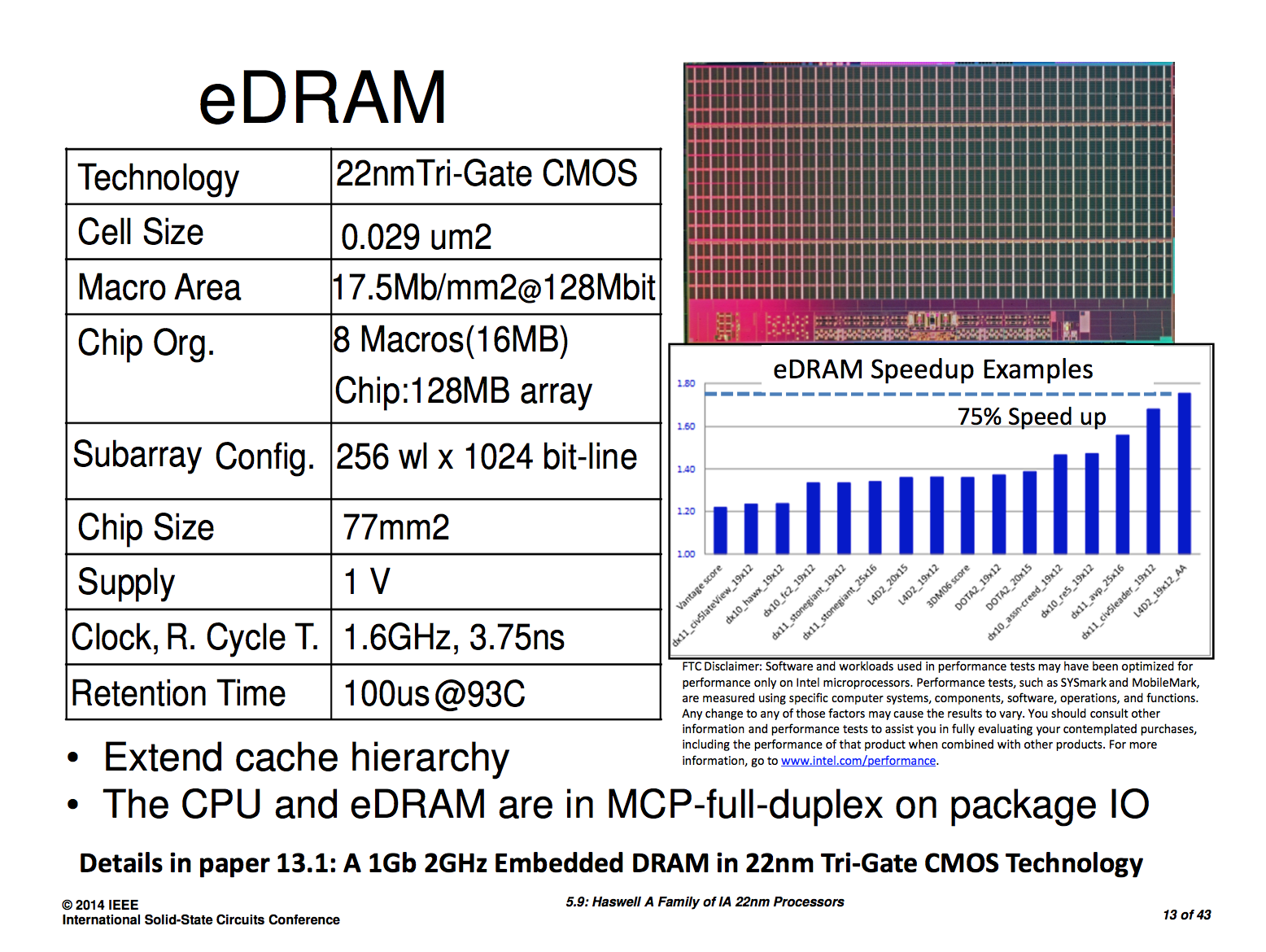
Navzdory tomu, že se před vydáním objevil slajd Intelu hovořící 75% zrychlení díky L4 cache, šlo o tzv. best-case, nejlepší situaci, kterou se Intelu podařilo zachytit. I ostatní čísla ale příliš neodpovídala pozdějším nezávislým měřením, kdy vypnutí L4 u řady her neznamenalo vyšší než 10-20 % propad výkonu.
Druhá podmínka rovněž nebyla splněna úplně předpisově. Paměti DDR3-1600 ve dvoukanálovém zapojení tehdy nabízely procesoru propustnost 25,6 GB/s. L4 cache v podobě eDRAM dosahovala propustnosti 50 GB/s, tedy s odřenýma ušima dvojnásobku. Již další generace, Skylake, přišla s podporou DDR4, které samy o sobě nabízely propustnost 51,6 GB/s, tedy více než eDRAM Broadwellu.
Tato cache nabízela 2× vyšší datovou propustnost než soudobé operační pamětí. Pro zajímavost si to můžeme srovnat s V-cache AMD (která by mohla být základem SLC příštích generací APU). Dvoukanálové DDR5-4800 dosahují 76,8 GB/s, V-cache překonává 2 TB/s, to máme ~27násobné navýšení datové propustnosti.
Ani latence eDRAM Intelu nebyly kdovíjaké terno - oproti L3 byly 3-6× vyšší, oproti latencím DDR3 pamětí jen o desítky procent nižší. Pokud z této SLC procesor nějakým způsobem těžil, bylo to především díky její vysoké kapacitě (128 MB).
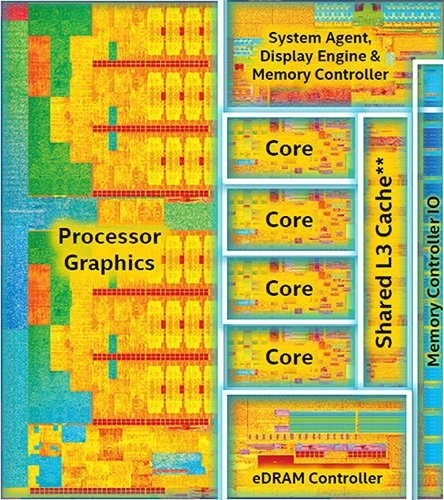
snímek jádra Broadwell; zdroj: Intel
Pokud bychom posuzovali, co v tomto případě SLC v podobě L4 implementované jako eDRAM stála, máme k dispozici následující údaje: Broadwell měřil 182 mm². eDRAM 77 mm². Jenže implementace eDRAM nestála jen těch 77 mm² samostatného křemíku, ale (jak je patrné ze snímku nad odstavcem), řadič eDRAM na hlavním jádru zabíral zhruba 10 % plochy samotného Broadwellu. To znamená, že samotný Broadwell stál pouze 164 mm² a eDRAM se vším všudy 95 mm². Zvýšení plochy o 58 % je s ohledem na pochybný přínos z dnešního pohledu docela masakr. Intel, který před tím i poté šetřil křemíkem, jak mohl, zkrátka v dané době neměl po stránce procesorového výkonu konkurenci, překonával pouze sám sebe, takže měl nevytížené výrobní linky a při tehdejších maržích se mu vyplatilo prodat cokoli, co na volných linkách mohl vyrobit. Bez ohledu na to, zda to dávalo smysl.
Paradoxně nejvyšší přínos eDRAM se odehrával na úrovni procesorového výkonu ve hrách (v kombinaci se samostatnou grafikou). Za éry Broadwellu to ale přílišný význam nemělo, herní výkon procesoru nebyl příliš limitující ani u tehdejších nejvýkonnějších GPU, limit ležel na grafice. Proto bylo výhodnější použít levnější Haswell-refresh a ušetřené prostředky přidat k penězům na nákup grafiky. Taková kombinace byla ve výsledku rychlejší.

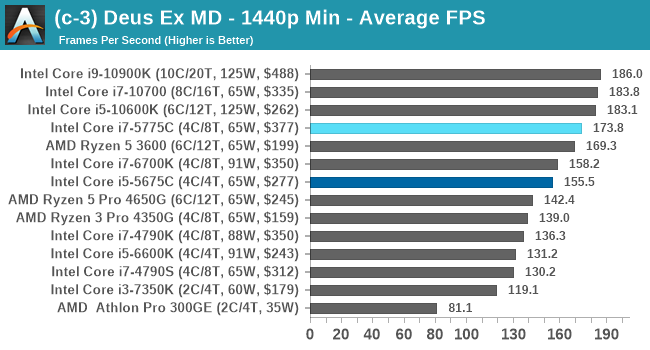
Novodobé herní testy Broadwellu se samostatnou grafikou; zdroj: Anandtech
Retrospektivní testy na současných grafických kartách ale ukazují, že Broadwell ve většině her překonává i novější procesory jako svého nástupce - Skylake a pozdější Zen 2 od AMD, výjimečně i novější generace. Kdo však reálně kombinuje procesor z roku 2015 se současným grafickým high-endem?
Lze tedy říct, že Intel byl v implementaci SLC v x86 desktopu pionýrem; v případě L3 cache však šlo z hlediska integrované grafiky o kompromisní řešení a v případě L4 cache (eDRAM) nebyl výkon iGPU takový, aby mu navýšení propustnosti ze strany cache mohlo výrazněji prospět (a zároveň tato cache nebyla podstatně rychlejší než operační paměti). Srovnatelného výkonu bylo možné dosáhnout s běžnými samostatnými integrovanými cache a to i s o generaci až dvě starším výrobním procesem (viz. 28nm APU vs. 14nm Broadwell).
Nedá se popřít, že Intel do x86 desktopu přinesl několik různých implementací paměti, které můžeme považovat za SLC cache. Není však možné tvrdit, že by tyto SLC přinesly nějakou revoluci, neboť co bylo dosaženo s nimi, bylo v dané době prokazatelně dosažitelné a většinou dosažené i bez nich.
Což je i důvodem, proč Intel s eDRAM nepokračoval a L3 prezentoval primárně jako procesorovou cache a ve specifikacích grafického jádra na ní neodkazoval, ani nezdůrazňoval nějaké výhody, které by přinášela.
V nadcházejících dvou letech uvidíme, zda AMD bude mít s implementací SLC víc štěstí. Tato společnost v desktopu dosud stavěla čistě na oddělených cache pro procesorovou i grafickou část. Protože vývoj operačních pamětí není tak rychlý, aby držel krok s výkonem integrovaných grafik, nabízela se možnost implementace Infinity Cache na úroveň APU. Protože však Infinity Cache vzešla z optimalizací L3 cache Zenu a je tedy svými parametry vhodná i pro procesorová jádra, nemá smysl ji zpřístupňovat pouze integrovanému GPU, když by z ní mohla profitovat i jádra procesoru. V dnešní době, kdy výkon samostatných grafických karet stoupá v násobcích, ale výkon procesorových jader roste jen v desítkách procent, je to navíc prakticky dobře uplatnitelné i ve hrách. Pokud se AMD rozhodne SLC na APU implementovat formou V-cache, bude to mít oproti historickému přístupu Intelu ještě jeden dosud nezmíněný bonus. V-cache a hlavní jádro jsou samy sobě rozhraním, takže odpadá křemík spotřebovaný na vytvoření rozhraní (oněch 18 mm² na straně Broadwellu a odpovídající „protikus“ na straně křemíku s eDRAM).
SLC má potenciál zpřístupnit vyšší grafický výkon SoC (využití cache grafickým jádrem) a na druhé straně zvýšit herní procesorový výkon při použití samostatné grafiky (využití cache procesorovým jádrem). V případě implementace navrstvením (V-cache) výhod přibývá: Je možné na bázi stejného návrhu nabízet produkty se SLC (pro vyšší cenový segment) a bez (pro nižší cenový segment) a neprodražovat produkty pro nižší cenový segment přítomností rozhraní v podobě nevyužitého křemíku.
| eDRAM | V-cache | rozdíl | |
|---|---|---|---|
| datová propustnost | 50 GB/s | >2 TB/s | ~40× |
| propustnost dobových DDR | 25,6 GB/s | 76,8 GB/s 102,4 GB/s | 3× 4× |
| propustnost cache oproti nim | ~2× | ~27× ~20× | ~13,5× ~10× |
| kapacita známých implementací | 128 MB | 64 MB | 0,5× |
| plocha vč. potřebných rozhraní | 95 mm² | 36 mm² | 0,38× |
| denzita cache vč. rozhraní | 1,35 MB/mm² | 1,78 MB/mm² | 1,32× |
| latence (cyklů) | <150 | ~30 | 0,2× |
Čím jsou si obě technologie navzdory dlouhému časovému odstupu blízké, je denzita. 7nm V-cache má jen o 32 % vyšší denzitu (kapacitu na plochu) než 22nm eDRAM. Důvodem je, že právě eDRAM je technologie maximálně zaměřená na denzitu. Skládá se z tzv. DTC (tj. Deep Trench Capacitor, hluboce zanořený kondenzátor), který má výrazně vertikální orientaci. Zasahuje tedy velmi hluboko do křemíku, ale horizontálně (plošně) zabírá minimum prostoru:

řez waferem s DTC; zdroj: IBM
Díky tomu mohl Intel již v roce 2013 s 22nm procesem nabídnout 128MB kapacitu. Nevýhodou oproti SRAM jsou pak podstatně vyšší latence a nižší datová propustnost. Očekává se, že i DTC se v éře vrstvení ještě vrátí ke slovu, ale nejspíš už ne v podobě eDRAM, ale např. pro snížení spotřeby:
Z hlediska SLC je však patrně DTC / eDRAM mrtvá technologie a většina nadcházejících řešení vznikne na bázi SRAM. Můžeme si připomenout i to, že v začátcích technologie HBM se uvažovalo i o tom, že by levnější varianty mohly být použity právě jako buffery pro x86 SoC (PC APU), ale cenová politika a vůbec celková strategie výrobců pamětí zamířila jinam, a tak se namísto HBM v tomto segmentu dočkáme vrstvených SRAM. Tzn. vyšší datové propustnosti, nižších latencí, ale také nižší kapacity.
- eDRAM - embedded Dynamic RAM, integrovaná dynamická paměť zaměřená na vysokou denzitu
- HBM - high-bandwidth memory - vrstvená paměť, v rámci DRAM vysoká propustnost
- LLC - Last Level Cache, cache poslední úrovně, zpravidla největší a nejpomalejší (L3, L4)
- SLC - System Level Cache, cache přístupná celému SoC (minimálně CPU a GPU jádrům)
- SoC - System on Chip, čip integrující většinu funkcí systému (procesor, grafika, čipset…)
- SRAM - Static RAM, velmi rychlá, oproti DRAM nevyžaduje obnovování, používaná pro cache






















