AMD mluví o Exascale APU budoucnosti, 7× vyšší energetická efektivita, 32 TFLOPS

Protože se požadavky na růst výpočetního výkonu neslučují s možnostmi současného vývoje výrobních procesů a klasických pamětí, rozhodla se AMD představit inovativní koncept, řešení…
S rostoucími objemy dat, rozvojem technologií a nástupem nových oborů rostou požadavky na výpočetní výkon. Vývoj systémů ale naráží na limity jako jsou možnosti výrobních procesů - maximální takty, maximální denzita, maximální velikost křemíkového jádra nebo výtěžnost - i limity dané možnostmi konvenčních pamětí. AMD si proto položila otázku, jak by měla vypadat základní stavební jednotka, na níž by byl založen systém dosahují výkonu exaflop v double-precision (1018). Pro zajímavost, první systém s výkonem jednoho petaflop (1015) byl představen roku 2008.
AMD si stanovila, že by daný systém měl být realizovatelný v letech 2022-2023 a z energetických důvodů disponovat poměrem výkon na watt 7× lepším než mají současné systémy. To by v praxi znamenalo mít blok o výkonu 10 TFLOPS DP se spotřebou pod 200 wattů. Požadavek na kapacitu paměti by dosahoval alespoň 1 TB na uzel. Zároveň počítala s nasazením technologií, které buďto existují v sériové podobě, nebo v podobě funkčních vzorků, nebo jsou ve vývoji.
Dosažení těchto požadavků není tak jednoduché, jak by se na první pohled mohlo zdát. Zmíněná energetická efektivita vyjádřená jako prvek o výkonu 10 TFLOPS DP do 200 wattů totiž neznamená např. existenci GPU, které dosáhne daného výkonnostního požadavku a bude mít nastaven TDP limit na 200 wattů - do tohoto limitu se musí vejít procesorová jádra, čipsety, paměti, chlazení i energetické ztráty zdrojů.
Exascale Heterogeneous Processor (EHP)
AMD proto jako základní výpočetní jednotku zvolila koncept nazvaný Exascale Heterogeneous Processor (EHP).

EHP: Uprostřed dva čtyřjádrové procesorové moduly, po jejich stranách celkem osm GPU, na nich HBM4
CPU a GPU bloky
Středobodem EHP by byly dva procesorové bloky, každý se čtyřmi jádry (mohly by podporovat SMT/HT). Nešlo by o klasické procesory integrující prvky čipsetu, paměťový řadič a další rozhraní; omezovaly by se téměř čistě jen na procesorová jádra a cache. Po obou stranách procesorových bloků by se rozkládaly bloky grafických jader. Celkem by jich bylo osm a každé by disponovalo 32 CU (tzn. 2048 stream-procesory) na 1 GHz (SP:DP 2:1). CPU i GPU bloky by byly umístěné na křemíkovém interposeru (podložce); nešlo by však o pasivní interposer, jaký je používán u současných grafických karet, kdy křemíková destička pouze zprostředkovává spoje. Použitý by byl aktivní interposer integrující logiku. Paměťový řadič, sběrnici spojující jednotlivé prvky, vstupní / výstupní obvody a podobně.
Samostatné kousky křemíku
Tento koncept by měl několik výhod. Samotné rozdělení CPU a GPU by znamenalo možnost využití odlišných výrobních procesů (nebo jejich variant). Zatímco pro GPU jsou výhodnější procesy s vyšší denzitou, CPU preferuje procesy optimalizované pro vyšší takty. Další výhodou oproti jednomu křemíkovému monolitu by byla výrazně vyšší výtěžnost souboru malých čipů oproti jednomu velkému. Odstranění řadičů a dalších obvodů z jednotlivých čipů by vedlo k jejich dalšímu zmenšení - pro jejich implementaci by byl využit křemík již přítomného interposeru.
Paměť, čtvrtá generace HBM vrstvená na GPU
S ohledem na malá GPU s konzervativními takty, která by generovala poměrně nízké množství odpadního tepla, by bylo možné využít novou generaci pamětí typu HBM, jejíž vrstvy by byl umístěné přímo na GPU. AMD se podrobně věnuje optimalizacím a konfiguracím, které by zajistily, aby teplota GPU nepřekročila 85 °C mezních pro HBM paměti.

Ilustrace různého zahřívání HBM vlivem GPU, na němž jsou navrstvené, při různých konfiguracích
Zvolená konfigurace kapacity a propustnosti vychází z předpokladu, že v letech 2022-2023 bude dostupná přinejmenším čtvrtá generace HBM (nyní se vyrábí druhá) a že po stránce datové propustnosti každého HBM čipy neporoste mezigeneračně na dvojnásobek (jako to bylo mezi první a druhou generací), ale na dvojnásobek přes další dvě generace. Věří ale, že zdvojnásobení kapacity s každou generací zůstane zachováno, takže by měly být k dispozici čipy o kapacitě 32 GB a rozhraní o propustnosti 4 Gb/s, což by při jednom čipu na každý GPU modul přineslo celkovou kapacitu 256 GB s propustností 4 TB/s.
Exascale Node Architecture (ENA)
Ačkoli by byla dosažena požadovaná datová propustnost, nebyla by dosažena potřebná kapacita (alespoň 1 TB na uzel); HBM by nabídly 4× méně. Řešením by byla architektura ENA. Každý blok EHP by byl umístěn na podložce (např. PCB), která by nesla další potřebnou paměť.

Tato paměť by se skládala z čipů či modulů vzájemně propojených (point to point, tedy odlišně než v případě topologie založené na sběrnici jako u DDR). AMD pro ilustraci uvádí, že tento koncept v současnosti využívá interní architektura pamětí typu HMC (Hybrid Memory Cube), kde jsou vrstvy jednotlivých čipů spojené rychlým sériovým rozhraním.
Pohled na celkové schéma systému: oranžově procesorová jádra (2× 4), tyrkysově grafické čipy (8× 2048 stream-procesorů), šedě aktivní interposer, zeleně HBM4 (256 GB), fialově paměti na ENA desce (1 TB)
Volba konkrétní architektury by závisela na požadavku zákazníka (využití daného výpočetního systému). Počítá se s DRAM i NVM včetně případného mixu obou typů o celkové kapacitě 1 TB.
Faktem je, že k realizaci celého systému by nebylo třeba nových technologií, počítá se se současnými nebo s jejich přirozeným vývojem. Řada prvků by proto byla vyrobitelná již nyní, takže v letech 2022-2023 patrně bude na ještě lepší úrovni. Otázkou je spíše to, zda tyto vize bude realizovatelná s ohledem na náklady na vývoj jednotlivých prvků. Drtivá většina stávajícího HPC hardwaru vychází z čipů vyvíjených pro desktop, protože je to tak finančně únosné. Gigant jako Intel si vyvíjí vlastní Xeon Phi a několik dalších, Nvidia si až s generací Pascal mohla dovolit vyvinout a vydat jeden čip, který nešel na herní trh, ale byl určen čistě pro výpočetní segment - GP100.
Zde se očekává vývoj grafického čipu, vývoj procesorového čipu a vývoj aktivního interposeru. Samozřejmě by šlo o prvky využívající již existující architekturu; na druhou stranu jde stále o návrhy, které by našly uplatnění jen v HPC sféře. Náklady na výrobu masek pro FinFET procesy jsou vysoké a bez jistoty zájmu ze strany zákazníka by šlo o poměrně riskantní projekt. Exascale APU by však nemuselo vstoupit na trh jako sériově vyráběný projekt; AMD by jej mohla nabízet prostřednictvím semi-custom divize jako produkt na míru, jehož výroba by byla spuštěna až na základě poptávky.

Závěrem se ještě můžeme vrátit ke zmínce o CPU a GPU architektuře. Je zřejmé, že čtyřjádrový procesor by byl tvořen CCX modulem některé z nadcházejících generací Zenu, patrně třetí 7nm generací. Pokud jde o grafickou architekturu, do let 2022-2023 roadmapa společnosti nesahá, ale pro období kolem roku 2019 počítá s architekturou Navi, která přinese nové paměti (patrně HBM3) a vyšší škálovatelnost.
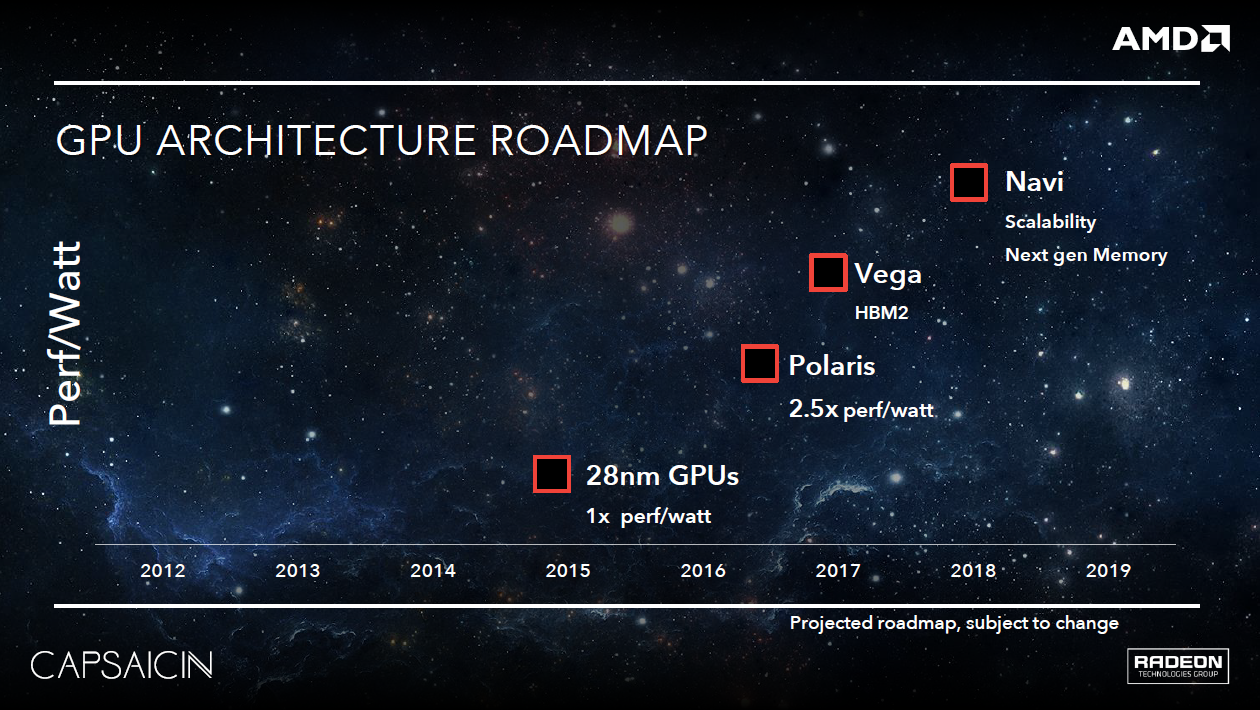
To je poměrně široký pojem; existují však spekulace, že by právě Navi mohla být prvním krokem k vývoji menších grafických čipů spojovaných rychlou sběrnicí - ať už realizovanou přes aktivní interposer, nebo jinak. K reálnému využití by patrně došlo a později, s dalšími generacemi.
Zdroje: