Unifikované jádro a řízení čipu

V kalendáři dnes máme 22. března, což znamená, že bychom se měli podívat na čerstvě uvedený grafický čip GK104. Těžko ho charakterizovat jednou větou - snad jen že asi bude jiný, než byste čekali…
Začneme od nejmenšího dílku skládačky - stream procesoru nebo (chcete-li) CUDA unit. Nvidia o samotných výpočetních jednotkách prakticky nemluvila, takže si vypůjčíme schéma z prezentace Fermi. Jednotlivé jednotky (detail vlevo) jsou totiž po funkční stránce totožné:

Fermi (GF100) SM a CUDA unit
Stejně jako u Fermi se tedy skládají z INT (celočíselné) a FP (desetinné) a nadále je doplňují samostatné SFU (special function units). Tahle informace byla jedním z největších překvapení architektury; všeobecně se předpokládalo, že Nvidia SFU vynechá a jejich funkcionalitu převede na základní výpočetní jednotky.

Fermi GF104 SM
Proč zmiňujeme funkční blok GF104 (GeForce GTX 460 / 560)? Zkrátka proto, že má konfiguraci nové GK104 výrazně blíž než původní Fermi / GF100. Především poměr výpočetních jednotek : SFU (6:1).
Nyní se ale vraťme ke schématu Kepleru. Ačkoli jsou samotné jednotky funkčně identické, jejich uspořádání se mírně změnilo:

Kepler GK104 SMX
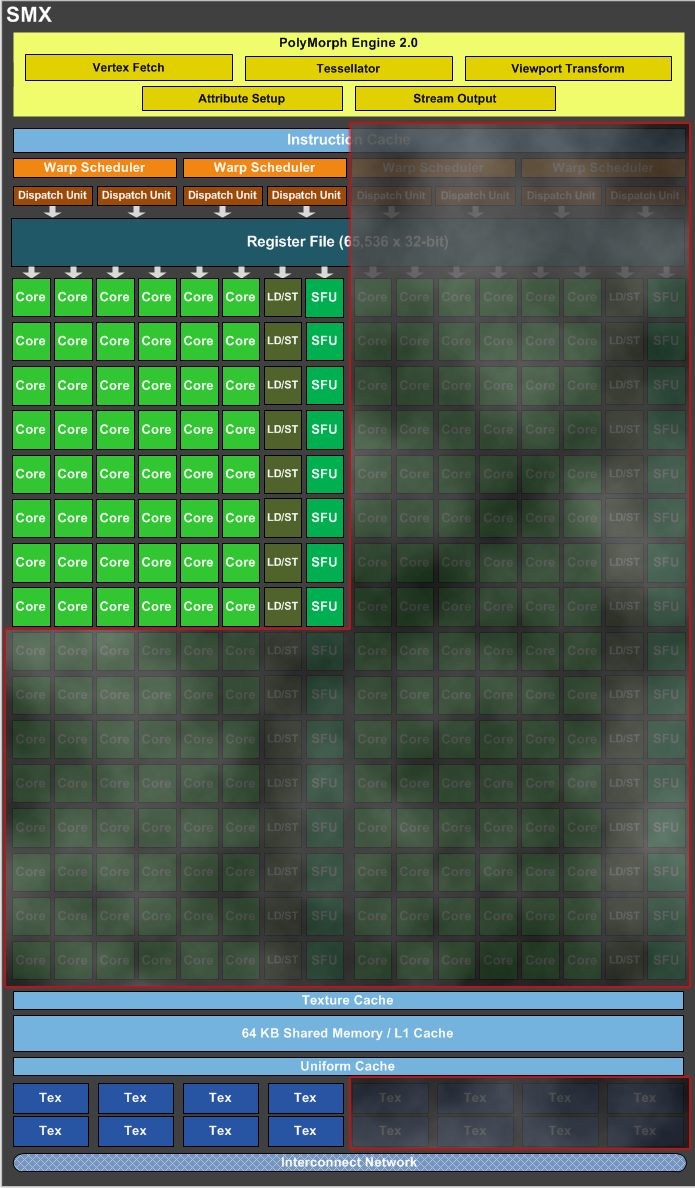
Nvidia již bloky funkčních jednotek nenazývá jako SM (stream-multiprocessor), ale zkratkou SMX. Jak si můžete všimnout, výpočetních jednotek („Core“) je v samotném bloku několikanásobně víc. Právě to je podstatou architektury Kepler, takže si zkusíme vysvětlit, jak toho Nvidia dosáhla.
Čipy architektury Fermi fungovaly tím způsobem, že jejich výpočetní jednotky běžely na 2× vyšší frekvenci než zbytek jádra. Tomu samozřejmě musel být uzpůsoben i zbytek čipu, především řízení činnosti samotných výpočetních jednotek (kam můžeme zahrnout hlavně scheduling a register file). Právě proto, že tyto části běžely oproti výpočetním jednotkám na poloviční frekvenci, musely nějakým způsobem frekvenční deficit kompenzovat. Konkrétně to bylo řešeno poměrně jednoduše: Řídící obvody byly nadimenzované pro 2× více výpočetních jednotek, než kolik jich čip ve skutečnosti nesl. Zjednodušeně řečeno: Řízení prostě nevidělo 2× rychleji taktovanou výpočetní jednotku, ale dvě fyzické výpočetní jednotky.
V čipu tedy řídící obvody zabíraly více místa, než by vzhledem k ploše zabrané samotnými výpočetními jednotkami bylo vhodné. Jedním z možných řešení tedy bylo namísto 2× rychleji taktovaných výpočetních jednotek použít 2× více (ale stejně taktovaných jader). Řídící obvody by to nijak nezvětšilo, protože už na takovou konfiguraci dimenzované jsou a nebylo by třeba řešit vysoké taktovací frekvence. Hot-clock tedy vypadl a ze 48 jednotek na dvojnásobné frekvenci vzniklo 96 jednotek na základní frekvenci. U toho ještě Nvidia neskončila, zbýval ještě jeden krok: Sloučení dvojice SM (s 96 SP) dalo vzniknout nové SMX se 192 SPs. Můžete si všimnout, že skutečně došlo ke zdvojnásobení všech částí, které souvisejí s aritmetikou a texturingem: Namísto dvou schedulerů nese každý SM(X) čtyři, zdvojnásobený byl i register-file a místo osmi texturovacích jednotek jich je zahrnuto šestnáct.
Čip GK104 se skládá z osmi výše popsaných SMX bloků, což znamená přítomnost celkem 1536 stream-procesorů / CUDA units a 128 texturovacích jednotek. Závěrem této kapitolky jsme ještě připravili ilustrační srovnání rozdílů SM bloku čipu GF104 (Fermi) a SMX bloku čipu GK104 (Kepler). Co je v GK104 navíc oproti GF104, je ztmaveno:
Kepler GK104 SMX vs Fermi GF104 SM
Scheduling
Kromě zrušení hot-clocku, jehož důsledkem je možné stejně rozsáhlé řízení čipu použít pro dvojnásobné množství výpočetních jednotek, byl zjednodušen i samotný scheduling:

Nové řešení je výrazně elegantnější, chlíveček „scheduling info“ před „decoder“ indikuje (s nemalou pravděpodobností) jednoduchý hardwarový thread level scheduling, který využívá i architektura AMD GCN.
Zdroje:
Nvidia (prezentace v San Franciscu a oficiální materiály)
předchozí kapitola
následující kapitola