
Chce si Samsung s pomocí PIM ukrojit ze zisku výrobců čipů?

V únoru Samsung ohlásil tzv. HBM-PIM a nyní plánuje technologii PIM - Processing-In-Memory - rozšířit i do dalších segmentů trhu s pamětmi.
Myšlenku PIM představil Samsung začátkem roku, nedlouho po CES, a demonstroval ji ve spojení s pamětmi HBM, konkrétně HBM2 Aquabolt, jak společnost označuje čipy s nadstandardní (>2 Gb/s) přenosovou rychlostí. Idea spočívá ve faktu, že za standardních okolností se při mnoha kombinacích operací a dat spotřebuje značná část energetického rozpočtu (obecně) výpočetního systému na transport dat a nezanedbatelné množství výpočetního času může být tráveno čekáním na datové přesuny.
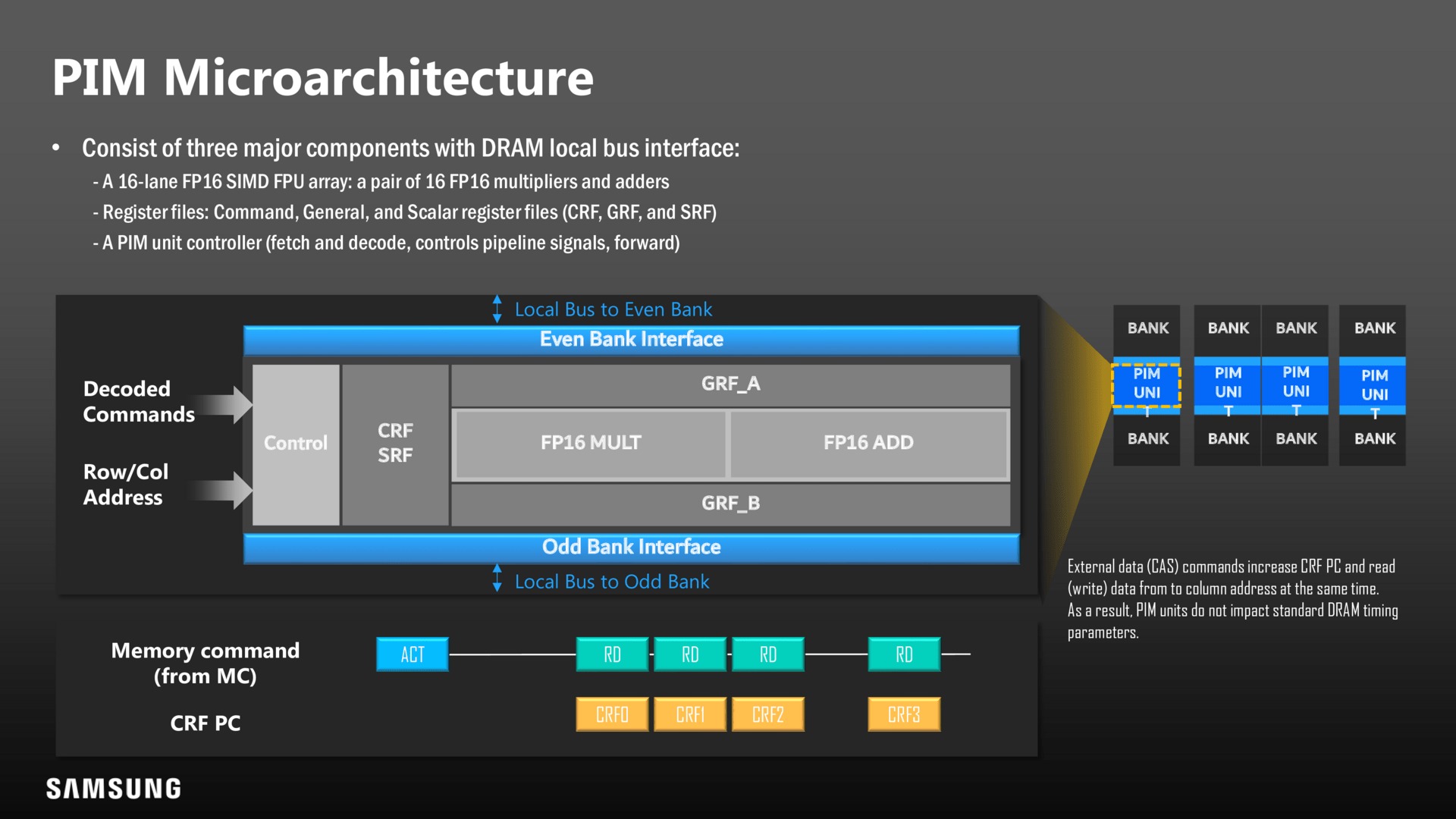

Samsung proto napadlo přímo na úroveň pamětí (čipů, modulů) integrovat jednoduchý akcelerátor, který by mohl některé operace provádět bez potřeby přesunu dat do akcelerátoru hlavního (CPU, GPU, FPGA, ASIC…). PIM akcelerátor využívá 32bit instrukce ve stylu RISC, kterých podporuje celkem 9, a které lze rozdělit do tří skupin: aritmetické (ADD, MUL, MAC, MAD), pro datové přesuny (MOV, FILL) a pro řízení datového toku (NOP, JUMP, EXIT).

První řešení (HBM-PIM) implementoval ve spolupráci se společností Xilinx do její akcelerační karty řady Xilinx Alveo AI a dosáhl tím (demonstrovány jsou jistě největší úspěchy) 2,54-2,85× zvýšení výkonu při poklesu energetických nároků o 62 %.
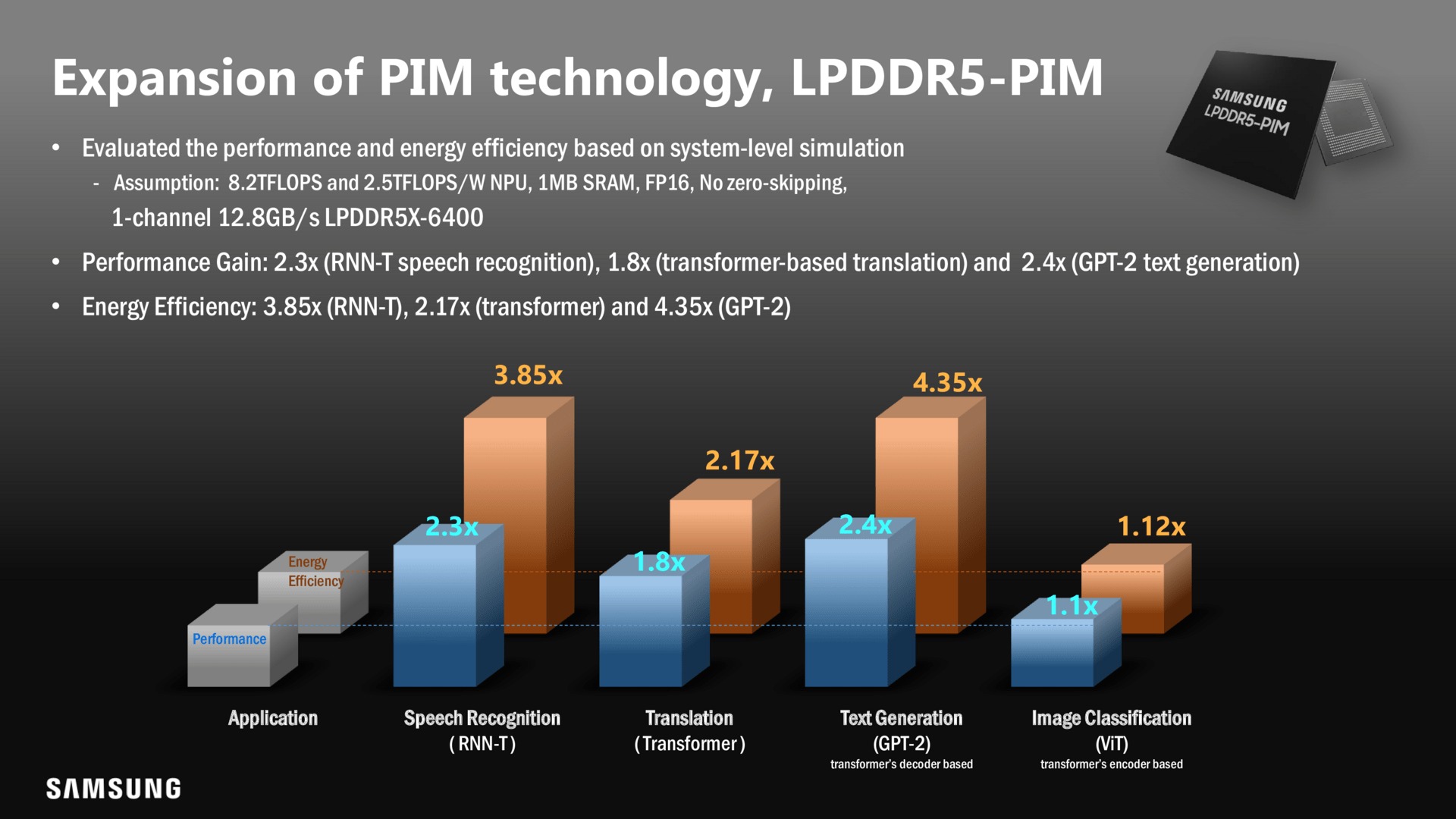
Samsung se nyní rozhodl ohlásit přípravu dalších produktů postavených na bázi PIM. Půjde o LPDDR5, DDR5, GDDR6 a HBM3. Zatímco u pamětí typu DDR počítá s podporou datových formátů INT8 a INT6, u HBM3 nabídne navíc i FP16 a FP32. V případě úsporných mobilních LPDDR5 dosahuje v cílových úlohách 1,1-2,4× vyššího výkonu a 1,12-4,35× nižší spotřeby, u velkých DIMM (serverové DDR5) však ilustroval o něco menší posun výkonu (1,8×) a o něco menší pokles spotřeby (o 42,6 %). Nelze nicméně opomíjet, že absolutní spotřeba klasických pamětí (DDR5 DIMM) je podstatně vyšší než spotřeba HBM či LPDDR5, takže i menší procentuelní pokles může znamenat podstatně vyšší úsporu v absolutních číslech.
Celou ideu PIM prezentuje Samsung jako snahu řešit situaci, kdy s ohledem na fyzikální limity a bariéry nelze v dohledné době očekávat nějaký zásadní skok v datové propustnosti pamětí a má tedy smysl implementovat takto nekonvenční řešení.
Na situaci však lze nahlížet i z jiného úhlu, kterého si je Samsung jistě vědom, jen nemá důvod jej prezentovat v tiskových zprávách. Vraťme se o několik let zpět do doby, kdy vrcholem vědy a techniky a byly GDDR5 a nic komerčně dostupného nabízejícího alespoň srovnatelné kapacity, nedosahovalo vyšší přenosové rychlosti. Výrobcům grafických čipů a akcelerátorů (AMD, Nvidia) však bylo už v době nástupu těchto pamětí jasné, že situace bude vyžadovat řešení podstatně vyšších datových přesunů, než jaké budou zvládat i nejpokročilejší GDDR5, a tak se obě společnosti daly do řešení problému. Každá trochu jiným způsobem. AMD šla cestou spolupráce s výrobci pamětí a vývoje nového standardu, což už se jí několikrát vyplatilo, zejména u GDDR3 a GDDR5. Nvidia naproti tomu začala klást větší důraz na snižování potřeby datových přesunů na úrovni architektury.

AMD Fiji (HBM)
Přístup Nvidie se ukázal být jako výhodnější, byť je na druhou stranu potřeba uznat, že přístup AMD byl negativně ovlivněn tehdejším vedením společnosti pod taktovkou Roryho Reada, který v několika vlnách vyházel desítky procent inženýrů a rovněž několikrát ořezal výdaje na vývoj a výzkum. Situace každopádně dopadla tak, že AMD nejdříve čekala na dokončení vývoje a nastartování výroby první generace HBM (GPU Fiji), což trvalo a nebylo levné (s čímž se však asi počítalo) a další generace (HBM2, GPU Vega), která měla ceny srazit, je příliš nesrazila. Zatímco ceny všech typů pamětí padaly, HBM2 zůstávaly drahé, neboť se výrobci pamětí rozhodli, že když nemohou vydělávat na ničem jiném, udělají z HBM high-end. Tak se ze zajímavé myšlenky a nástupce technologie GDDR stala záležitost pro drahé výpočetní akcelerátory.

AMD Vega 10 (HBM2)
Toto trpké čekání na vývoj cen HBM2 (provázené ztrátou konkurenceschopnosti) do stavu, ve kterém bude rentabilní vydat novou generaci na nich postavenou (mainstream s HBM2 nakonec AMD zrušila úplně, neboť by cenově nefungoval) se odrazilo ve filozofii dalšího architektonického vývoje. Odečteme-li si od vydání RDNA2 čtyři roky, což je obvyklá doba vývoje, dostáváme se přesně do doby, kdy se o architektuře Vega mluvilo, existovaly vzorky, ale sériová výroba stále neběžela. V té době lze hledat počátek myšlenky Infinity Cache, obrovské cache integrované do jádra, která zásadně sníží závislost čipu na použité paměťové technologii, čímž se eliminují rizika, která vedla ke zpoždění a nevalného úspěchu generace Vega.
Infinity Cache, alternativa k HBM nezávislá na výrobcích pamětí
Myšlenka fungovala a její ověření v praxi patrně dalo zelenou dalším projektům, které podobným způsobem snižují závislost na samostatných pamětech použitím velkých cache vlastní výroby - jedním takovým dalším je V-cache (rozšířená L3 cache), která si odbude premiéru na architektuře Zen 3 koncem letošního roku.
Vezmeme-li v úvahu, že velké značky mají informace o projektech a plánech konkurence i partnerských firem podstatně dříve než uživatelé a novináři, je zřejmé, že se přinejmenším rámcové údaje o těchto záměrech dostaly k Samsungu. Z pohledu výrobce pamětí totiž taková strategie na straně výrobce CPU / GPU nemůže být vnímána jinak, než snaha (částečně) vyšachovat výrobce pamětí ze svých produktů. Kupříkladu takový Samsung má na Radeonu RX 6900 XT osazeném doslova mainstreamovými GDDR6 podstatně menší vývar, než kdyby musel být osazen poslední generací nejrychlejším HBM2E. S Ryzeny s V-cache se zase AMD elegantně vyhýbá potřebě DDR5 v začátku jejich éry, kdy jsou dražší a jejich výroba finančně zajímavější.
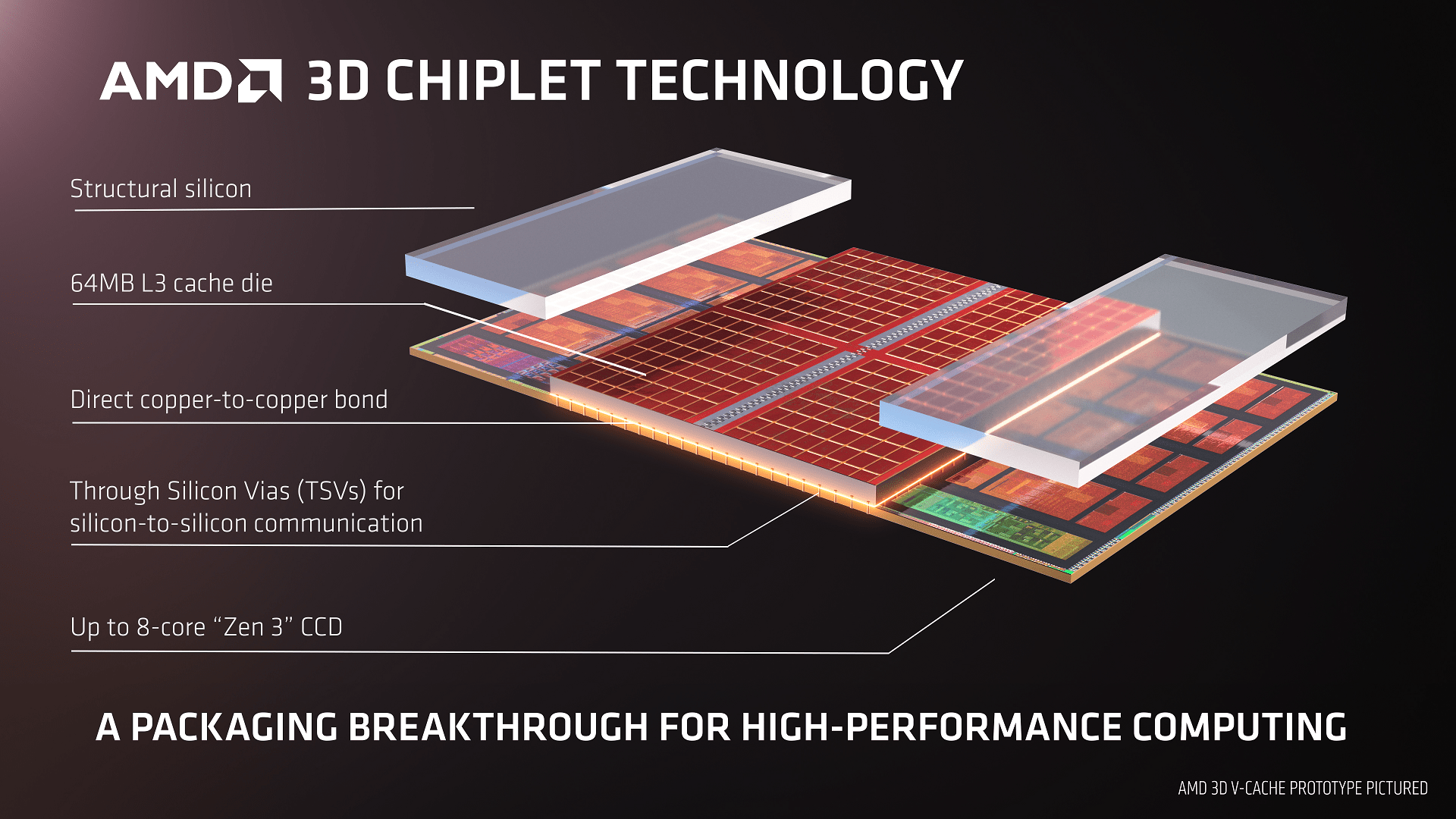
Ryzen s V-cache - vyšší efektivní datová propustnost bez potřeby DDR5
Na technologii PIM tak lze nahlížet jako na určitý protiúder - zatímco trendy ve vývoji CPU, GPU a dalších akcelerátorů směřují k výraznému snížení závislosti na nejrychlejších pamětech (což znamená méně příjmu do kapsy výrobce pamětí), PIM dělá totéž, ale v opačné směru: Snižuje závislost pamětí na čipu, ke kterému jsou připojeny a přesunutím části výpočetního výkonu na úroveň pamětí dává Samsungu prostor ukrojit si větší část z rozpočtu na celý akcelerátor. Výsledkem může být zajímavá technologicko-finanční přetahovaná.
Galerie ke článku













































